PaddleOCR学习笔记3-通用识别服务
今天优化了下之前的初步识别服务的python代码和html代码。
采用flask + paddleocr+ bootstrap快速搭建OCR识别服务。
代码结构如下:
模板页面代码文件如下:
upload.html :
<!DOCTYPE html>
<html>
<meta charset="utf-8">
<head>
<title>PandaCodeOCR</title>
<!--静态加载 样式-->
<link rel="stylesheet" href={{ url_for('static',filename='bootstrap3/css/bootstrap.min.css') }}></link>
<style>
body {
font-family: Arial, sans-serif;
margin: 0;
padding: 0;
} .header {
background-color: #f0f0f0;
text-align: center;
padding: 20px;
} .title {
font-size: 32px;
margin-bottom: 10px;
} .menu {
list-style-type: none;
margin: 0;
padding: 0;
overflow: hidden;
background-color: #FFDEAD;
border: 2px solid #DCDCDC;
} .menu li {
float: left;
font-size: 24px;
} .menu li a {
display: block;
color: #333;
text-align: center;
padding: 14px 16px;
text-decoration: none;
} .menu li a:hover {
background-color: #ddd;
} .content {
padding: 20px;
border: 2px solid blue;
}
</style>
</head>
<body>
<div class="header">
<div class="title">PandaCodeOCR</div>
</div> <ul class="menu">
<li><a href="/upload/">通用文本识别</a></li>
</ul> <div class="content">
<!--上传图片文件-->
<div id="upload_file">
<form id="fileForm" action="/upload/" method="POST" enctype="multipart/form-data">
<div class="form-group">
<input type="file" class="form-control" id="upload_file" name="upload_file">
<label class="sr-only" for="upload_file">上传图片</label>
</div>
</form>
</div>
</div>
</div> <div id="show" style="display: none;">
<!--显示上传的图片-->
<div class="col-md-6" style="border: 2px solid #ddd;">
<span class="label label-info">上传图片</span>
<!--静态加载 图片, url_for() 动态生成路径 -->
<img src="" alt="Image preview area..." title="preview-img" class="img-responsive">
</div> <div class="col-md-6" style="border: 2px solid #ddd;">
<!--显示识别结果JSON报文列表-->
<span class="label label-info">识别结果:</span>
<!-- 结果显示区 -->
<div id="result_show">加载中......</div>
</div>
</div>
</body>
</html>
<!--静态加载 script-->
<script src={{ url_for('static',filename='jquery1.3.3/jquery.min.js') }}></script>
<script src={{ url_for('static',filename='js/jquery-form.js') }}></script>
<script type="text/javascript">
var fileInput = document.querySelector('input[type=file]');
var previewImg = document.querySelector('img');
{#上传图片事件#}
fileInput.addEventListener('change', function () {
