搭建GlusterFS文件系统
(1)环境准备
创建两个虚拟机配置如下
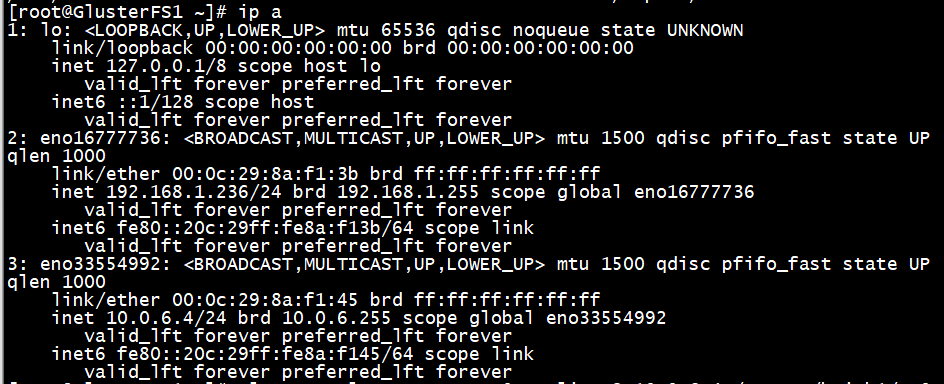
把仅主机第二张网卡配置如下:

GlusterFS1
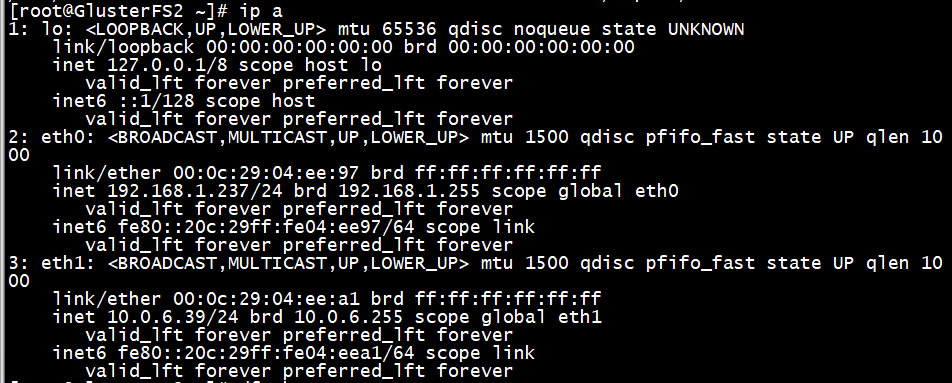
GlusterFS2
上传文件到opt目录下

文件内容如下
(2)GlusterFS安装配置
1、安装GlusterFS软件包。
配置YUM源
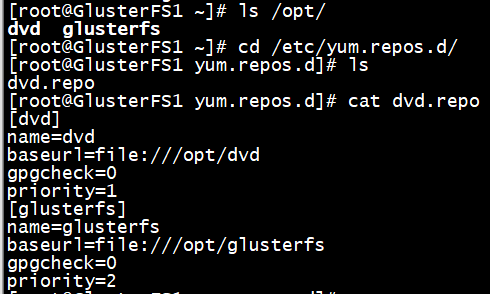
[dvd]
name=dvd
baseurl=file:///opt/dvd
gpgcheck=
priority=
[glusterfs]
name=glusterfs
baseurl=file:///opt/glusterfs
gpgcheck=
priority=
配置DNS服务。
# vi /etc/resolv.conf


在两个节点中安装GlusterFS需要的包。
# yum install -y glusterfs-server xfsprogs
安装完之后,启动服务并设置开机启动。

添加节点到GlusterFS集群。
[root@GlusterFS1 ~]# gluster peer probe 10.0.6.4
peer probe: success: on localhost not needed
[root@GlusterFS1 ~]# gluster peer probe 10.0.6.39
peer probe: success
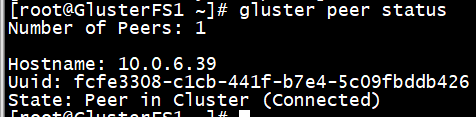
2、查询状态。
查看各个节点的状态。
# gluster peer status

3、创建目录。
创建数据存储目录(两个节点都要执行)。
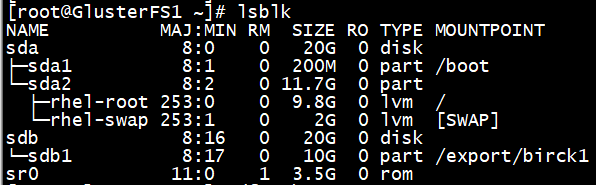
先使用fdisk分区工具将硬盘分出一个10 G的分区。然后使用lsblk命令查看。
# fdisk /dev/sdb
#lsblk

