storm介绍,核心组件,编程模型
一、流式计算概念
利用分布式的思想和方法,对海量“流”式数据进行实时处理,源自业务对海量数据,在“时效”的价值上的挖掘诉求,随着大数据场景应用场景的增长,对流式计算的需求愈发增多,流式计算的一般架构图如下:

Flume获取数据-->Kafka传递数据-->Strom计算数据-->Redis保存数据
二、storm介绍
Apache Storm是一个分布式实时大数据处理系统。Storm设计用于在容错和水平可扩展方法中处理大量数据。它是一个流数据框架,具有最高的摄取率。Storm是无状态的,它通过Apache ZooKeeper管理分布式环境和集群状态。它很简单,您可以并行地对实时数据执行各种操作,成为实时数据分析的领导者。
通俗的说,Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。提供简单容易理解的接口,便于开发。
三、storm应用场景和典型案例
应用场景:
(1)监控日志分析:从海量日志中分析出特定的数据,并将分析的结果用来辅佐决策,或存入外部存储器。
(2)用户行为:实时分析用户的行为日志,将最新的用户属性反馈给搜索引擎,能够为用户展现最贴近其当前需求的结果。
(3)用户画像:收集,维护用户兴趣,并在此基础上向对应受众的用户投放不同的数据和信息。
典型案例:
(1)广告投放:为了更加精准投放广告,后台计算引擎需要维护每个用户的兴趣点(理想状态是,你对什么感兴趣,就向你投放哪类广告)。用户兴趣主要基于用户的历史行为、用户的实时查询、用户的实时点击、用户的地理信息而得,其中实时查询、实时点击等用户行为都是实时数据。考虑到系统的实时性,许多厂商使用Storm维护用户兴趣数据,并在此基础上进行受众定向的广告投放
(2)淘宝:实时分析用户行为,将用户搜索的宝贝反馈给搜索引擎,通过实时数据分析,为用户展现最贴近其当前需求的结果,或是卖家在后台看到自己的店铺有巨大的用户访问量,但实际买单却很少,则可以借助此数据分析进行一定的打折促销活动。
(3)大型系统监控:收集和分析系统运行过程中的各指标和产生的日志,进行实时分析处理,并作出下一步的决策或告警。
四、storm核心组件
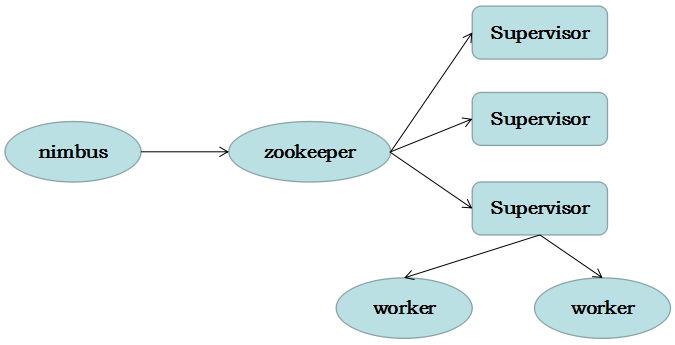
(1)Nimbus:负责资源分配和任务调度。
(2)Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。---通过配置文件设置当前supervisor上启动多少个worker。
(3)Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
(4)Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
五、storm编程模型及Stream Grouping
下面讲述storm的编程模型,同时也是worker的工作流程
Topology:Storm中运行的一个实时应用程序的名称。
Spout:在一个topology中获取源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple,一个Tuple单元会包含一个list对象。
Stream:表示数据的流向。
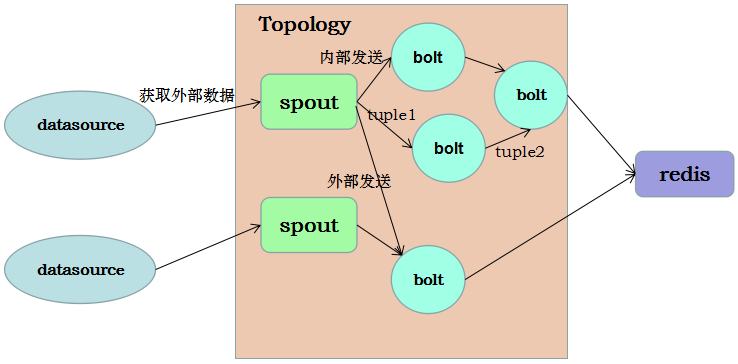
可以注意到,一个spout可以向内部的bolt发送数据,也可以向外部的bolt发送,这里即产生一个数据流向的策略问题,Storm里面有7种类型的stream流向策略Stream Grouping
(1)Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
(2)Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
(3)All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
(4)Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
(5)Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
(6)Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id(OutputCollector.emit方法也会返回task的id)。
(7)Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
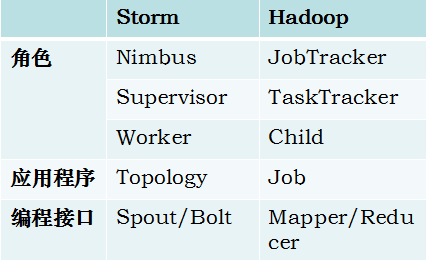
六、storm和Hadoop的核心组件对比
storm介绍,核心组件,编程模型的更多相关文章
- storm的trident编程模型
storm的基本概念别人总结的, https://blog.csdn.net/pickinfo/article/details/50488226 编程模型最关键最难就是实现局部聚合的业务逻辑聚合类实现 ...