var file = this.files[0];
var reader = new FileReader(); //显示预览界面
$("#show").css("display", "block"); // 监听reader对象的的onload事件,当图片加载完成时,把base64编码賦值给预览图片
reader.addEventListener("load", function () {
previewImg.src = reader.result;
}, false);
// 调用reader.readAsDataURL()方法,把图片转成base64
reader.readAsDataURL(file); //初始化输出结果信息
$("#result_show").html("加载中......"); {#上传图片识别表单事件,并显示识别结果信息#}
{# ajaxSubmit 请求异步响应#}
$("#fileForm").ajaxSubmit(function (data) {
var inner = "";
//alert(data['recognize_time'])
//循环输出返回结果,响应识别结果为每行列表
for (var i in data['result']) {
var value = data['result'][i]['text'];
inner += "<p class='text-left'>" + value + "</p>";
}
//清空输出结果信息
$("#result_show").html("");
//添加识别结果信息
$("#result_show").append(inner);
});
}, false);
</script>
主要python代码文件如下:
myapp.py:
import json
import os
import time from flask import Flask, render_template, request, jsonify from paddleocr import PaddleOCR
from PIL import Image, ImageDraw
import numpy as np # 应用名称,当前py名称,视图函数
app = Flask(__name__) # 项目文件夹的绝对路径
# BASE_DIR = os.path.dirname(os.path.abspath(__name__))
# 相对路径
BASE_DIR = os.path.dirname(os.path.basename(__name__)) # 上传文件路径
UPLOAD_DIR = os.path.join(os.path.join(BASE_DIR, 'static'), 'upload') '''
PaddleOCR模型通用识别方法
'''
def rec_model_ocr(img):
# 返回字典结果对象
result_dict = {'result': []}
# paddleocr 目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
# 使用CPU预加载,不用GPU
# 模型路径下必须包含model和params文件,目前开源的v3版本模型 已经是识别率很高的了
# 还要更好的就要自己训练模型了。
ocr = PaddleOCR(det_model_dir='./inference/ch_PP-OCRv3_det_infer/',
rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/',
cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/',
use_angle_cls=True, lang="ch", use_gpu=False)
# 识别图片文件
result0 = ocr.ocr(img, cls=True)
result = result0[0]
for index in range(len(result)):
line = result[index] tmp_dict = {}
points = line[0]
text = line[1][0]
score = line[1][1]
tmp_dict['points'] = points
tmp_dict['text'] = text
tmp_dict['score'] = score result_dict['result'].append(tmp_dict)
return result_dict # 转换图片
def convert_image(image, threshold=None):
# 阈值 控制二值化程度,不能超过256,[200, 256]
# 适当调大阈值,可以提高文本识别率,经过测试有效。
if threshold is None:
threshold = 200
print('threshold : ', threshold)
# 首先进行图片灰度处理
image = image.convert("L")
pixels = image.load()
# 在进行二值化
for x in range(image.width):
