BLOG-1
前言
回顾这三次作业的心路历程,可以说每一次都带来了新的挑战与收获,随着题目数量和复杂度的增加,对Java编程的理解和面向对象设计的认知逐步加深。作为Java编程初学者,最初对编程架构、模块分层和错误处理的认识相对浅显,但通过这三次作业,从题目处理到答案判定再到错误信息提示,逐步体验了如何应对不同需求场景下的代码设计。在初期的几次作业中,虽然我们在表面上完成了题目需求,但后续的实际测试和互测却揭示了架构缺陷和代码的耦合性过高的问题,因此需要更多地关注代码的复用性、可扩展性和鲁棒性。
第一阶段的作业以实现基础的判题程序为主,输入题目和答题信息,输出答题判定结果。由于涉及的功能较少,架构设计比较简单。到了第二次作业,需求增加了对试卷信息的判定和学生信息管理,题目处理的复杂度随之提升,这就要求我们从整体上重新设计模块的耦合关系,以实现输入解析、题目管理、判题、错误处理等功能的分离。到了第三次作业,需求进一步增加了删除题目和多种错误类型的处理,这时我们开始采用更精细化的架构设计,并逐步引入异常处理机制以提高代码的健壮性。总体来看,前三次作业逐渐加深了我们对面向对象编程的理解,并让我们在编码实践中理解到设计模式、数据结构与算法优化的重要性。
设计与分析
在系统架构的设计上,我们采用了多层次对象分层的方式,将代码逻辑按照题目、试卷、学生、答题等不同信息类型划分为多个类,结合具体的业务逻辑,实现信息管理、判分、异常处理等功能的模块化。以下是具体的设计分析和实现过程。
题目类:数据封装与判题逻辑
题目类的核心任务是封装题目的信息,并提供判题功能。题目类在前三次作业中的基本架构保持不变,但随着功能需求的增加,逐步加入了针对不同场景的处理方法。具体来说,题目类包含了题号、题目内容、标准答案等属性,并在方法层面提供了数据访问和判题功能,主要代码如下: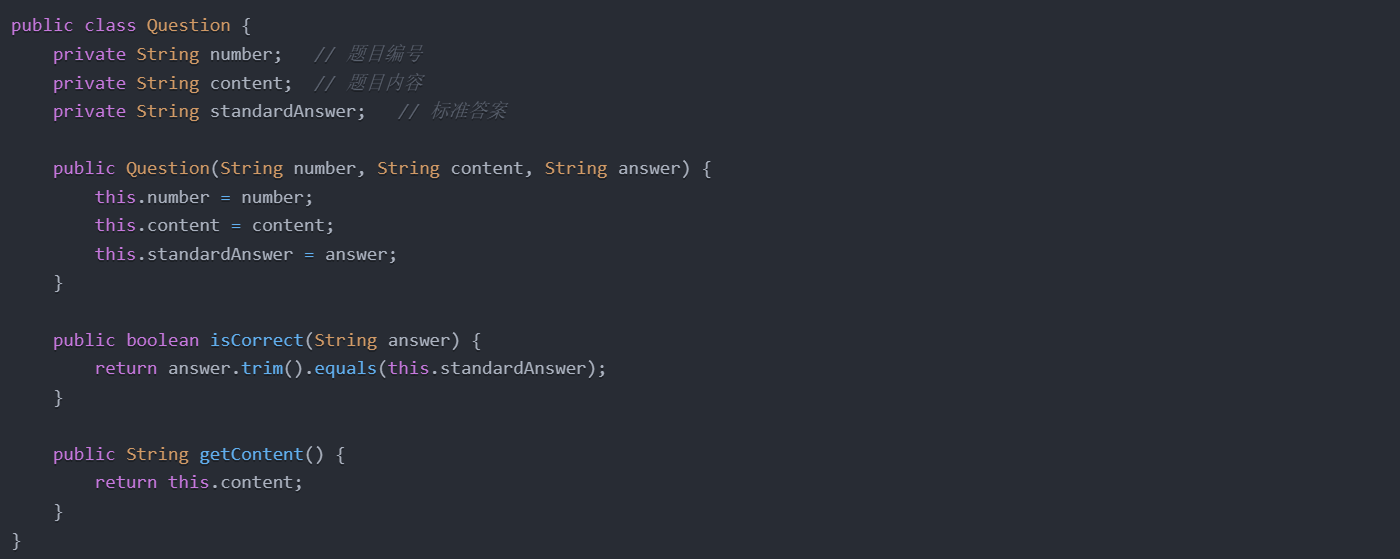