使用XFS文件系统对分区进行格式化。
# mkfs.xfs /dev/sdb1
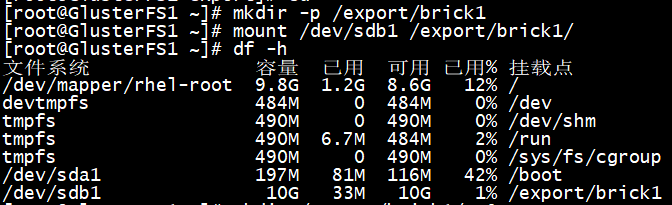
创建挂载目录并挂载查看
# mkdir -p /export/brick1
# mount /dev/sdb1 /export/brick1/
# df -h
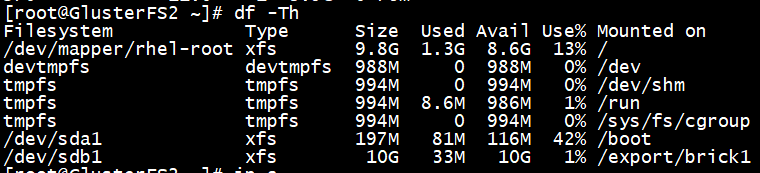
创建存储目录。
# mkdir /export/brick1/gv0
GlusterFS 2节点重复上述的操作,分区、格式化、挂载、创建存储目录。
4、创建磁盘卷。
创建GlusterFS磁盘卷。
创建系统卷gv 0(副本卷)。
# gluster volume create gv0 replica 2 10.0.6.4:/export/brick1/gv0 10.0.6.39:/export/brick1/gv0

