HashMap源码学习
HashMap就是将key做hash算法,然后将hash值映射到内存地址,直接取得key所对应的数据。
关于hash算法的原理知识在之前的博客中有讲到:哈希表之一初步原理了解。
在Java中的HashMap底层用的也是数组。这里的说法有问题,以前的API中HashMap底层是数组,但是JDK8之后如果元素超过了8个就开始使用红黑树了。
Java8对HashMap进行了一些修改,最大的不同就是利用了红黑树,所以其由"数组+链表+红黑树"组成。
根据Java7 HashMap的介绍,我们知道,查找的时候,根据hash值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。
为了降低这部分的开销,在Java8中,当链表中的元素超过了8个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
这里只针对JDK8中的HashMap进行分析。
hash(Object key)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里的key就是HashMap中存储的key。这个方法的描述如下:
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
key.hashCode()就是平常说的那个hashCode方法,如果重写了hashCode方法,那么就用重写了的,如果没有的话就用父类的hashCode方法。hashCode的实现要求高效和分散。
Java 中一般规定 Integer 类型占 32 位,Long 类型占 64位。
现在复习一下几个基本的位运算:
>>> :不带符号的右移,无论正数还是负数,高位都用 0 补齐。
>> :带符号的右移,正数高位用 0 补齐,负数高位用 1 补齐。
| :对应进行或运算,0 | 1 = 1,0 | 0 = 0
& :对应位进行与运算 ,0 & 0 = 0,1 & 0 = 0,1 & 1 = 1
^ :对应位进行异或运算(XOR),0 ^ 1 = 1,1 ^ 1 = 0,0 ^ 0 = 0
如果 key 为 null,那么 hashCode 就是 0 了。
如果 key 不为 null,则先计算 key 的 hashCode 为 h,让后将 h 异或 (h 不带符号的右移 16 的结果) 。
public static void main(String[] args) {
String hello = "hello";
// 求 hello 的 hashCode
int helloHashCode = hello.hashCode();
// hello hashCode 值得二进制字符串
String helloHashCodeBinaryString = Integer.toBinaryString(helloHashCode);
// 将 helloHashCode 不带符号右移 16 位
int rightShift16OfHelloHashCode = helloHashCode >>> 16;
// 获取右移之后的二进制字符串
String rightShift16String = Integer.toBinaryString(rightShift16OfHelloHashCode);
// 获取异或的值