for y in range(image.height):
if pixels[x, y] > threshold:
pixels[x, y] = 255
else:
pixels[x, y] = 0
return image @app.route('/')
def upload_file():
return render_template('upload.html') @app.route('/upload/', methods=['GET', 'POST'])
def upload():
if request.method == 'POST':
# 每个上传的文件首先会保存在服务器上的临时位置,然后将其实际保存到它的最终位置。
filedata = request.files['upload_file']
upload_filename = filedata.filename
print(upload_filename)
# 保存文件到指定路径
# 目标文件的名称可以是硬编码的,也可以从 request.files[file] 对象的 filename 属性中获取。
# 但是,建议使用 secure_filename() 函数获取它的安全版本
if not os.path.exists(UPLOAD_DIR):
os.makedirs(UPLOAD_DIR)
img_path = os.path.join(UPLOAD_DIR, upload_filename)
filedata.save(img_path)
print('file uploaded successfully') start = time.time() print('=======开始OCR识别======')
# 打开图片
img1 = Image.open(img_path)
# 转换图片, 识别图片文本
# print('转换图片,阈值=220时,再转换为ndarray数组, 识别图片文本')
# 转换图片
img2 = convert_image(img1, 220)
# Image图像转换为ndarray数组
img_2 = np.array(img2)
# 识别图片
result_dict = rec_model_ocr(img_2) # 识别时间
end = time.time()
recognize_time = int((end - start) * 1000) result_dict["filename"] = upload_filename
result_dict["recognize_time"] = str(recognize_time)
result_dict["error_code"] = "000000"
result_dict["error_msg"] = "识别成功" # render_template方法:渲染模板
# 参数1: 模板名称 参数n: 传到模板里的数据
# return render_template('result.html', result_dict=result_dict) # 将数据转换成JSON格式,一般用于ajax异步响应页面,不跳转页面用,等价下面方法
# return json.dumps(result_dict, ensure_ascii=False), {'Content-Type': 'application/json'} # 将数据转换成JSON格式,一般用于ajax异步响应页面,不跳转页面用
return jsonify(result_dict) else:
return render_template('upload.html') if __name__ == '__main__':
# 启动app
app.run(port=8000)
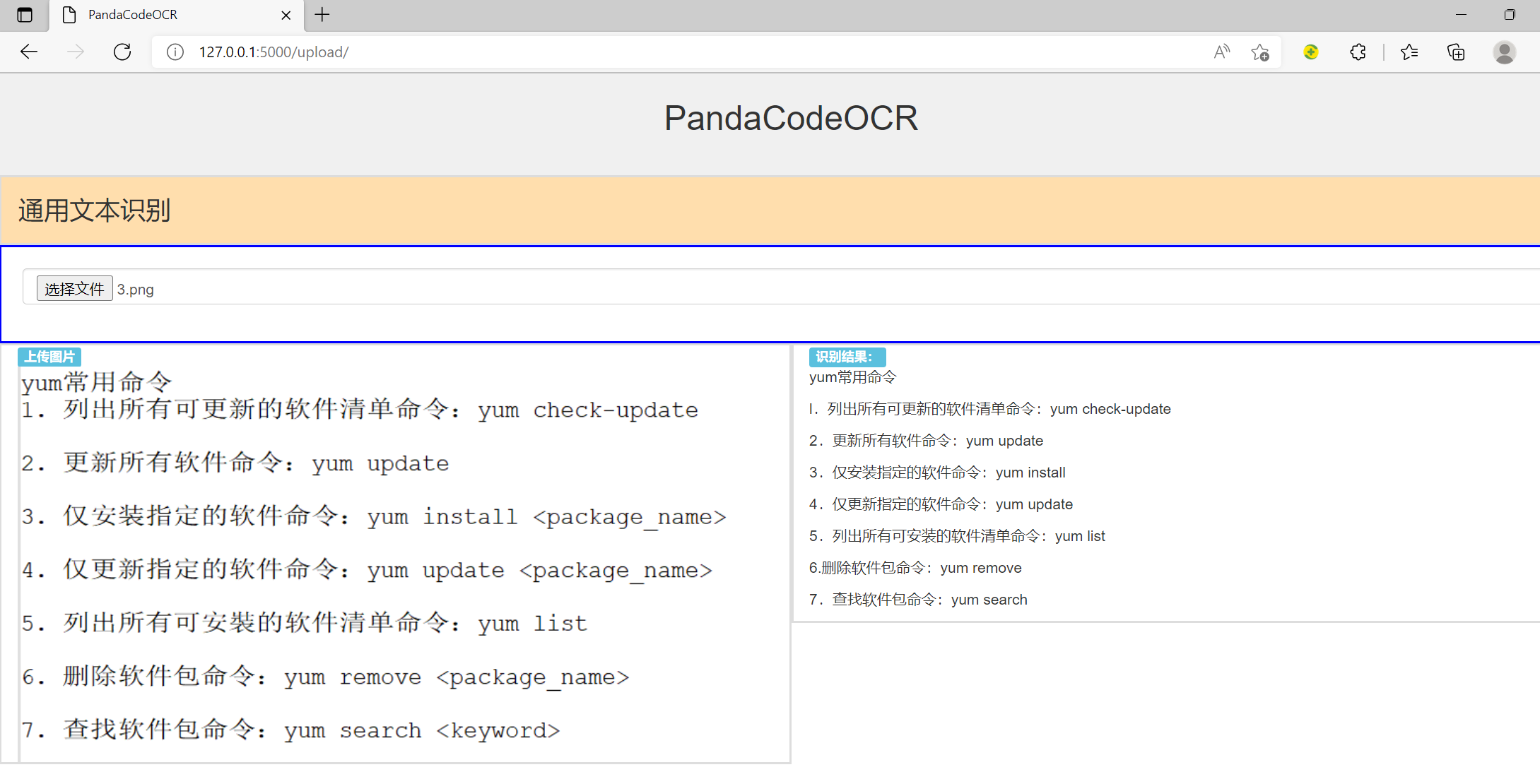
启动flask应用,测试结果如下:
PaddleOCR学习笔记3-通用识别服务的更多相关文章
- 多线程编程学习笔记——异步调用WCF服务
接上文 多线程编程学习笔记——使用异步IO 接上文 多线程编程学习笔记——编写一个异步的HTTP服务器和客户端 接上文 多线程编程学习笔记——异步操作数据库 本示例描述了如何创建一个WCF服务,并宿主 ...
- 学习笔记TF058:人脸识别
人脸识别,基于人脸部特征信息识别身份的生物识别技术.摄像机.摄像头采集人脸图像或视频流,自动检测.跟踪图像中人脸,做脸部相关技术处理,人脸检测.人脸关键点检测.人脸验证等.<麻省理工科技评论&g ...
- Binder学习笔记(九)—— 服务端如何响应Test()请求 ?
从服务端代码出发,TestServer.cpp int main() { sp < ProcessState > proc(ProcessState::self()); sp < I ...
- matlab学习笔记10_5 通用字符串操作和比较函数
一起来学matlab-matlab学习笔记10 10_5 通用字符串操作和比较函数 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考书籍 <matlab 程序设计与综合应用>张 ...