启动系统卷gv 0。
# gluster volume start gv0

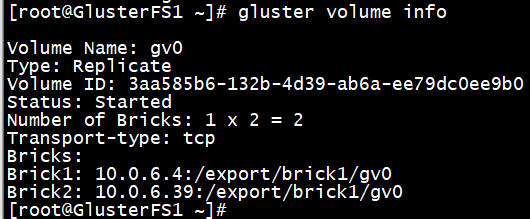
查看系统卷信息。
# gluster volume info
5、挂载文件系统。
安装客户端并挂载GlusterFS文件系统,使用GlusterFS 2节点作为客户端,在客户端挂载GlusterFS文件系统。
# mount -t glusterfs 10.0.6.4:/gv0 /mnt/
# df -h
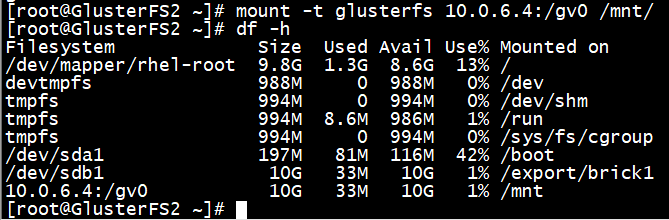
验证成功,副本卷gv 0的大小是10 G,因为GlusterFS的副本数为2,存储空间有一半冗余。
(3)运维操作
添加节点(将节点server ip添加到存储池中)。
# gluster peer probe server ip
删除节点。
# gluster peers detach server ip
注意:将节点server从存储池中移除,移除节点是要保证节点上没有Brick。如果节点上有Brick,需要提前移除Brick。
查看卷信息。
# gluster volume info
查看卷状态。
# gluster volume status
启动,停止卷。
# gluster volume start/stop VOLUME
删除卷。
# gluster volume delete VOLUME
修复卷。
# gluster volume heal mamm-volume #只修复有问题的文件
# gluster volume heal mamm-volume full #修复所有文件
# gluster volume heal mamm-volume info #查看自愈详情
(4)Brick管理
添加Brick。
# gluster peer probe 10.0.6.41
# gluster peer probe 10.0.6.42
# gluster volume add-brick gv0 10.0.6.41:/export/brick1/gv0 10.0.6.42:/export/brick1/gv0
注意:添加两个Brick到gv 0,副本卷则要一次添加的Bricks数是Replica的整数倍,Stripe同样要求。
移除Brick。
# gluster volume remove-brick gv0 10.0.6.41:/export/brick1/gv0 10.0.6.42:/export/brick1/gv0 start
注意:若是副本卷,则要移除的Brick是Replica的整数倍,Stripe具有同样的要求,副本卷要移除一对Brick,在执行移除操作时,数据会移到其他节点。
在执行移除操作后,可以使用status命令对task状态进行查看。
# gluster volume remove-brick gv0 10.0.6.41:/export/brick1/gv0 10.0.6.42:/export/brick1/gv0 status
使用commit命令执行Brick移除,则不会进行数据迁移而直接删除Brick,符合不需要数据迁移的用户需求。
# gluster volume remove-brick gv0 10.0.6.41:/export/brick1/gv010.0.6.42:/export/brick1/gv0 commit
搭建GlusterFS文件系统的更多相关文章
- centos7 搭建GlusterFS
centos7 搭建GlusterFS 转载http://zhaijunming5.blog.51cto.com/10668883/1704535 实验需求:4台机器安装GlusterFS组成一个集群 ...
- IPFS搭建分布式文件系统 - 访问控制
IPFS 一个内容可寻址.对等的超媒体分发协议. IPFS网络中的节点形成分布式文件系统. 为什么要用IPFS? “IPFS and the Blockchain are a perfect matc ...
- FastDFS搭建分布式文件系统
FastDFS搭建分布式文件系统 1. 什么是分布式文件系统 分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网 ...
- 实战:docker搭建FastDFS文件系统并集成SpringBoot
实战:docker搭建FastDFS文件系统并集成SpringBoot 前言 15年的时候,那时候云存储还远远没有现在使用的这么广泛,归根结底就是成本和安全问题,记得那时候我待的公司是做建站开发的,前 ...
- Ubuntu 搭建 GlusterFS 过程笔记
https://download.gluster.org/pub/gluster/ #要安装的东西 ---- ``` apt install -y build-essential gcc make c ...
- 【云计算】Ubuntu14.04 搭建GlusterFS集群
1.修改 /etc/hosts 所有服务节点执行(如果集群中没有DNS,可忽略此步骤): 10.5.25.37 glusterfs-1-5-25-3710.5.25.38 glusterfs-2-5- ...
- 使用buildroot搭建linux文件系统【转】
本文转载自:http://blog.csdn.net/metalseed/article/details/45423061 (文件系统搭建,强烈建议直接用buildroot,官网上有使用教程非常详细b ...
- 使用docker搭建FastDFS文件系统
1.首先下载FastDFS文件系统的docker镜像 docker search fastdfs 2.使用docker镜像构建tracker容器(跟踪服务器,起到调度的作用): docker run ...
- CentOS7 GlusterFS文件系统部署
一.GlusterFS简介 GlusterFS(GNU ClusterFile System)是一种全对称的开源分布式文件系统,所谓全对称是指GlusterFS采用弹性哈希算法,没有中心节点,所有节点 ...
随机推荐
- MyEclipse移动开发教程:迁移HTML5移动项目到PhoneGap(二)
MyEclipse开年钜惠 在线购买低至75折!立即开抢>> [MyEclipse最新版下载] 二.将文件从HTML5项目复制到PhoneGap项目中 1. 在HTML5 app项目的ww ...
- ZooKeeper 之 zkCli.sh客户端的命令使用
zkCli.sh的使用 ZooKeeper服务器简历客户端 ./zkCli.sh -timeout 0 -r -server ip:port ./zkCli.sh -timeout 5000 -ser ...
- Ansible之roles介绍
本节内容: 什么场景下会用roles? roles示例 一.什么场景下会用roles? 假如我们现在有3个被管理主机,第一个要配置成httpd,第二个要配置成php服务器,第三个要配置成MySQL服务 ...
- windows form参数传递过程
三.windows form参数传递过程 在Windows 程序设计中参数的传递,同样也是非常的重要的. 这里主要是通过带有参数的构造函数来实现的, 说明:Form1为主窗体,包含控件:文本框text ...
- 《利用Python进行数据分析》笔记---第6章数据加载、存储与文件格式
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- DBWR进程
--查询dbwr进程号 select pname,spid from v$process where pname like 'DBW%'; PNAME SPID----- -------------- ...
- .NET 中使用 TaskCompletionSource 作为线程同步互斥或异步操作的事件
你可以使用临界区(Critical Section).互斥量(Mutex).信号量(Semaphores)和事件(Event)来处理线程同步.然而,在编写一些异步处理函数,尤其是还有 async 和 ...
- node启动时候报错 Error: Cannot find module 'express'
cmd命令 到目录下,然后运行 npm install -d 再 node hello.js
- 【洛谷P1338】末日的传说
https://www.luogu.org/problemnew/show/P1338 [题目大意:从1到n的连续自然数,求其逆序对数为m的一个字母序最小的排列.] 最开始的思路是想从逆序对数入手,然 ...
- 网络流--最小费用最大流MCMF模板
标准大白书式模板 #include<stdio.h> //大概这么多头文件昂 #include<string.h> #include<vector> #includ ...