基于注意力机制与改进TF-IDF的推荐算法
前言
本篇文章是2020年8月发表于《计算机工程》的一篇期刊论文,文章名称《基于注意力机制与改进TF-IDF的推荐算法》。
文章针对传统推荐系统主要依赖用户对物品的评分数据而无法学习到用户和项目的深层次特征的问题,提出基于注意力机制与改进TF-IDF的推荐算法(AMITI)。将双层注意力机制引入并行的神经网络推荐模型,提高了模型对重要特征的挖掘能力。
摘要
针对传统推荐系统主要依赖用户对物品的评分数据而无法学习到用户和项目的深层次特征的问题,提出基于注意力机制与改进TF-IDF的推荐算法(AMITI)。通过将双层注意力机制引入并行的神经网络推荐模型,提高模型对重要特征的挖掘能力。基于用户评分及项目类别改进TF-IDF,依据项目类别权重将推荐结果分类以构建不同类型的项目组并完成推荐。实验结果表明,AMITI算法能提高对文本中重要内容的关注度以及项目分配的注意力权重,有效提升推荐精度并在实现项目组推荐后改善推荐效果。
概述
本文提出一种基于注意力机制与改进TF-IDF的推荐算法AMITI。将注意力机制引入卷积神经网络(Convolutional Neural Network,CNN)中,在卷积层前加入注意力网络,对经过预处理的项目文本信息进行重新赋权。将多层全连接神经网络学习到的用户特征向量和项目特征向量输入到第2层注意力机制中,使多层感知机(Multilayer Perceptron,MLP)对注意力分数进行参数化。在完成推荐任务后,通过将用户评分和项目类别与TF-IDF结合,分析不同项目类型在推荐结果中的权重,获取用户对不同项目类型的偏好程度,并对推荐结果进行分类。
AMITI推荐算法
在NCF推荐模型的基础上将用户和项目的属性信息作为输入数据u:{u1,u2,...un},例如,用户ID、年龄、性别等;项目属性信息v:{v1,v2,...vn},例如,项目ID、类型、标题等。AMITI模型架构如图所示。
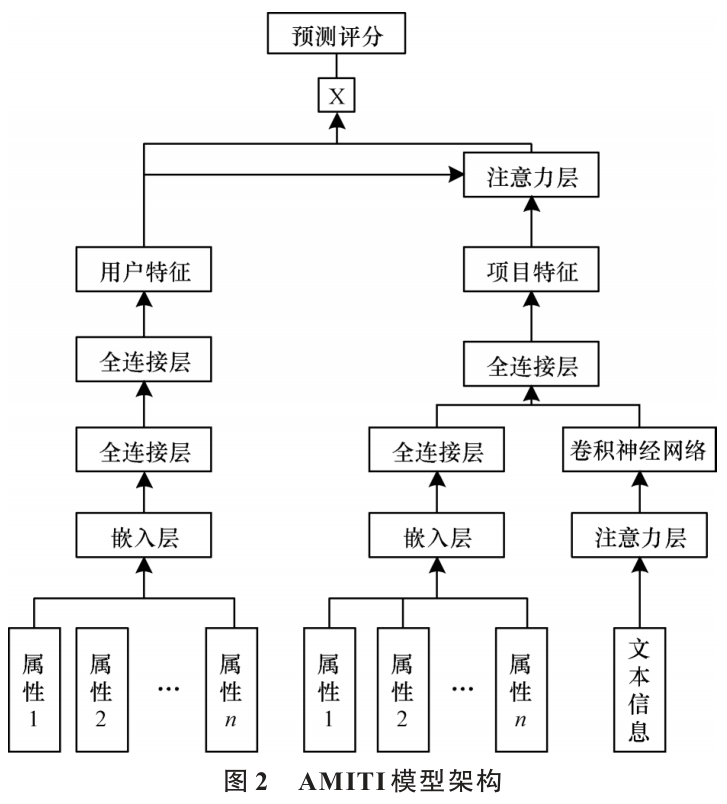
引入双层注意力机制,一层用于与CNN结合构建子网络,使CNN学习项目文本中的重点内容;另一层以用户及项目特征向量作为输入数据,利用注意力机制为用户历史交互项目分配个性化权重,得到不同项目对当前预测偏好所起的作用。将推荐结果分组,以项目组的形式向用户展示推荐结果,增强推荐内容的有序性。
学习用户和项目潜在特征
为改善推荐系统中数据稀疏的问题,利用用户和项目的属性信息进行评分预测。将用户及项目属性信息经过数据预处理后输入到嵌入层对属性信息进行编码,嵌入层将输入的稀疏向量映射为稠密的低维嵌入向量,得到用户和项目属性的嵌入表示pu和qv。在训练刚开始的时候,嵌入是简单的随机选择,随着训练的进行,每个嵌入的向量都会得到更新,以帮助神经网络执行其任务。将用户和项目的嵌入向量pu、qv输入到并行的多层全连接神经网络中,分别学习用户和项目非文本属性的潜在特征向量。
