Ubuntu 14.04 LTS 安装 spark 1.6.0 (伪分布式)-26号开始
需要下载的软件:
1.hadoop-2.6.4.tar.gz 下载网址:http://hadoop.apache.org/releases.html
2.scala-2.11.7.tgz 下载网址:http://www.scala-lang.org/
3.spark-1.6.0-bin-hadoop2.6.tgz 下载网址:http://spark.apache.org/
4.jdk-8u73-linux-x64.tar.gz 下载网址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Root用户的开启
为了简化Linux系统下的权限问题,我都是以root用户身份登陆和使用Ubuntu系统,而Ubuntu系统在默认情况下并没有开启root用户,我们需要开启root用户,我参考一下网址实现了root用户的开启:http://jingyan.baidu.com/article/27fa73268144f346f8271f83.html.
1.打开terminal终端(ctrl+Alt+T):
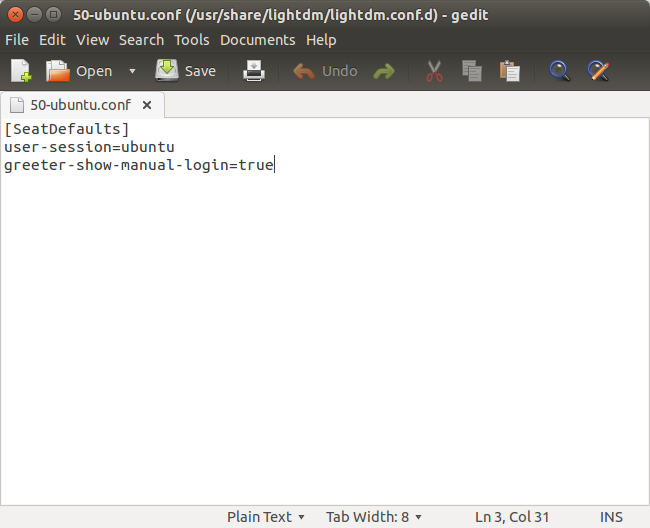
2.输入sudo gedit /usr/share/lightdm/lightdm.conf.d/50-ubuntu.conf 回车了之后,可能会提示输入密码,输入后会弹出如图示的编辑框。在编辑框中输入greeter-show-manual-login=true 保存关闭。
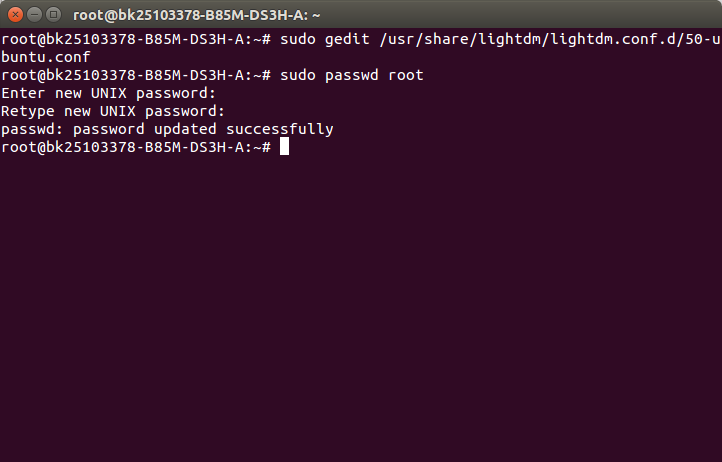
3.关闭之后,回到终端窗口,输入:sudo passwd root 回车;回车之后会要你输入两次密码,出现已成功更新密码字样即为成功。
4.然后关机重启之后,登陆的图形界面中,就可以输入root用户名和密码登陆了。
安装JAVA JDK
1.用root用户登陆后,cd到jdk下载存放的地方,利用tar -xf jdk-8u73-linux-x64.tar.gz进行解压,解压后利用剪切命令mv将jdk放到/usr/java目录下。
2.利用apt-get install vim命令安装vim文本编辑器,cd到/etc目录下,利用vim profile修改该文件加入JAVA的环境变量,打开profile文件后在最后添加如下文本:
export JAVA_HOME=/usr/java/jdk1.8.0_73
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
添加完成后,在terminal中输入source profile使得环境变量生效。
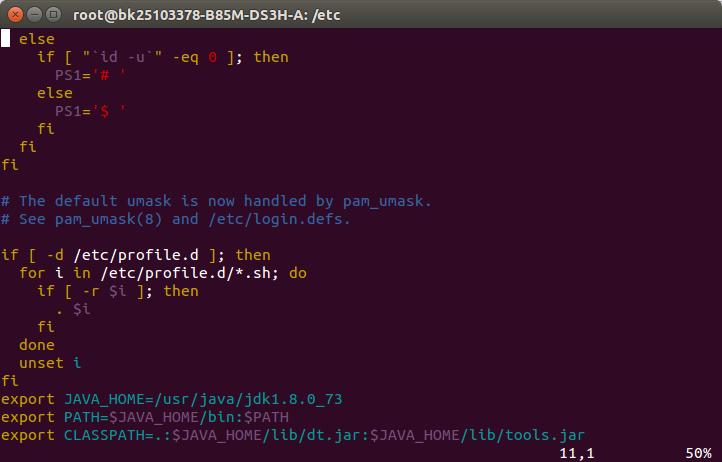
3.测试JAVA是否配置成功,在terminal中输入java -version如果出现如下信息即成功。

安装Hadoop
hadoop的安装主要参考官网上的伪分布式安装教程,参考网址:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
1.安装ssh和rsync,通过以下两个命令:
$ sudo apt-get install ssh
$ sudo apt-get install rsync
2.cd到hadoop-2.6.4.tar.gz的下载目录,利用tar -xf 命令进行解压,将解压的文件夹利用mv命令剪切到目录/opt下,对于spark,scala都类似这样操作,不再累赘。
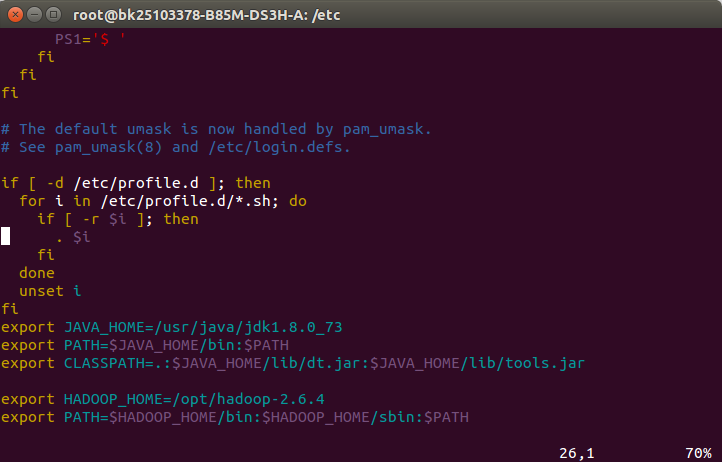
3.编辑文件/etc/profile,添加hadoop的环境变量,记得source profile
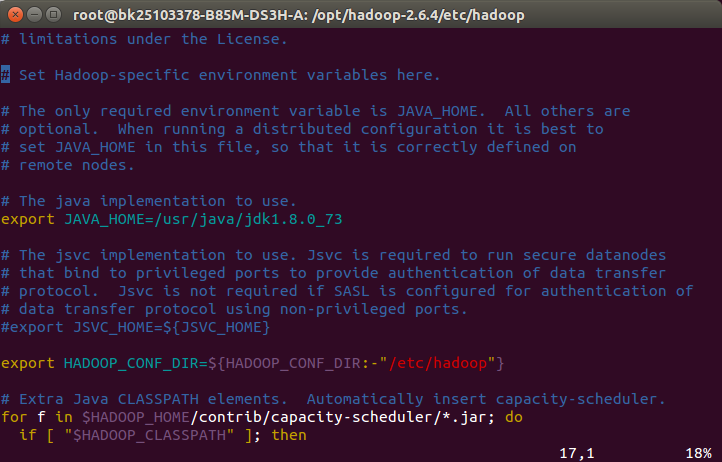
4.添加完hadoop环境变量后,cd到目录/opt/hadoop-2.6.4/etc/hadoop/,修改hadoop-env.sh文件,定义如下变量:
export JAVA_HOME=/usr/java/latest
5.伪分布式还需要修改etc/hadoop/core-site.xml文件为:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改etc/hadoop/hdfs-site.xml文件为:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
6.让ssh访问不受限制,需要如下设置,首先输入ssh localhost检查是否能不需要密码就能完成ssh localhost,如果不能需要如下生成秘钥:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