- Storm架构和编程模型总结
1. 编程模型 DataSource:外部数据源 Spout:接受外部数据源的组件,将外部数据源转化成Storm内部的数据,以Tuple为基本的传输单元下发给Bolt Bolt:接受Spout发送的数 ...
- flink原理介绍-数据流编程模型v1.4
数据流编程模型 抽象级别 程序和数据流 并行数据流 窗口 时间 有状态操作 检查点(checkpoint)容错 批量流处理 下一步 抽象级别 flink针对 流式/批处理 应用提供了不同的抽象级别. ...
- Storm集成Kafka编程模型
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3974417.html 本文主要介绍如何在Storm编程实现与Kafka的集成 一.实现模型 数据流程: ...
- Storm 第一章 核心组件及编程模型
1 流式计算 流式计算:数据实时产生.实时传输.实时计算.实时展示 代表技术:Flume实时获取数据.Kafka/metaq实时数据存储.Storm/JStorm实时数据计算.Redis实时结果缓存. ...
- CUDA-F-2-1-CUDA编程模型概述2
Abstract: 本文继续上文介绍CUDA编程模型关于核函数以及错误处理部分 Keywords: CUDA核函数,CUDA错误处理 开篇废话 今天的废话就是人的性格一旦形成,那么就会成为最大的指向标 ...
- CUDA-F-2-0-CUDA编程模型概述1
Abstract: 本文介绍CUDA编程模型的简要结构,包括写一个简单的可执行的CUDA程序,一个正确的CUDA核函数,以及相应的调整设置内存,线程来正确的运行程序. Keywords: CUDA编程 ...
- Storm介绍及核心组件和编程模型
离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据.MapReduce批量计算数据.Hive批量计算数据.azkaba ...
- 第1节 storm编程:4、storm环境安装以及storm编程模型介绍
dataSource:数据源,生产数据的东西 spout:接收数据源过来的数据,然后将数据往下游发送 bolt:数据的处理逻辑单元.可以有很多个,基本上每个bolt都处理一部分工作,然后将数据继续往下 ...
随机推荐
- 解决Unknown error: Unable to build: the file dx.jar was not loaded from the SDK folder!
解决Unknown error: to the dx.jar the SDK folder!最近渐渐迁移到Android Studio来了,更新过Android SDK Manager里的东西后,打开 ...
- 使用virtualbox 配置 linux host-only虚拟主机连接外网(转载)
host-only 下的虚拟机之间可以互相访问,虚拟机和宿主机可以互相访问,但是虚拟机不能访问外网. 需要设置: 1.宿主机设置 先对宿主机(windows机器,我这里是win7系统)进行相关配置. ...
- sencha touch 在线实战培训 第一期 第八节 (完结)
2014.1.15晚上8点开的课 这是本期课程的最后一课,下期课程预计在春节后继续. 如果你有什么意见和建议可以将他们发送到邮箱:534502520@qq.com 本期培训一共八节,前三堂免费,后面的 ...
- sencha touch 在线实战培训 第一期 第四节
2014.1.4晚上8点开的课 第一节收费课程,还是有几位同学付费了,这些课程也录像了的,以后也会持续销售. 本期培训一共八节,前三堂免费,后面的课程需要付费才可以观看. 本节内容: ...
- HTTP协议详解(真的很经典)(转载)
HTTP协议详解(真的很经典):http://www.cnblogs.com/li0803/archive/2008/11/03/1324746.html 引言 HTTP是一个属于应用层的面向对象的协 ...
- 初学lua --lua嵌入c++的一个问题(初始化lua出错,版本问题)
初学lua.从http://lua-users.org/wiki/CallingLuaFromCpp上下载了一个lua嵌入C++的代码.编译并运行.发现有错误: PANIC: unprotected ...
- 【CQgame】[幸运方块 v1.1.3] [Lucky_Block v1.1.3]
搬家首发!!! 其实从初一我就写过一些小型战斗的游戏,但是画面都太粗糙,代码也比较乱,也就是和两三个同学瞎玩,但自从观摩了PoPoQQQ大神的游戏,顿时产生了重新写一部游戏的冲动,于是各种上网查找各种 ...
- Unity3D笔记 切水果三 切水果
一.创建一个Apple00,拖拽Prfabs下的Sprite命名为Apple00,添加碰撞器Box Collider,编写代码Knife Rey1.js 二.做被切的苹果 步骤和一是一样的,但是被切的 ...
- CentOS 6 安装python3.6
参考博客:https://www.cnblogs.com/xiaodangshan/p/7197563.html 安装过程比较简单,需要注意,安装之后,为了不影响系统自带的python2.6版本,需要 ...
- Spring Cloud Eureka 服务治理机制
服务提供者 服务提供者在启动的时候会通过发送REST请求的方式将自己注册到Eureka Server上,同时带上了自身服务的一些元数据信息.Eureka Server 接收到这个RE ...