在上述设计中,isCorrect方法用于判定输入的答案是否符合标准答案。getContent和getNumber方法为题目内容和编号提供了访问接口,确保了数据的封装性和可复用性。尤其在第三次作业中,考虑到题目删除的需求,我们引入了isDeleted标识用于判题时的删除状态检查。在此基础上增加了错误提示信息,确保在题目删除后,不再影响试卷的整体判分逻辑。试卷类:题目管理与分数核算
试卷类在架构中主要承担题目列表的管理职责,并负责试卷题目引用、分数计算等功能。它通过维护题目列表,为后续的判分和题目状态校验提供支持。以下为试卷类的简化代码:
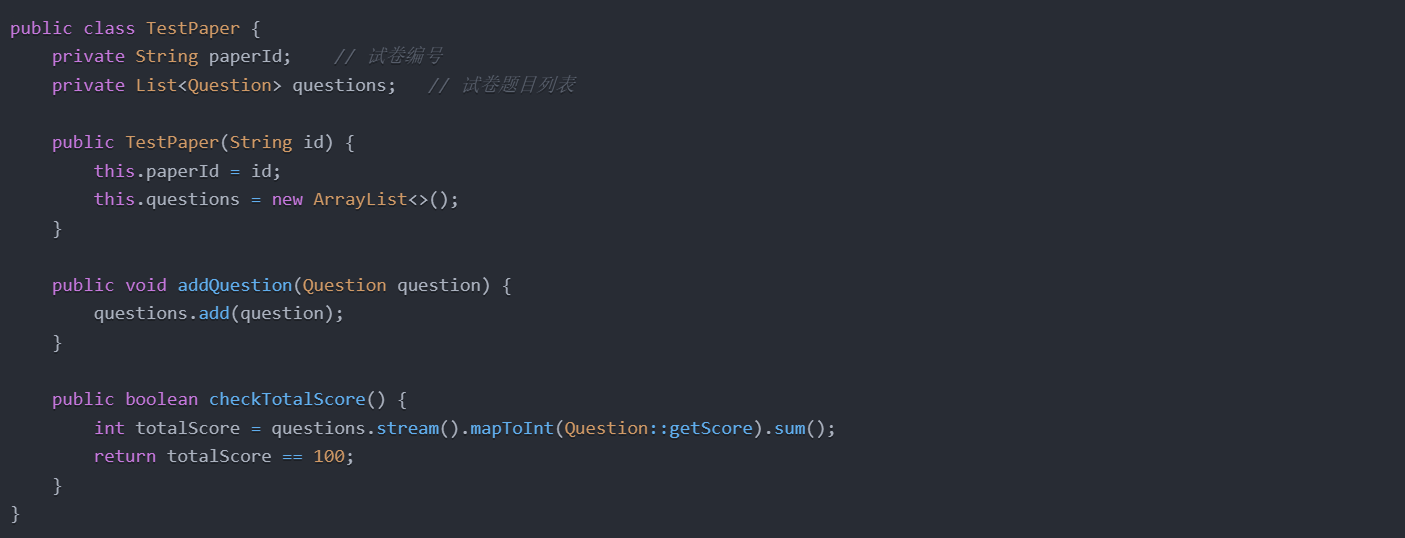
在第二次作业中,试卷类的设计要求增加对分数的校验功能,确保每张试卷的总分符合要求。checkTotalScore方法通过题目分数累加,判断是否符合预期的100分要求,在不符时输出提示。这种分数检查需求从架构上要求试卷类必须包含题目信息,这在后续的设计中,直接影响了我们对题目删除、错误信息提示等功能的扩展。
在第三次作业中,题目引用错误检测成为了试卷类的一个重点,要求在试卷引用的题目信息不全时输出特定的错误提示。为此我们在试卷类中增加了题目编号的校验,确保在题目不存在的情况下可以输出相应的错误提示。通过这种方式,试卷类实现了对题目信息的动态管理,为判分和题目处理的多样性提供了支持。学生类:信息封装与判分
学生类封装了学生编号和姓名,并提供了相关的判分接口。考虑到每位学生的答题信息会动态变化,学生类中的判分逻辑直接依赖于答题类提供的接口。具体设计如下:
在第三次作业中,学生信息不仅需要对学生答题情况输出正确判分,还要根据答题的题目情况,动态调整分数计算。由于学生信息的准确性对后续判分至关重要,因此在该部分设计上,增加了对学生答卷信息的校验逻辑。答卷类:答案管理与判题流程
答卷类在系统架构中主要负责答题信息的存储和答案判定。通过与试卷、题目类的交互,答卷类能够根据题目列表进行答案比对并输出判题结果。主要的代码结构如下:
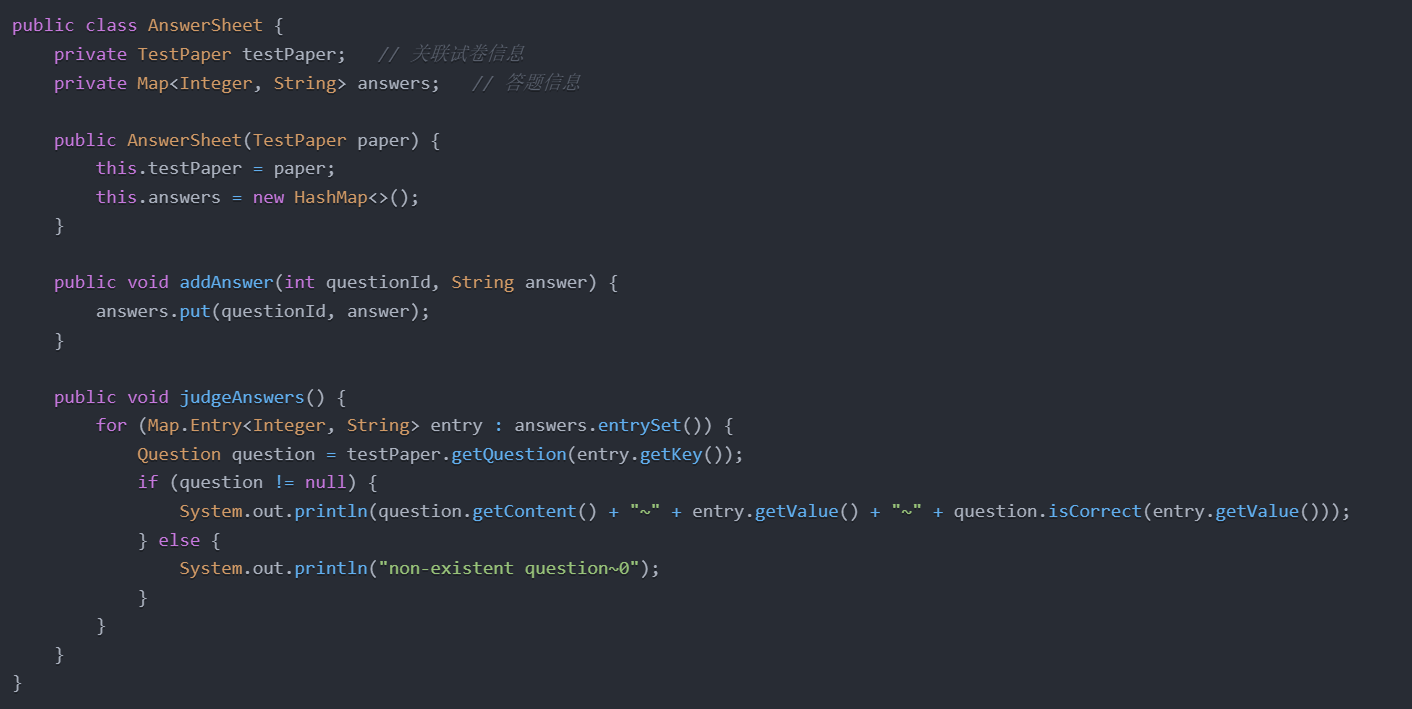
在设计上,judgeAnswers方法负责答卷的整体判分。它会根据试卷中的题目列表,逐个判断学生的答案,并依据题目状态(如删除、题号错误等)输出特定的提示。在实现中,答卷类与题目、试卷类的耦合度较高,尤其在删除和题目引用错误的处理上,显得略为繁琐。因此在未来的扩展中,考虑将题目和答案的管理进一步分离以降低代码耦合度。类图展示以及代码复杂度分析
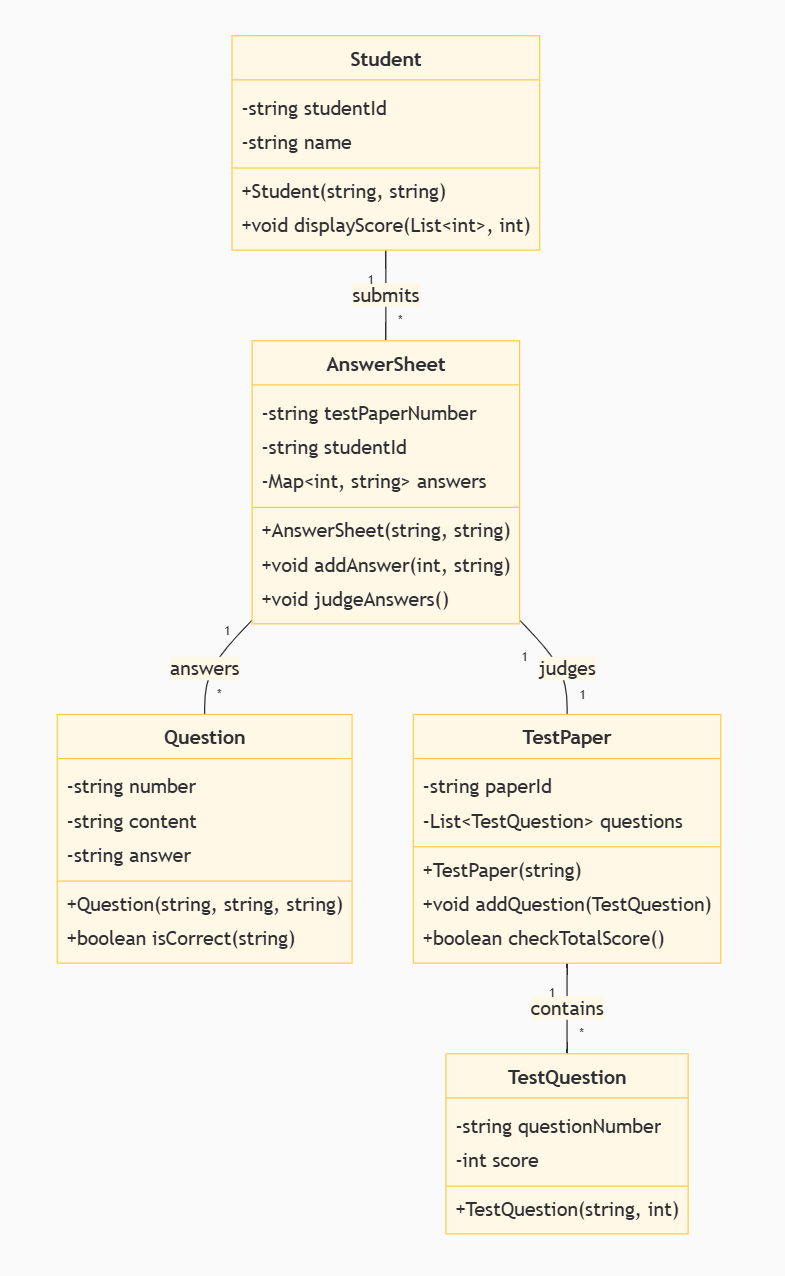
系统由五个主要类组成:Student、AnswerSheet、Question、TestPaper、TestQuestion,它们共同实现了答题和评分的流程。
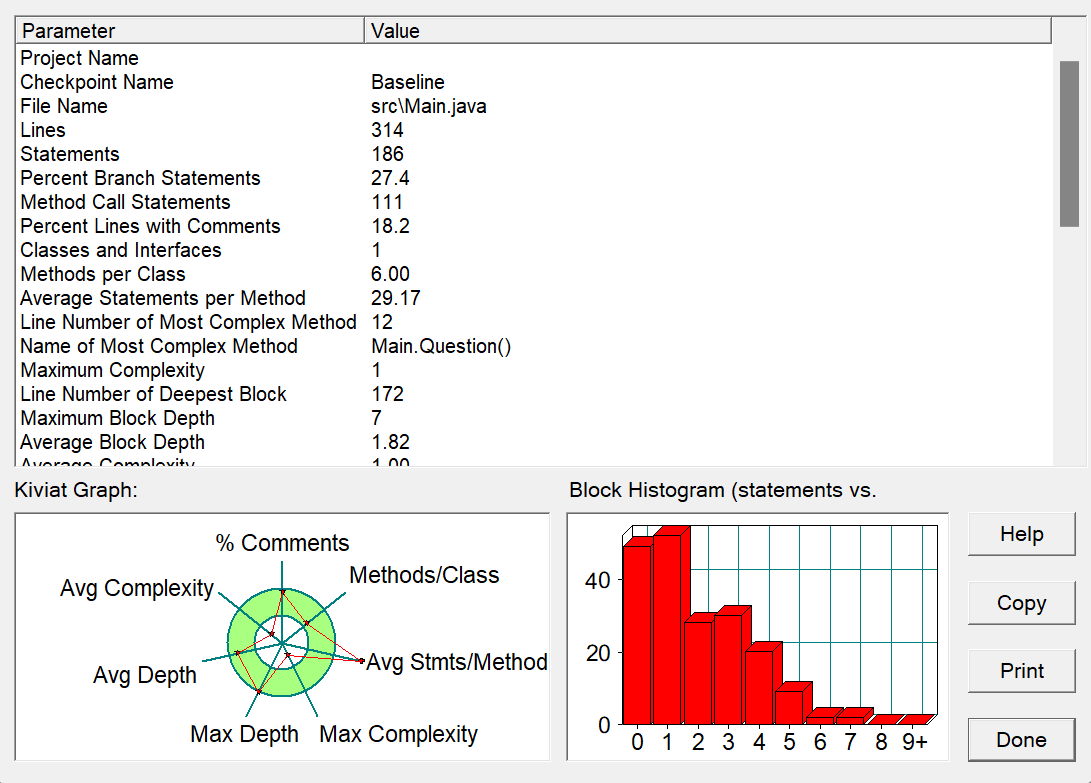
代码行数与分支语句比例:代码总行数为314行,其中分支语句(if-else和switch等)占27.4%。这一比例显示代码中分支判断较多,是因为在判题和错误处理部分需要进行大量条件分支,尤其是对题目失效、答案格式等的检测。
