在Spark上通过BulkLoad快速将海量数据导入到Hbase
我们在《通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]》文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入数据到Hbase中的方法。这里将介绍两种方式:第一种使用Put普通的方法来倒数;第二种使用Bulk Load API。关于为啥需要使用Bulk Load本文就不介绍,更多的请参见《通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]》。
文章目录
使用org.apache.hadoop.hbase.client.Put来写数据
使用 org.apache.hadoop.hbase.client.Put 将数据一条一条写入Hbase中,但是和Bulk加载相比效率低下,仅仅作为对比。
import org.apache.spark._import org.apache.spark.rdd.NewHadoopRDDimport org.apache.hadoop.hbase.{HBaseConfiguration, HTableDescriptor}import org.apache.hadoop.hbase.client.HBaseAdminimport org.apache.hadoop.hbase.mapreduce.TableInputFormatimport org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.HColumnDescriptorimport org.apache.hadoop.hbase.util.Bytesimport org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.HTable; val conf = HBaseConfiguration.create()val tableName = "/iteblog"conf.set(TableInputFormat.INPUT_TABLE, tableName) val myTable = new HTable(conf, tableName);var p = new Put();p = new Put(new String("row999").getBytes());p.add("cf".getBytes(), "column_name".getBytes(), new String("value999").getBytes());myTable.put(p);myTable.flushCommits(); |
批量导数据到Hbase
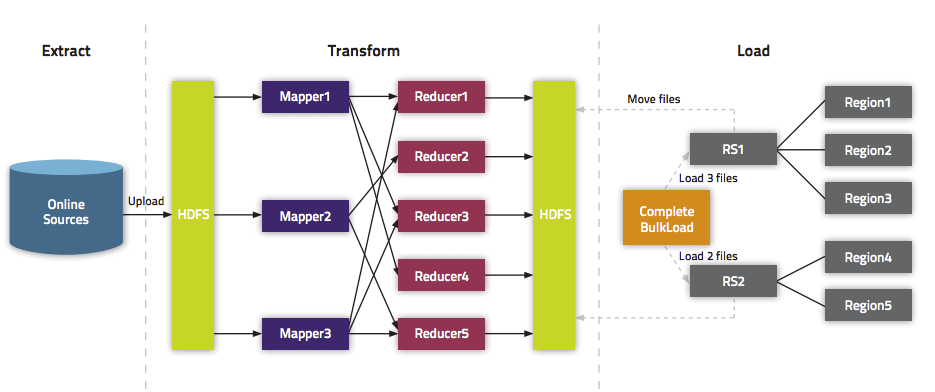
批量导数据到Hbase又可以分为两种:(1)、生成Hfiles,然后批量导数据;
(2)、直接将数据批量导入到Hbase中。
批量将Hfiles导入Hbase
现在我们来介绍如何批量将数据写入到Hbase中,主要分为两步:
(1)、先生成Hfiles;
(2)、使用 org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles 将事先生成Hfiles导入到Hbase中。
实现的代码如下:
import org.apache.spark._import org.apache.spark.rdd.NewHadoopRDDimport org.apache.hadoop.hbase.{HBaseConfiguration, HTableDescriptor}import org.apache.hadoop.hbase.client.HBaseAdminimport org.apache.hadoop.hbase.mapreduce.TableInputFormatimport org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.HColumnDescriptorimport org.apache.hadoop.hbase.util.Bytesimport org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.mapred.TableOutputFormatimport org.apache.hadoop.mapred.JobConfimport org.apache.hadoop.hbase.io.ImmutableBytesWritableimport org.apache.hadoop.mapreduce.Jobimport org.apache.hadoop.mapreduce.lib.input.FileInputFormatimport org.apache.hadoop.mapreduce.lib.output.FileOutputFormatimport org.apache.hadoop.hbase.KeyValueimport org.apache.hadoop.hbase.mapreduce.HFileOutputFormatimport org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles val conf = HBaseConfiguration.create()val tableName = "iteblog"val table = new HTable(conf, tableName) conf.set(TableOutputFormat.OUTPUT_TABLE, tableName)val job = Job.getInstance(conf)job.setMapOutputKeyClass (classOf[ImmutableBytesWritable])job.setMapOutputValueClass (classOf[KeyValue])HFileOutputFormat.configureIncrementalLoad (job, table) // Generate 10 sample data:val num = sc.parallelize(1 to 10)val rdd = num.map(x=>{ val kv: KeyValue = new KeyValue(Bytes.toBytes(x), "cf".getBytes(), "c1".getBytes(), "value_xxx".getBytes() ) (new ImmutableBytesWritable(Bytes.toBytes(x)), kv)}) // Save Hfiles on HDFS rdd.saveAsNewAPIHadoopFile("/tmp/iteblog", classOf[ImmutableBytesWritable], classOf[KeyValue], classOf[HFileOutputFormat], conf) //Bulk load Hfiles to Hbaseval bulkLoader = new LoadIncrementalHFiles(conf)bulkLoader.doBulkLoad(new Path("/tmp/iteblog"), table) |
运行完上面的代码之后,我们可以看到Hbase中的iteblog表已经生成了10条数据,如下:
hbase(main):020:0> scan 'iteblog'ROW COLUMN+CELL \x00\x00\x00\x01 column=cf:c1, timestamp=1425128075586, value=value_xxx \x00\x00\x00\x02 column=cf:c1, timestamp=1425128075586, value=value_xxx \x00\x00\x00\x03 column=cf:c1, timestamp=1425128075586, value=value_xxx \x00\x00\x00\x04 column=cf:c1, timestamp=1425128075586, value=value_xxx \x00\x00\x00\x05 column=cf:c1, timestamp=1425128075586, value=value_xxx \x00\x00\x00\x06 column=cf:c1, timestamp=1425128075675, value=value_xxx \x00\x00\x00\x07 column=cf:c1, timestamp=1425128075675, value=value_xxx \x00\x00\x00\x08 column=cf:c1, timestamp=1425128075675, value=value_xxx \x00\x00\x00\x09 column=cf:c1, timestamp=1425128075675, value=value_xxx \x00\x00\x00\x0A column=cf:c1, timestamp=1425128075675, value=value_xxx |
直接Bulk Load数据到Hbase
这种方法不需要事先在HDFS上生成Hfiles,而是直接将数据批量导入到Hbase中。与上面的例子相比只有微小的差别,具体如下:
将
rdd.saveAsNewAPIHadoopFile("/tmp/iteblog", classOf[ImmutableBytesWritable], classOf[KeyValue], classOf[HFileOutputFormat], conf) |
修改成:
rdd.saveAsNewAPIHadoopFile("/tmp/iteblog", classOf[ImmutableBytesWritable], classOf[KeyValue], classOf[HFileOutputFormat], job.getConfiguration()) |
完整的实现如下:
import org.apache.spark._import org.apache.spark.rdd.NewHadoopRDDimport org.apache.hadoop.hbase.{HBaseConfiguration, HTableDescriptor}import org.apache.hadoop.hbase.client.HBaseAdminimport org.apache.hadoop.hbase.mapreduce.TableInputFormatimport org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.HColumnDescriptorimport org.apache.hadoop.hbase.util.Bytesimport org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.mapred.TableOutputFormatimport org.apache.hadoop.mapred.JobConfimport org.apache.hadoop.hbase.io.ImmutableBytesWritableimport org.apache.hadoop.mapreduce.Jobimport org.apache.hadoop.mapreduce.lib.input.FileInputFormatimport org.apache.hadoop.mapreduce.lib.output.FileOutputFormatimport org.apache.hadoop.hbase.KeyValueimport org.apache.hadoop.hbase.mapreduce.HFileOutputFormatimport org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles val conf = HBaseConfiguration.create()val tableName = "iteblog"val table = new HTable(conf, tableName) conf.set(TableOutputFormat.OUTPUT_TABLE, tableName)val job = Job.getInstance(conf)job.setMapOutputKeyClass (classOf[ImmutableBytesWritable])job.setMapOutputValueClass (classOf[KeyValue])HFileOutputFormat.configureIncrementalLoad (job, table) // Generate 10 sample data:val num = sc.parallelize(1 to 10)val rdd = num.map(x=>{ val kv: KeyValue = new KeyValue(Bytes.toBytes(x), "cf".getBytes(), "c1".getBytes(), "value_xxx".getBytes() ) (new ImmutableBytesWritable(Bytes.toBytes(x)), kv)}) // Directly bulk load to Hbase/MapRDB tables.rdd.saveAsNewAPIHadoopFile("/tmp/iteblog", classOf[ImmutableBytesWritable], classOf[KeyValue], classOf[HFileOutputFormat], job.getConfiguration()) |
其他
在上面的例子中我们使用了 saveAsNewAPIHadoopFile API来将数据写到HBase中;事实上,我们还可以通过使用 saveAsNewAPIHadoopDataset API来实现同样的目标,我们仅仅需要将下面代码
rdd.saveAsNewAPIHadoopFile("/tmp/iteblog", classOf[ImmutableBytesWritable], classOf[KeyValue], classOf[HFileOutputFormat], job.getConfiguration()) |
修改成
job.getConfiguration.set("mapred.output.dir", "/tmp/iteblog")rdd.saveAsNewAPIHadoopDataset(job.getConfiguration) |
剩下的和和之前完全一致。
在Spark上通过BulkLoad快速将海量数据导入到Hbase的更多相关文章
- 通过BulkLoad快速将海量数据导入到Hbase
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据.我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等. 但是这些方式不是慢就是在导入的过程的占用Region ...