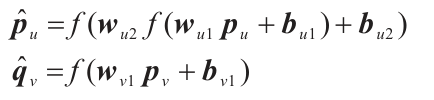
其中:f(×)为tanh激活函数;wn和bn分别为需要学习的权值矩阵和偏置。
引入注意力机制的卷积神经网络
对于项目属性的文本信息如项目标题,为了增强网络对文本中重点内容的学习能力,将注意力机制与CNN结合构成提取文本特征的子网络。文本卷积神经网络构成如图所示,由注意力层、卷积层、池化层、全连接层组成。
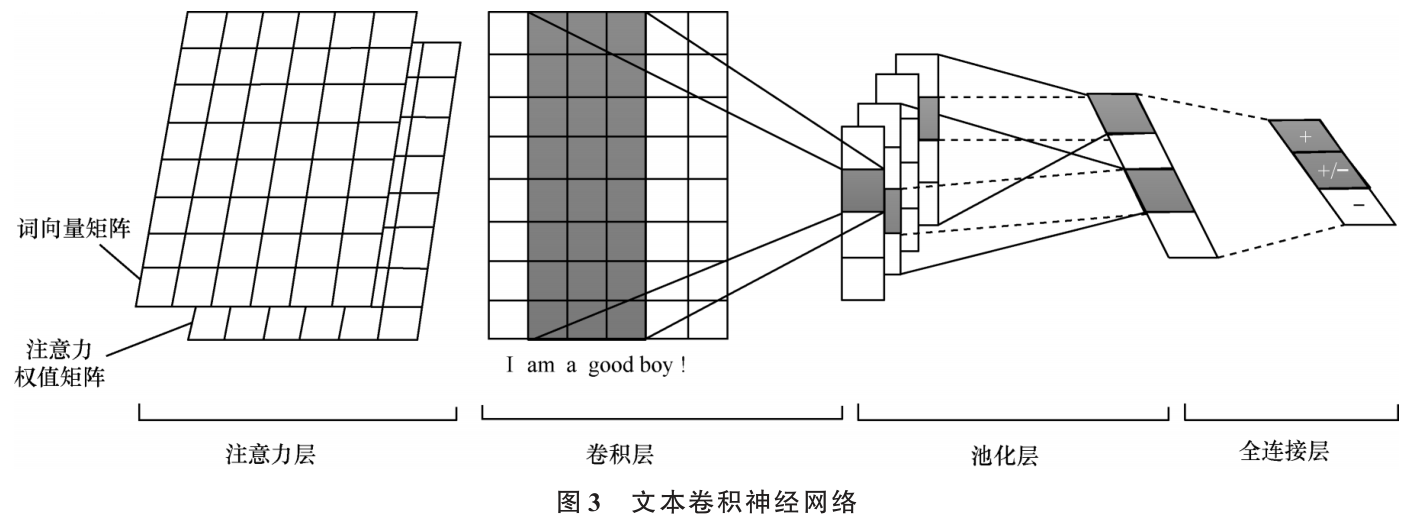
注意力层通过对每个项目文本的词向量矩阵赋予注意力权重以得到更新后的词向量矩阵。将项目文本内容通过嵌入层得到词向量矩阵E∈Rnxd,其中d为词向量的维度,即把每一个词映射为d维向量xj∈Rd,n为单词的个数;F∈Rsxd表示目标用户ui浏览过的所有项目所携带文本信息的词向量矩阵,xi为第i个词的词向量表示xi∈Rd。计算目标用户词向量矩阵F中每个词汇的词向量表示xi与项目所有文本词向量矩阵E中每个词汇xj的注意力分数。a(xi,xj)=vTaR(wa[xi+xj])其中:vTa,wa为训练参数。
预测评分生成
传统的神经网络推荐模型在预测层通常执行用户特征的隐表示p̂u和项目特征的隐表示q̂j之间的交互以得到最终的预测评分。由于该模型缺乏对推荐任务的定制优化,对用户所有历史项目的平等处理会限制其表示能力,例如,在用户进行电影点播时,被推荐电影可能只与用户播放历史中的部分电影相关,而传统的电影推荐方式通常会把用户播放历史中所有的电影作为上下文进行推荐,这与用户的实际偏好不符。传统的神经网络推荐模型忽视了用户历史项目中不同项目对预测下一个项目所起的作用不同,因此准确率较低。
在AMITI模型的预测层,利用神经注意力网络区分历史项目的重要性来克服传统神经网络推荐模型的局限性。学习到用户特征的隐表示p̂u和项目特征的隐表示q̂j作为注意力层的输入,学习目标用户对不同项目的关注度,不同关注度对预测下一项目所起的作用不同。
TF-IDF的改进
TF-IDF常被用于文本分类和信息检索,通常仅考虑文档数量和关键词在文档中出现的频率,而当字词拥有评分数据时无法充分利用评分数据更准确地计算TF-IDF值。例如,利用TF-IDF计算用户ui观看电影中喜剧类型gj的TF-IDF值时,仅将喜剧类型gj在用户ui浏览历史电影集和整个数据集中出现的频率代入计算,并未利用用户对喜剧类电影的评分数据。当喜剧类型gj在用户浏览历史中出现频率较低,但用户对这类电影的评分却较高时,采用传统的TF-IDF方法无法准确地获取用户对喜剧类型gj的偏好程度。将评分数据引入到TF-IDF方法中,在评估字词重要程度的同时,避免丢失评分较高的字词。