方法数量与复杂性:每个类的平均方法数为6,方法内部平均语句数为29.17。较高的平均语句数显示部分方法逻辑过于复杂,存在可以拆分的操作。报告中显示最复杂的方法为Main.Question(),行数为12,可以进一步分解复杂方法。
块嵌套深度与复杂性分布:从复杂性直方图来看,大部分代码块的复杂度在1~2之间,但有少部分复杂度达到6以上。这是集中在AnswerSheet类的判题逻辑和TestPaper类的分数校验部分。这些代码段可以进一步简化或使用辅助方法,减少深层嵌套。
Kiviat Graph分析:
注释比例较低(18.2%):代码注释较少,后期维护和阅读上会有一定困难。建议在复杂的判题逻辑和条件判断部分增加注释,便于后续理解和优化。
最大深度和平均深度:最大块深度为7,平均块深度为1.82,显示部分逻辑的嵌套较深。嵌套深度较高的代码块会影响代码的可读性和可维护性,后续可以通过方法提取或辅助方法来简化这些部分。
采坑心得
在开发与测试过程中,遇到了诸多细节问题,包括格式校验的失误、答案判定的逻辑漏洞、以及错误处理的冗余。以下是主要的采坑经验总结:
题目解析的递归层级问题:由于题目内容中的特殊字符及嵌套结构带来的递归问题,导致解析的层次过深。在尝试引入递归时,注意到需要提前判断是否满足基本条件,否则很容易进入无限循环。
格式验证与正则匹配:在试卷和答题信息的正则匹配上,初期我们忽略了多余空格或格式错位的校验,导致部分错误信息未被捕获。在后续的改进中,通过正则表达式细化和手动校验相结合的方式,提高了匹配的准确性和程序的容错能力。
删除题目和引用错误的校验:在判分过程中,题目是否被删除直接影响最终判分结果。我们一开始在判分中并未区分题目是否被引用,因此导致了部分题目判分混乱。通过引入题目删除标志位,且在判分过程中加入状态判定,解决了这一问题。