- 通过BulkLoad快速将海量数据导入到Hbase(TDH,kerberos认证)
一.概念 使用BlukLoad方式利用Hbase的数据信息是 按照特点格式存储在HDFS里的特性,直接在HDFS中生成持久化的Hfile数据格式文件,然后完成巨量数据快速入库的操作,配合MapRedu ...
- spark上的一些常用命令(一)
1. 加速跑 spark-sql --name uername --num-executors --driver-memory 8G --executor-memory 8G 2. 上传数据 建表 ) ...
- Spark,一种快速数据分析替代方案
原文出处:http://www.ibm.com/developerworks/library/os-spark/ Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同 ...
- Spark(火花)快速、通用的大数据处理引擎框架
一.什么是Spark(火花)? 是一种快速.通用处理大数据分析的框架引擎. 二.Spark的四大特性 1.快速:Spark内存上采用DAG(有向无环图)执行引擎非循环数据流和内存计算支持. 内存上比M ...
- Spark 安装部署与快速上手
Spark 介绍 核心概念 Spark 是 UC Berkeley AMP lab 开发的一个集群计算的框架,类似于 Hadoop,但有很多的区别. 最大的优化是让计算任务的中间结果可以存储在内存中, ...
- 协同过滤 CF & ALS 及在Spark上的实现
使用Spark进行ALS编程的例子可以看:http://www.cnblogs.com/charlesblc/p/6165201.html ALS:alternating least squares ...
- 如何在Win8.1和Win2012上运用PowerShell快速生成、安装、导出自签名证书 (Self-Signed Certificate)
自签名证书用途很广,测试,开发,本地或者云端网站(比如Microsoft Azure Web Site)都会使用到.本文会介绍一种在Win8.1和Win2012 R2上使用PowerShell快速生成 ...
- 在spark上构造随机森林模型过程的一点理解
这篇文章仅仅是为了帮助自己理解在分布式环境下是如何进行随机森林模型构建的,文章中记录的内容可能不太准确,仅仅是大致上的一个理解. 1.特征切分点统计 不管是连续取值型特征还是离散取值型特征,分裂树结点 ...
随机推荐
- P4173 残缺的字符串 fft
题意:给你两个字符串,问你第一个在第二个中出现过多少次,并输出位置,匹配时是模糊匹配*可和任意一个字符匹配 题解:fft加速字符串匹配; 假设上面的串是s,s长度为m,下面的串是p,p长度为n,先考虑 ...
- Java进阶资料汇总
Java经过将近20年的发展壮大,框架体系已经丰满俱全:从前端到后台到数据库,从智能终端到大数据都能看到Java的身影,个人感觉做后台进要求越来越高,越来越难. 为什么现在Java程序员越来越难做,一 ...
- hdu-5492-dp
Find a path Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total ...
- CF808D STL
D. Array Division time limit per test 2 seconds memory limit per test 256 megabytes input standard i ...
- Leetcode 77
//这似乎是排列组合的标准写法了已经class Solution { public: vector<vector<int>> combine(int n, int k) { v ...
- iOS UI-UIScrollView控件实现图片缩放功能
一.缩放 1.简单说明: 有些时候,我们可能要对某些内容进行手势缩放,如下图所示 UIScrollView不仅能滚动显示大量内容,还能对其内容进行缩放处理.也就是说,要完成缩放功能的话,只需要将需要缩 ...
- PHP:第三章——PHP中嵌套函数和条件函数
PHP中的嵌套函数: <?php header("Content-Type:text/html;charset=utf-8"); function A(){ echo &qu ...
- linux-网络使用
linux网络的基本使用 "ifconfig" 查看已经被激活的网卡详细信息 "ifconfig eth0" 查看特定的网卡信息 [root@ssgao ~]# ...
- C#中读写INI文件
INI文件就是扩展名为“ini”的文件.在Windows系统中,INI文件是很多,最重要的就是“System.ini”.“System32.ini”和“Win.ini”.该文件主要存放用户所做的选择以 ...
- Django(五)在模板中使用静态文件
location 最后一个文件夹名就是project名,我用了Django_Plan. Application 是自动加入的APP名字,我用了Plan 静态文件相关配置: Django_Plan\se ...