- 10月9日Android学习笔记:活动与服务之间的通信
最近在照着<第一行代码>这本书来学安卓,顺便记下笔记.主要的内容是Android中服务的第二种启动方式,通过活动绑定服务来启动服务,实现活动与服务之间的通信. 一. 首先创建一个服务类 p ...
- Netty4 学习笔记之一:客户端与服务端通信 demo
前言 因为以前在项目中使用过Mina框架,感受到了该框架的强大之处.于是在业余时间也学习了一下Netty.因为Netty的主要版本是Netty3和Netty4(Netty5已经被取消了),所以我就直接 ...
- Netty4 学习笔记之四: Netty HTTP服务的实现
前言 目前主流的JAVA web 的HTTP服务主要是 springMVC和Struts2,更早的有JSP/servlet. 在学习Netty的时候,发现Netty 也可以作HTTP服务,于是便将此整 ...
- Docker学习笔记 - Docker客户端和服务端
学习内容: Docker客户端和服务端的通讯方式:client和自定义程序 Docker客户端和服务端的连接方式:socket 演示Docker客户端和服务端之间用remote-api通讯:nc ...
- Webpack4 学习笔记七 跨域服务代理
webpack 小插件使用 webpack 监听文件变化配置 webpack 处理跨域问题 Webpack 小插件使用 clean-webpack-plugin: 用于在生成之前删除生成文件夹的Web ...
- iOS学习笔记06-手势识别
一.UIGestureRecognizer简单介绍 我们已经学习了触摸事件处理,但触摸事件处理起来很麻烦,每个触摸事件处理都需要实现3个touches方法,比较繁琐,实际上我们可以使用更加简单的触摸事 ...
随机推荐
- [转]CUDA,NVIDIA Driver,Linux,GCC之间的版本对应关系表格
在安装CUDA时一定要注意其与英伟达显卡驱动以及Linux系统和GCC版本的对应关系,如果版本之间不匹配,是安装不成功的. 一.CUDA与Driver的对应版本 参考链接:https://docs.n ...
- TagHelper中获取当前Url
在自定义TagHelper时,我们无法通过TagHelperContext 和 TagHelperOutput 获取到当前路由的信息,我们需要添加注入ViewContext [HtmlAttribut ...
- C#/.NET/.NET Core优秀项目和框架2024年12月简报
前言 公众号每月定期推广和分享的C#/.NET/.NET Core优秀项目和框架(每周至少会推荐两个优秀的项目和框架当然节假日除外),公众号推文中有项目和框架的详细介绍.功能特点.使用方式以及部分功能 ...
- 零基础学习Modbus通信协议
大家好!我是付工. 2012年开始接触Modbus协议,至今已经有10多年了,从开始的懵懂,到后来的顿悟,再到现在的开悟,它始终岿然不动,变化的是我对它的认知和理解. 今天跟大家聊聊关于Modbus协 ...
- Solution Set - IQ ↓↓
Q: 为什么说雨兔是个傻子? A: 因为一路上全是星号标记. 呃, 本来的好像是 constructive || greedy, 但感觉最近整体题量不高, 就换成 2700-2900 了. 然后惊 ...
- 使用GTD工作法提升效率
前言 近年来随着工作.副业的开展,每天要做的事情越来越多,而且还积攒了很多工作,每天大脑被各种事情充斥着,乱糟糟的,不仅效率很低,还很容易导致焦虑. 为此我一直有在寻找合适的项目管理工具,也看了一些相 ...
- c# 创建快捷方式并添加到开始菜单程序目录
Using the Windows Script Host (make sure to add a reference to the Windows Script Host Object Model, ...
- nginx配置好访问返回502错误
CentOS服务器配置好Nginx重新加载了配置文件,浏览器访问提示错误: 502 Bad Gatewaynginx/1.16.1 如图: 页面上直接显示了nginx名称,一般是说nginx服务器返回 ...
- CentOS7安装nvm和node
一.安装nvm 官方文档:https://github.com/nvm-sh/nvmwindows版文档:https://github.com/coreybutler/nvm-windowswindo ...
- 打造有效安全闭环,天翼云MDR来了!
随着网络攻-防对抗形势愈演愈烈,传统的安全防护模式已难以应对频率暴增.昼夜不停的网络安全攻-击,提升组织安全防护能力势在必行.事实上,一些单位在网络安全建设工作中经验不足,在安全组件/设备采购方面大量 ...