int xorValue = helloHashCode ^ rightShift16OfHelloHashCode;
// 异或后的字符串
String xorBinaryString = Integer.toBinaryString(xorValue);
System.out.println("helloHashCode = " + helloHashCode);
System.out.println("xorValue = " + xorValue);
System.out.println("helloHashCodeBinaryString = " + helloHashCodeBinaryString);
System.out.println("rightShift16String = " + rightShift16String);
System.out.println("xorBinaryString = " + xorBinaryString);
}
执行后的结果为:
helloHashCode =
xorValue =
helloHashCodeBinaryString =
rightShift16String =
xorBinaryString =
分别补齐到 32 位,正数首位为 0,负数首位为 1。补齐之后的结果为:
helloHashCodeBinaryString = 00000
rightShift16String = 000000000000000000000
xorBinaryString = 00000
由此发现,算法的执行逻辑是没有问题的,你把 helloHashCodeBinaryString 和 rightShift16String 逐位异或一下就知道了。
再看看下 HashMap 计算 "hello" 的 hashCode 是否是 xorValue 的值呢。
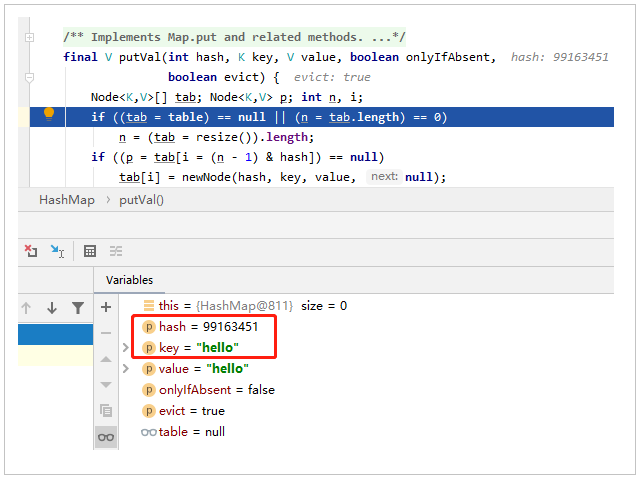
从图中可以发现,HashMap 算出来的 hash 确实和我们手工计算的结果一样。(用的同一个算法,能不一样么)
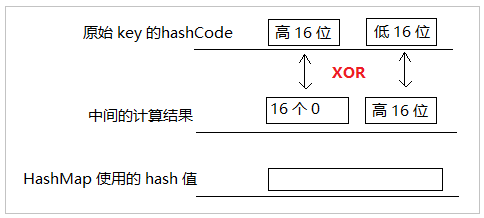
计算流程大概是这样的,为什么要这么搞,写 JDK 的那帮人觉得你是个二货,你的对象 hashCode 可能分布太不均匀了,导致性能问题,别个觉得要帮你兜底一下。

put方法分析
直接来看一下HashMap的put(key,value)方法的实现:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
给我的启发式,实现接口中的方法时,不要把实现都放在接口方法中,而是在接口方法中进行委托。在put方法中又调用了一个有5个参数的方法,顿时没有心情看了,因为不熟。
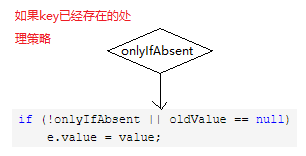
这里注意第4个参数用的是false,也就是如果插入相同的key,但是value不一样,则会替换掉原来的key对应的value值。
但是这个putVal方法才是精髓,还是一个final修饰的方法,它并不想被重写,说明是一个通用的方法。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
参数分析:
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
在putVal方法中的参数和返回值:
- hash:key的hash值
- key:key
- value:value
- onlyIfAbsent:如果为真的话,不会改变已经存在的值
- evict:如果evict为假,那么table是creation mode
- 返回值:这个key之前对应的值,如果没有previous value则是null
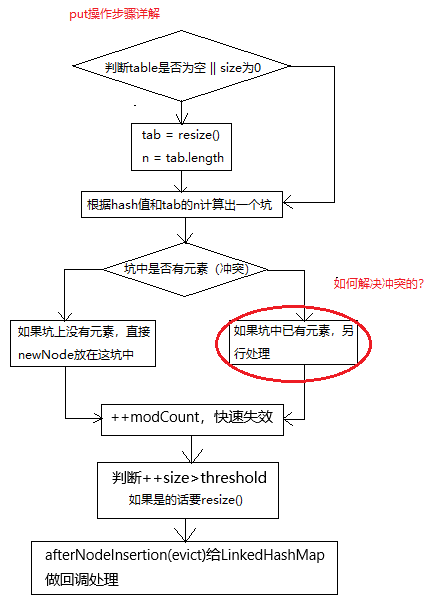
基本操作就是:
- 判断当前的hash表是否为空(null或者size为0)
- 如果是的话要resize,不是则前往下一步
- 根据key的hash值计算出在数组中应该是那个坑的位置
- 如果坑上没有元素,则直接把当前的元素插入进来
- 如果在坑上已经有元素了,就要解决冲突
- modCount++,用于快速失效
- 判断对size++,并且判断是否超过了阈值,如果超过了则要resize
- 调用给LinkedHashMap准备的回调函数
接下来看一下冲突部分是如何处理的(上圈红部分是如何处理的)
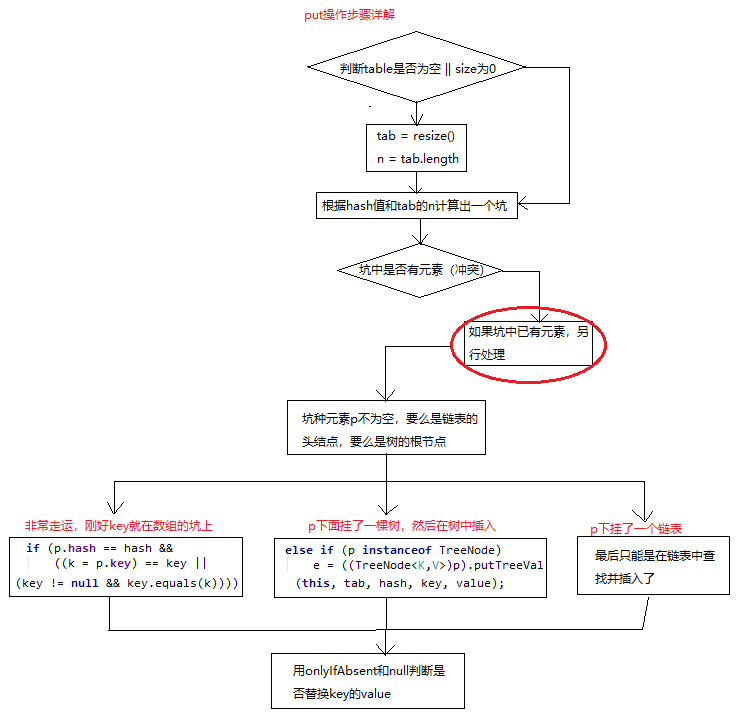
其实也挺简单的,就是判断一下p的属性,然后做不同的处理。可以分一下四种情况:
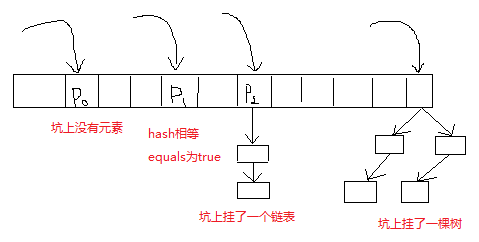
分析到这里还是先看一下源码中的实现笔记(Implement Note)
实现笔记
以下内容来自JDK8中源码注释的翻译。
这个map实际上是作为装箱的(分时段)的哈希表,但是当箱变得的非常大的时候,它们就会变成TreeNodes,在结构上类似于java.util.TreeMap。大多数的方法都会使用正常的bins,但是在合适的时候会依赖于TreeNode的方法。当过于聚集的时候使用TreeNode有利于提高查找性能。但是在正常使用的情况下大多数的bin都不会过于聚集,检测是否是tree的方法会延迟在table methods中进行。Tree bins(也就是它的元素都是TreeNodes)都是主要通过hashCode进行排序,如果两个元素都实现了Comparable接口,那么就是用它们自己的compareTo方法来排序。添加树带来的复杂性因为提供了最坏情况下O(log n)的性能而被认为是值的的。当hash的分不行很差的时候或者key都共用一个hashCode的时候,性能的降级还是挺优雅的。因为TreeNode的大小要比一般的节点大2倍,当bins中有足够多的元素的时候才会考虑使用它们。在hashCode的分布足够好的时候,tree bins几乎很少用的上。在随机hashCode的理想情况下,bins中节点的频率符合泊松分布。在threshold为0.75的时候,平均是0.5个,虽然因为resize的粒度会导致方差很大。在不考虑方差的情况下,list的size k符合: (exp(-0.5) * pow(0.5, k) / factorial(k))
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