Java断言与异常处理:Java的断言在默认情况下未启用,导致在判分中未能及时捕获到格式异常。这一问题提醒我们,断言功能需要手动打开或通过自定义异常类实现,以确保测试的全面性。
改进建议
通过前三次作业的逐步深入,我们积累了代码设计、测试和调试方面的经验,未来在代码复用性和测试覆盖率上有较多的改进空间:
判题逻辑与数据处理解耦:在设计中可以考虑将判题、题目数据处理、错误提示等功能进一步解耦。未来引入策略模式或工厂模式,可以有效简化题目状态管理和判题流程,并提高代码的扩展性。
配置化错误提示信息:可以将题目和答卷错误提示转移到资源文件中,避免硬编码。通过配置化设计,将来可更灵活地根据不同需求更改错误提示信息,提高代码的适应性和灵活性。
代码注释与文档化,由于代码注释比例较低,尤其在复杂逻辑处缺乏足够的解释,建议在判题逻辑和数据处理流程中添加注释。尤其是一些嵌套较深的条件判断,应当在关键分支处添加详细注释,说明各条件分支的作用和输入要求。
总结
这三次作业的完成,极大地提升了我们对面向对象编程、Java语言特性及代码优化的理解。从最初的题目解析到逐渐引入的异常处理、测试覆盖和数据校验,我们逐步掌握了代码设计和调试的技巧。在整个开发过程中,我们不断调整代码架构以适应不同的需求场景,通过测试和调试积累经验,学会了如何应对复杂项目的挑战。期待在未来的项目中,将这些经验应用到更为复杂的系统中,进一步提升编程能力和架构设计水平。
BLOG-1的更多相关文章
- 日向blog开发记录
一点历史关于,Sonne Blog 2016.03.25springmvc + hibernate框架搭建.2016.04.21日向blog首页.2016.04.24分页实现.2016.04.30登录 ...
- blog (后续更新)
设计Model(设计数据库) from django.db import models # Create your models here. class BlogsPost(models.Model) ...
- tensorflow 一些好的blog链接和tensorflow gpu版本安装
pading :SAME,VALID 区别 http://blog.csdn.net/mao_xiao_feng/article/details/53444333 tensorflow实现的各种算法 ...
- http://blog.csdn.net/java2000_wl/article/details/8627874
http://blog.csdn.net/java2000_wl/article/details/8627874
- [Android Pro] http://blog.csdn.net/wuyinlei/article/category/5773375
http://blog.csdn.net/wuyinlei/article/category/5773375
- android 蓝牙 http://blog.csdn.net/u012843100/article/details/52384219
http://blog.csdn.net/u012843100/article/details/52384219
- 【三】用Markdown写blog的常用操作
本系列有五篇:分别是 [一]Ubuntu14.04+Jekyll+Github Pages搭建静态博客:主要是安装方面 [二]jekyll 的使用 :主要是jekyll的配置 [三]Markdown+ ...
