Python 之 解码汉字乱码(如果gbk、utf8都试过不行,可以试试这个)
起因:
使用 requests.get(url) 获取页面内容,并打印出来后显示如下:
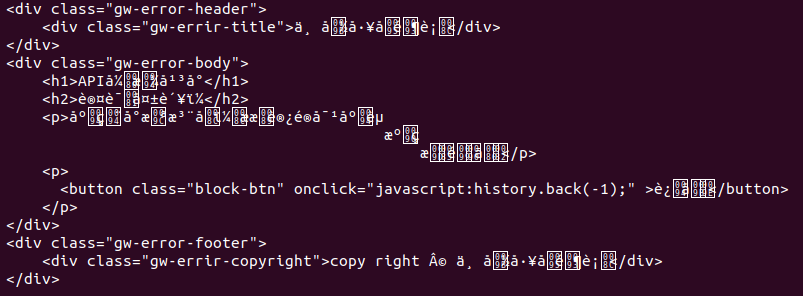
使用 type() 查看类型也是 <type 'unicode'>
print [content] 显示的也是像utf-8的样子:[u'<div class="gw-error-body">\n\t\t<h1>API\xe5\xbc\x80\xe6\x94\xbe\xe5\xb9\xb3\xe5\x8f\xb0</h1>\n\t\t<h2>\xe8\xae\xa4\xe8\xaf\x81\xe5\xa4\xb1\xe8\xb4\xa5\xef\xbc\x9a</h2>\n\t\t<p>\xe5\xba\x94\xe7\x94\xa8\xe5\xb0\x9a\xe6\x9c\xaa\xe6\xb3\xa8\xe5\x86\x8c\xef\xbc\x8c\xe6\x88\x96\xe6\x98\xaf\xe6\xb2\xa1\xe6\x9c\x89\xe8\xae\xbf\xe9\x97\xae\xe5\xaf\xb9\xe5\xba\x94\xe8\xb5\x84\xe6\xba\x90\xe7\x9a\x84\xe6\x9d\x83\xe9\x99\x90\xe3\x80\x82</p>\n\t\t<p>\n\t\t\t<button class="block-btn" onclick="javascript:history.back(-1);" >\xe8\xbf\x94\xe5\x9b\x9e</button>\n\t\t</p>\n\t</div>'],要注意开头的u,正常的utf-8是没有这个的。
也没有BOM头,utf-8,utf-16, utf8-sig,gbk试了个遍也没打印出中文,后来终于找到个解决办法。
解决办法I :----是个办法,但不是正规办法
原文:https://www.v2ex.com/t/304608
取到的网页文字内容在编码上存在一定的 trick ,简单来说就是 unicode 形式的 gbk 编码内容,形如: u'\xd6\xb0\xce\xbb\xc3\xe8\xca\xf6'
而事实上,这个字符串实际所要表达的 gbk 编码内容为
'\xd6\xb0\xce\xbb\xc3\xe8\xca\xf6',对应的汉字字符为“职位描述”
解这个问题可参见
http://stackoverflow.com/questions/14539807/convert-unicode-with-utf-8-string-as-content-to-str
可以看到,关键之处在于利用了以下这一特性:
Unicode codepoints U+0000 to U+00FF all map one-on-one with the latin-1 encoding
先将 unicode 字符串编码为 latin1 字符串,编码后保留了等价的字节流数据。
而此时在这个问题中,这一字节流数据又恰恰对应了 gbk 编码,因此对其进行解码即可还原最初的 unicode 字符。
不过值得注意的是,需要确定的是形如\xd6\xb0 究竟是 utf8 编码还是类似 gbk 类型的其他编码,
这一点对于最终正确还原 unicode 字符同样重要。
综上所述,对拿到的 content 执行以下操作即可:
content.encode("latin1").decode("gbk")
解决办法II :----正规办法
resp = requests.get('http://www.******')
print resp.encoding # ISO-8859-1
print resp.apparent_encoding # GB2312
resp.encoding = resp.apparent_encoding
content = resp.text
print content
原因:
原文:http://xiaorui.cc/2016/02/19/%E4%BB%A3%E7%A0%81%E5%88%86%E6%9E%90python-requests%E5%BA%93%E4%B8%AD%E6%96%87%E7%BC%96%E7%A0%81%E9%97%AE%E9%A2%98/requests会从服务器返回的响应头的 Content-Type 去获取字符集编码,如果content-type有charset字段那么requests才能正确识别编码,否则就使用默认的 ISO-8859-1. 一般那些不规范的页面往往有这样的问题。
所以,通过 resp.apparent_encoding 来查看本页面使用的编码(上例子中为GB2312),在明确了网页的字符集编码后可以使用 resp.encoding = 'GB2312' 获取正确结果。
完整代码:
# coding=utf-8
import requests resp = requests.get('http://www.******')
resp.encoding = resp.apparent_encoding
print resp.text # print resp.text.encode("latin1").decode("utf-8") # 这里的utf-8改成gbk就会报错,但有时候又情况相反,所以觉得这不是个正规办法
运行:

Python 之 解码汉字乱码(如果gbk、utf8都试过不行,可以试试这个)的更多相关文章
- 关于Python matplotlib显示汉字乱码问题
我也是一个初学者,在今天编程时遇到的一个问题,我是基于Eclipse编写Python代码,在使用matplotlib进行数据可视化时,发现显示不了汉字并且出现乱码问题. (1)使用中文注释时报错: 解 ...