tree bin的根节点自然是它的第一个节点了。然而,有时候(在Iterator remove操作),根节点可能是其他的元素,但还是可以通过TreeNode.root()找到。所有的内部方法都需要hash code作为参数,允许不需要重复计算hashcode来调用。大多数的内部方法同样也会接受tab参数,也就是当前的table,随着resizing或者converting,table会变新或者变旧。当bin lists被树化,分裂或者树退化,我们会保持它们相对的访问和遍历顺序Node.next,以更好的保存局部性。在plain和tree模式之间的转换通过现有的LinkedHashMap来实现的,比较很复杂。
HashMap中的参数
// 默认的初始容量是16, 必须是2的幂
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大的容量是2^30
static final int MAXIMUM_CAPACITY = 1 << 30;
// 构造方法中没有指定负载因子时默认的负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 超过多少个节点就会转为tree
static final int TREEIFY_THRESHOLD = 8;
// 在resize的时候少于多少个就会退化为list
static final int UNTREEIFY_THRESHOLD = 6;
// table中最少的容量是的bins转为tree, 为了避免resizing和树化阈的冲突,最少是4 * TREEIFY_THRESHOLD
static final int MIN_TREEIFY_CAPACITY = 64;
resize的实现分析
初始化和加倍table的size。如果为null的时候,分配的容量为初始容量。如果不是的话,通常会以2的幂来扩张,每个bin中的元素要么在同一索引中,要么以2的幂之差移到新的table中。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
看上去好像有点复杂,现在来逐行分析一下这个resize是怎么完成的。
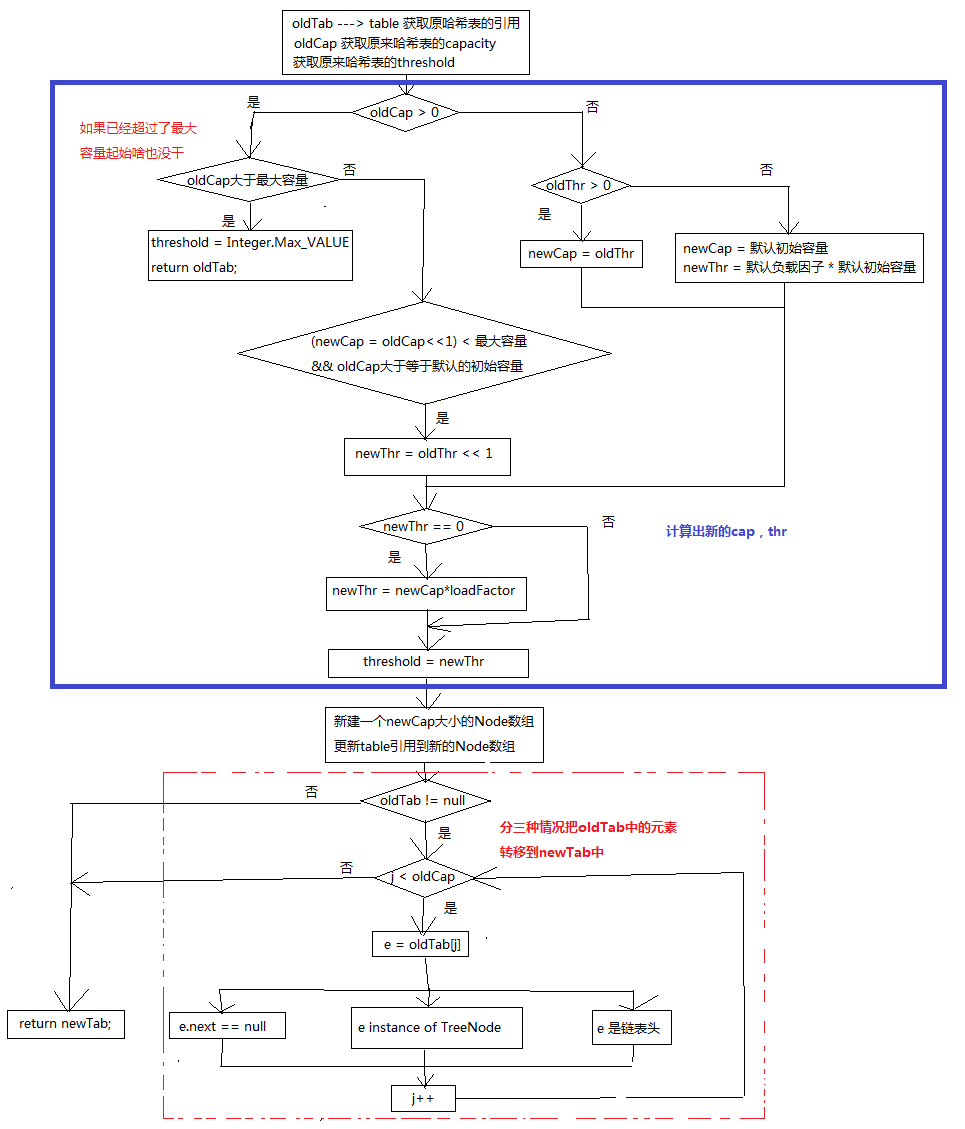
代码的思路还是很清楚的:
- 计算出新的容量cap和与之thr
- 以新容量创建数组并把原来哈希表中的元素转移大新的数组中
在元素转移的时候又分为三种情况:
- 数组坑中只有一个元素,元素的next为null,只需要重新计算新的坑位置
- 坑下挂了一棵树,这里调用的是TreeNode.split方法
- 坑下挂了一个链表
个人觉的这里还是要注意一下resize调用的时机,因为它是一个默认访问权限的方法,只有包访问权限,包外是不能调用的。源码中大部分的情况就是:
- tab为null
- size>threshold
这两种情况下会resize。
回头再来分析。。。
HashMap源码学习的更多相关文章
- hashMap源码学习记录
hashMap作为java开发面试最常考的一个题目之一,有必要花时间去阅读源码,了解底层实现原理. 首先,让我们看看hashMap这个类有哪些属性 // hashMap初始数组容量 static fi ...
- 基于jdk1.8的HashMap源码学习笔记
作为一种最为常用的容器,同时也是效率比较高的容器,HashMap当之无愧.所以自己这次jdk源码学习,就从HashMap开始吧,当然水平有限,有不正确的地方,欢迎指正,促进共同学习进步,就是喜欢程序员 ...