- django开发个人简易Blog—nginx+uwsgin+django1.6+mysql 部署到CentOS6.5
前面说完了此项目的创建及数据模型设计的过程.如果未看过,可以到这里查看,并且项目源码已经放大到github上,可以去这里下载. 代码也已经部署到sina sea上,地址为http://fengzhen ...
- 使用Hexo搭建专属Blog
喜欢折腾的自己最开始在博客园有仿写几篇Blog,虽也可以自己改变风格,可是到底不是独立的一块儿地方,要知道独立的才是自己的;有属于自己独立的域名和Blog,真真是一件很爽的存在.在各种大牛的分享下在G ...
- First Blog
俗话说“笨鸟先飞”,遗憾的是我这只笨鸟直到今天才意识到个人博客的重要性. 原来记录下学习生活中的每一丝领悟与思考,可以让个人内在,对知识的理解得到更好的升华. 有梦的人很美,追梦的人更美.像我的座右铭 ...
随机推荐
- 【Java】之获取CSV文件数据以及获取Excel文件数据
一.获取CSV文件数据 import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.Sheet; impor ...
- 使用inno setup 打包Pyinstaller生成的文件夹
背景:pyinstaller 6.5.0.Inno Setup 6.2.2 1. 需要先使用pyinstaller打包,生成包括exe在内的可执行文件夹 注意:直接使用pyinstaller打包,生成 ...
- spark 自定义 accumulator
默认的accumulator 只是最简单的 int/float 有时候我需要一个map来作为accumulator 这样,就可以处理 <string, int>类型的计数了. 此外我还需要 ...
- 【Azure Developer】上手 The Best AI Code "Cursor" : 仅仅7次对话,制作个人页面原型,效果让人惊叹!
AI Code 时代早已开启,自己才行动.上手一试,让人惊叹.借助这感叹的情绪,把今天操作Cursor的步骤记录下来,也分享给大家. 推荐大家上手一试,让你改变! 准备阶段 下载 Cursor(htt ...
- axios使用备忘录
安装使用 使用npm安装: $ npm install axios 使用CDN: <script src="https://unpkg.com/axios/dist/axios.min ...
- TFC-Pretraining: 基于时间频率一致性对时间序列进行自监督对比预训练《Self-Supervised Contrastive Pre-Training for Time Series via Time-Frequency Consistency》(时间序列、时序表征、时频一致性、对比学习、自监督学习)
2023年11月10日,今天看一篇论文,现在17:34,说实话,想摆烂休息,不想看,可还是要看,拴Q. 论文:Self-Supervised Contrastive Pre-Training for ...
- 工具 – Vitest 与单元测试
前言 Vitest 是一款配搭 Vite 的前端单元测试工具,可以用于取代 Jasmine 和 Jest. 我先聊一下测试,每当添加新代码或修改旧代码后,我们多少都得测试一下,以确保功能正确才能交付. ...
- EntityFramework Core并发迁移解决方案
场景 目前一个项目中数据持久化采用EF Core + MySQL,使用CodeFirst模式开发,并且对数据进行了分库,按照目前颗粒度分完之后,大概有一两百个库,每个库的数据都是相互隔离的. 借鉴了G ...
- SuperMap iManager for K8S 删除旧环境修改NFS地址流程
一.完整删除SuperMap iManager 找到SuperMap iManager安装目录,执行: ./shutdown.sh -v 二.修改NFS存储路径 有两种办法,一种是直接修改/etc/e ...
- PHP面试,拼团
如何设计数据库模型来支持拼团功能? 答案:拼团功能涉及到多个用户参与同一团的情况,可以设计以下表结构: Product 表: 存储商品信息,包括商品ID.名称.价格等字段. Group 表: 存储拼团 ...