- GBK,UTF-8,和ISO8859-1之间的编码与解码
Unicode.UTF-8 和 ISO8859-1到底有什么区别 将以"中文"两个字为例,经查表可以知道其GB2312编码是"d6d0 cec4",Unicod ...
- 【Java基础专题】编码与乱码(05)---GBK与UTF-8之间的转换
原文出自:http://www.blogjava.net/pengpenglin/archive/2010/02/22/313669.html 在很多论坛.网上经常有网友问" 为什么我使用 ...
- 编码与乱码(05)---GBK与UTF-8之间的转换--转载
原文地址:http://www.blogjava.net/pengpenglin/archive/2010/02/22/313669.html [GBK转UTF-8] 在很多论坛.网上经常有网友问“ ...
- CentOS7-安装后常见问题--ssh慢,汉字乱码gbk,-locale设置等
00.ssh 慢问题解决修改: [test@centos ~]$ sudo vi /etc/ssh/sshd_config /** 使用/命令查找 API 字符串*/ # GSSAPI option ...
- Eclipse 乱码解决方案(UTF8 -- GBK)
UTF8 --> GBK; GBK --> UTF8 eclipse的中文乱码问题,一般不外乎是由操作系统平台编码的不一致导致,如Linux中默认的中文字体编码问UTF8, 而Wind ...
- 解决EditPlus在设置了UTF-8之后,编写的HTML页面仍出现汉字乱码问题
解决EditPlus在设置了UTF-8之后.编写的HTML页面仍出现汉字乱码问题 相信有些同学在使用EditPlus编写HTML页面时发现,尽管已经设置好了UTF-8的编码格式.但却发现HTML页 ...
- C# unicode GBK UTF-8和汉字互转
界面: 源码: using System; using System.Collections.Generic; using System.ComponentModel; using System.Da ...
- 关于JAVA字符编码:Unicode,ISO-8859-1,GBK,UTF-8编码及相互转换
我们最初学习计算机的时候,都学过ASCII编码. 但是为了表示各种各样的语言,在计算机技术的发展过程中,逐渐出现了很多不同标准的编码格式, 重要的有Unicode.UTF.ISO-8859-1和中国人 ...
随机推荐
- git 代码冲突处理
在使用git pull代码时,经常会碰到有冲突的情况,提示如下信息: error: Your local changes to 'c/environ.c' would be overwritten b ...
- shell 清空指定大小的日志文件
#!/bin/bash # 当/var/log/syslog大于68B时 if ! [ -f /var/log/syslog ] then echo "file not exist!&quo ...
- Jmeter 分布式压力测试
JMeter中进行分布式测试 作为一个纯 JAVA 的GUI应用,JMeter对于CPU和内存的消耗还是很惊人的,所以当需要模拟数以千计的并发用户时,使用单台机器模拟所有的并发用户就有些力不从心, ...
- Codeforces 595B - Pasha and Phone
595B - Pasha and Phone 代码: #include<bits/stdc++.h> using namespace std; #define ll long long # ...
- Codeforces 447D - DZY Loves Modification
447D - DZY Loves Modification 思路:将行和列分开考虑.用优先队列,计算出行操作i次的幸福值r[i],再计算出列操作i次的幸福值c[i].然后将行取i次操作和列取k-i次操 ...
- python - HTMLTestRunner 测试报告模板设置
python - HTMLTestRunner 测试报告模板设置 优化模板下载地址: http://download.csdn.net/download/chinayyj2010/10039097 ...
- CF576E Painting Edges
首先,有一个很暴力的nk的做法,就是对每种颜色分别开棵lct来维护. 实际上,有复杂度与k无关的做法. 感觉和bzoj4025二分图那个题的区别就在于这个题是边dfs线段树边拆分区间.
- P4721 【模板】分治 FFT
其实是分治ntt,因为fft会爆精度,真*裸题 分治过程和fft的一模一样,主要就是ntt精度高,用原根来代替fft中的\(w_n^k\) 1.定义:设m>1,(a,m)==1,满足\(a^r= ...
- UVA-242 Stamps and Envelope Size (DP)
题目大意:给一些邮票的面值组合,找出在限定的张数范围内能组合出连续最大值得那个组合. 题目分析:状态可以这样定义:dp(k,u)表示u能否用k张邮票组合成.状态转移方程很显然了. 代码如下: # in ...
- CSS样式属性——字体+文本
CSS属性可分为以下几类:字体.背景.文本.位置.布局.边缘.列表 1. 字体——主要包括文字的字体.大小.颜色.显示效果等基本样式 font-family:用于设置字体系列 font-size:字体 ...