- 【jdk源码3】HashMap源码学习
可以毫不夸张的说,HashMap是容器类中用的最频繁的一个,而Java也对它进行优化,在jdk1.7及以前,当将相同Hash值的对象以key的身份放到HashMap中,HashMap的性能将由O(1) ...
- Java集合专题总结(1):HashMap 和 HashTable 源码学习和面试总结
2017年的秋招彻底结束了,感觉Java上面的最常见的集合相关的问题就是hash--系列和一些常用并发集合和队列,堆等结合算法一起考察,不完全统计,本人经历:先后百度.唯品会.58同城.新浪微博.趣分 ...
- 基于JDK1.8版本的hashmap源码笔记(二)
这一篇是接着上一篇写的, 上一篇的地址是:基于JDK1.8版本的hashmap源码分析(一) /** * 返回boolean类型的值,当集合中包含key的键值,就返回true,否则就返 ...
- 由JDK源码学习HashMap
HashMap基于hash表的Map接口实现,它实现了Map接口中的所有操作.HashMap允许存储null键和null值.这是它与Hashtable的区别之一(另外一个区别是Hashtable是线程 ...
- 集合框架源码学习之HashMap(JDK1.8)
目录: 0-1. 简介 0-2. 内部结构分析 0-2-1. JDK18之前 0-2-2. JDK18之后 0-3. LinkedList源码分析 0-3-1. 构造方法 0-3-2. put方法 0 ...
- JDK源码学习笔记——HashMap
Java集合的学习先理清数据结构: 一.属性 //哈希桶,存放链表. 长度是2的N次方,或者初始化时为0. transient Node<K,V>[] table; //最大容量 2的30 ...
- HashSet源码学习,基于HashMap实现
HashSet源码学习 一).Set集合的主要使用类 1). HashSet 基于对HashMap的封装 2). LinkedHashSet 基于对LinkedHashSet的封装 3). TreeS ...
随机推荐
- 机器学习---支持向量机(SVM)
非常久之前就学了SVM,总认为不就是找到中间那条线嘛,但有些地方模棱两可,真正编程的时候又是一团浆糊.參数任意试验,毫无章法.既然又又一次学到了这一章节,那就要把之前没有搞懂的地方都整明确,嗯~ 下面 ...
- Android Developers:保存文件
Android使用一个和其它平台基于硬盘文件系统相似的文件系统.这个课程描述了如何和在Android文件系统使用File APIs读和写文件. 一个File对象适用于读或者写从头到尾没用中断的大型数据 ...
- flowable学习笔记-简单流程概念介绍
1 Flowable process engine允许我们创建ProcessEngine 对象和使用 Flowable 的API ProcessEngine是线程安全的,他是通过 ProcessEng ...
- FIR基本型仿真_03
作者:桂. 时间:2018-02-05 20:50:54 链接:http://www.cnblogs.com/xingshansi/p/8419452.html 一.仿真思路 设计低通滤波器(5阶,6 ...
- MySQL 5.6学习笔记(运算符)
MySQL运算符包括四类:算术运算符.比较运算符.逻辑运算符和位运算符. 1. 算术运算符 用于种类数值运算.包括:加(+).减(-).乘(*).除(/).取余(%). 除法除数为零时,执行结果为nu ...
- Python无限元素列表实例教程
有关Python中无限元素列表的实现方法. 本文实例讲述了Python怎么实现无限元素列表的方法,具体实现可使用Yield来完成.下面所述的2段实例代码通过Python Yield 生成器实现了简单的 ...
- iOS-登录认证/json解析
用户输入用户名和密码,点击登录...我们把用户名和密码(用post方式或者get方式,get方式多用于测试看你需要)传给服务器,服务器进行判断,然后返回一个接口给我们(这里服务器返回的json接口,正 ...
- [na]tcp&udp扫描原理(nmap常用10条命令)
nmap软件使用思路及常见用法 Nmap高级用法与典型场景 namp -sn 4种包 使用nmap -sn 查询网段中关注主机或者整个网段的IP存活状态 nmap -sn nmap针对局域网和广域网( ...
- 文档 - STOMP Over WebSocket
http://jmesnil.net/stomp-websocket/doc/ What is STOMP? STOMP is a simple text-orientated messaging p ...
- 【Unity】11.2 刚体(Rigidbody)
分类:Unity.C#.VS2015 创建日期:2016-05-02 一.简介 Rigidbody(刚体)组件可使游戏对象在物理系统的控制下来运动,刚体可接受外力与扭矩力,使游戏对象像在真实世界中那样 ...