AMITI算法描述
利用深度神经网络结合注意力机制能有效提升推荐算法对用户和项目潜在特征的提取能力,并缓解数据的稀疏性问题。依据项目类型分组将推荐结果推荐给用户。AMITI 算法整体实现步骤如下:
输入 用户属性信息u:{u1,u2,...un},un表示用户的第n个属性;项目属性信息v:{v1,v2,...vn},vn表示项目的第n个属性
输出 生成K个项目组,每个项目组含D个同类项目
步骤1 对用户属性和项目属性进行数据预处理,将其转换成数字类型。
步骤2 用户属性和项目ID及类型属性输入嵌入层,得到低维稠密的嵌入向量pu和qv。将pu和qv分别输入到并行的多层全连接层中进行特征学习,得到用户特征p̂u和项目非文本属性向量q̂v。
步骤3 对项目名称做卷积处理,通过注意力机制对电影名称的词向量矩阵重新赋权,得到更新后的词向量矩阵Msxdatt。
步骤4 将词向量矩阵Msxdatt输入卷积神经网络中提取项目名称特征并生成特征qtext,再利用tf.concat()函数合并项目各属性特征得到最终的项目特征q̂j。
步骤5 使用注意力机制为每个项目分配个性化权重âij,得到更新后的项目特征q̂i。
步骤6 将用户隐含特征p̂u与项目隐含特征q̂i作内积计算得到预测评分ŷui。
步骤7 输入指定用户产生Top-N个推荐结果,利用改进TF-IDF分析用户对不同项目类型的偏好程度值Sujgi。
步骤8 根据偏好程度Sujgi值将项目类型降序排列,取前K个类型作为待推荐项目组的组名,K即为推荐项目组的数量。
步骤9 在每个项目组加入D部与组名对应的同类电影,并按每部电影的预测评分降序排列。最终进行由K个项目组构成,且每个项目组包含D部同类型电影的项目组进行推荐。
结尾
春节快到了,在这里先小小地祝福一波朋友们,大家新的一年事事顺意。
另外,愿世间昌平,愿海晏河清。
明儿个见喽。
2024-01-30 10:32:58 星期二
基于注意力机制与改进TF-IDF的推荐算法的更多相关文章
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- 1、Attention_based Group recommendation——基于注意力机制的群组推荐
1.摘要: 本文将Attention-based模型和BPR模型结合对给定的群组进行推荐项目列表. 2.算法思想: 如图: attention-based model:[以下仅计算一个群组的偏好,多个 ...
- 基于局部敏感哈希的协同过滤推荐算法之E^2LSH
需要代码联系作者,不做义务咨询. 一.算法实现 基于p-stable分布,并以‘哈希技术分类’中的分层法为使用方法,就产生了E2LSH算法. E2LSH中的哈希函数定义如下: 其中,v为d维原始数据, ...
- 【甘道夫】基于Mahout0.9+CDH5.2执行分布式ItemCF推荐算法
环境: hadoop-2.5.0-cdh5.2.0 mahout-0.9-cdh5.2.0 引言 尽管Mahout已经宣布不再继续基于Mapreduce开发,迁移到Spark.可是实际面临的情况是公司 ...
- NLP教程(6) - 神经机器翻译、seq2seq与注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- NLP之基于Seq2Seq和注意力机制的句子翻译
Seq2Seq(Attention) @ 目录 Seq2Seq(Attention) 1.理论 1.1 机器翻译 1.1.1 模型输出结果处理 1.1.2 BLEU得分 1.2 注意力模型 1.2.1 ...
- 基于Seq2Seq和注意力机制的句子翻译
Seq2Seq(Attention) 目录 Seq2Seq(Attention) 1.理论 1.1 机器翻译 1.1.1 模型输出结果处理 1.1.2 BLEU得分 1.2 注意力模型 1.2.1 A ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- NLP之基于Bi-LSTM和注意力机制的文本情感分类
Bi-LSTM(Attention) @ 目录 Bi-LSTM(Attention) 1.理论 1.1 文本分类和预测(翻译) 1.2 注意力模型 1.2.1 Attention模型 1.2.2 Bi ...
随机推荐
- 【web】Ajax Study Note
1.Create a XMLHttpRequest Object (1)For IE7+.Firefox.Chrome.Safari and Opera variable = new XMLHttpR ...
- 浅谈LINUX中/DEV/VDA1文件满了解决方法
1. 先查看内存使用情况 df -h 1 2. 进入/dev/vdal的磁盘挂载的目录 /,查看各个文件占用大小 cd / du -sh * 1 2 注意:进入那个比较大的文件,我这里发现var这个文 ...
- Qt/C++编写超精美自定义控件(历时9年更新迭代/超202个控件/祖传原创)
一.前言 无论是哪一门开发框架,如果涉及到UI这块,肯定需要用到自定义控件,越复杂功能越多的项目,自定义控件的数量就越多,最开始的时候可能每个自定义控件都针对特定的应用场景,甚至里面带了特定的场景的一 ...
- vue3项目实战+element-plus
记录自己搭建前端项目的学习过程和开发过程,希望一起学习进步 采用Vue3+element-plus+axios+vue-router+sass--(目前刚开始是用到了这些,随着开发慢慢更新) npm是 ...
- Redis源码历史版本下载地址和Redis的Windows版本服务端/客户端下载地址
Redis源码历史版本下载地址:http://download.redis.io/releases/ Redis的Windows版本服务端/客户端下载地址:https://github.com/mic ...
- kubernetes系列(七) - Pod生命周期
目录 1. pod生命周期 2. initC 2.1 initC介绍 2.2 initC的作用 2.3 initC的模版 2.4 initC的一些其他补充 3. Pod健康性检查(liveiness) ...
- 人类讨厌AI的缺点,其实自己也有,是时候反思了。
马特·科拉默摄于Unsplash 前言:人类讨厌AI,其实就是讨厌自己! 如果你问一些人对人工智能的看法,你可能会听到诸如不道德.偏见.不准确甚至操纵这样的词语. 人工智能因为种种原因正备受批评.它让 ...
- Qml 中实现任意角为圆角的矩形
[写在前面] 在 Qml 中,矩形(Rectangle)是最常用的元素之一. 然而,标准的矩形元素仅允许设置统一的圆角半径. 在实际开发中,我们经常需要更灵活的圆角设置,例如只对某些角进行圆角处理,或 ...
- Vanity Intermediate 统配符提权
nmap扫描 ┌──(root㉿kali)-[~] └─# nmap -p- -A 192.168.167.234 Starting Nmap 7.94SVN ( https://nmap.org ) ...
- 最佳产品奖,TeleDB拿下!
近日,第十三届PostgreSQL技术大会在杭州举行.本次大会以"聚焦云端创新,汇聚智慧共享"为主题,行业大咖.学术精英.技术专家和技术爱好者齐聚一堂,共同探讨数据库领域的发展趋势 ...