7.以上步骤完成后,hadoop的伪分布式就算完成了,然后就可以测试一下是否安装成功,可以查看网址http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html中的Execution部分。
安装Scala
安装scala比较容易,直接将解压后的scala-2.11.7文件夹放置在/opt目录下,然后修改etc/profile目录增加Scala所需环境变量就可以了。
1.vim etc/profile增加环境变量
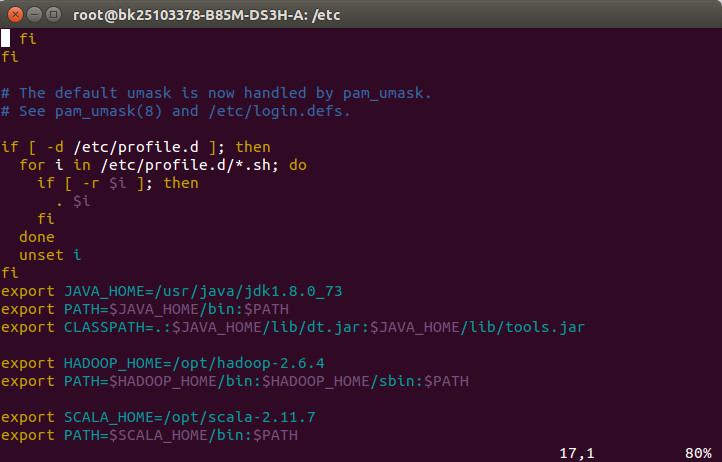
2.利用命令scala -version检查是否配置成功,如果出现如下信息就代表成功。
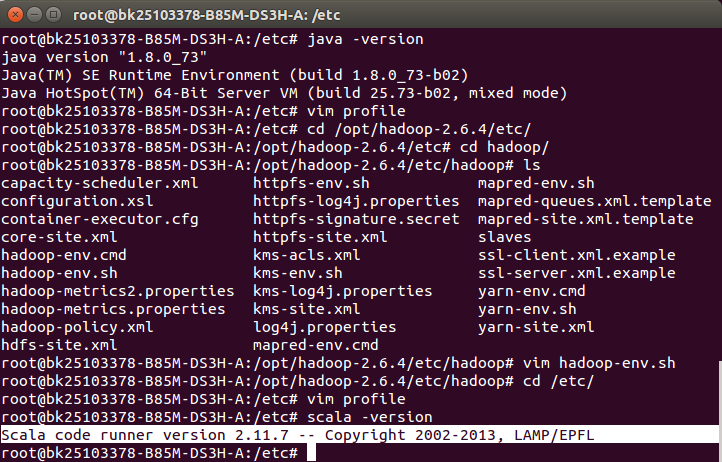
安装Spark
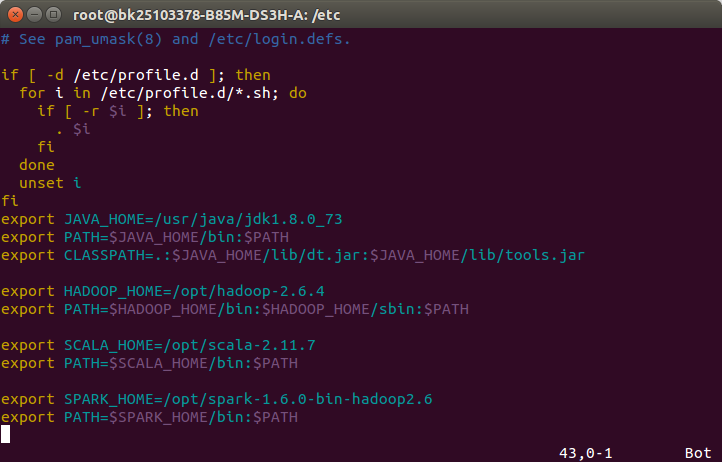
1.将下载好的spark用命令tar -xf进行解压后剪切mv到某目录下后,配置spark环境变量如下:
export SPARK_HOME=/opt/spark-1.6.0-bin-hadoop2.6
export PATH=$SPARK_HOME/bin:$PATH
2.配置spark,参考网址:http://www.thebigdata.cn/Hadoop/28957.html,先修改spark-env.sh文件:
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
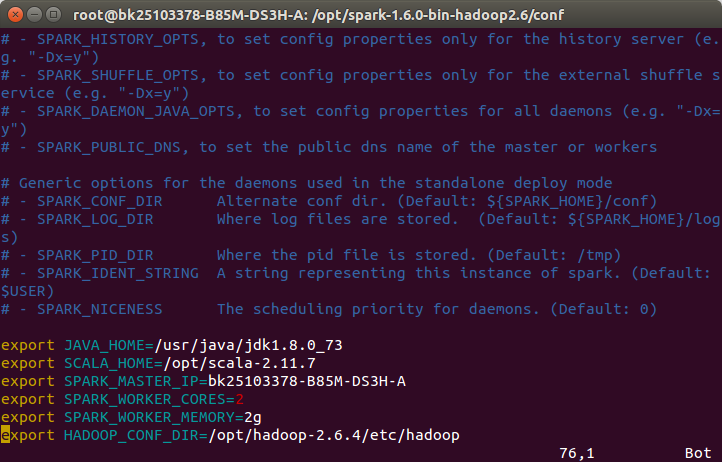
添加Spark的配置信息
export JAVA_HOME=/usr/java/jdk1.8.0_73
export SCALA_HOME=/opt/scala-2.11.7
export SPARK_MASTER_IP=bk25103378-B85M-DS3H-A #主机名
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=2g
export HADOOP_CONF_DIR=/opt/hadoop-2.6.4/etc/hadoop
修改slaves文件:
cp slaves.template slaves
vim slaves
添加节点:
127.0.1.1 bk25103378-B85M-DS3H-A
3.最后参考网址:http://www.thebigdata.cn/Hadoop/28957.html来启动spark检查是否配置成功即可。
Ubuntu 14.04 LTS 安装 spark 1.6.0 (伪分布式)-26号开始的更多相关文章
- ubuntu 14.04 lts安装教程:u盘安装ubuntu 14.04 lts步骤
绿茶小编带来了ubuntu 14.04 lts安装教程,下文详细讲解了u盘安装ubuntu 14.04 lts的步骤,很简单,只需要一个工具就能够轻松使用u盘安装ubuntukylin 14.04系统 ...
- Ubuntu 14.04 LTS 安装和配置Bochs
Ubuntu 14.04 LTS 安装和配置Bochs 系统是:Ubuntu 14.04 LTS 64位 安装的是:bochs-2.6.8 Bochs 需要在 X11 环境下运行,因此你的 ...
- Ubuntu 14.04 LTS 安装Docker
Docker官方是有很详细的安装文档(https://docs.docker.com/engine/installation/ubuntulinux/),这里做了一个Ubuntu 14.04 LTS中 ...
- Ubuntu 14.04 LTS 安装Docker(转)
转自:https://www.cnblogs.com/leolztang/p/5097278.html Docker官方是有很详细的安装文档(https://docs.docker.com/engin ...
- Ubuntu 14.04 LTS 安装 Juno 版 OpenStack Keystone
本文介绍如何在Ubuntu 14.04 LTS 上安装Juno版的Keystone, 我们采用的是手动安装的方式, 同时仅针对OpenStack的身份与访问管理系统Keystone. 事实上OpenS ...
- Ubuntu 14.04 LTS 安装 VNC Viewer
1.修改镜像源: /etc/apt/sources.list将"http://archive.ubuntu.com/ubuntu/"替换为: http://cn.archive.u ...
- Ubuntu 14.04 LTS 安装 NVIDIA 显卡驱动后的屏幕亮度调节问题
安装 Ubuntu,对于 NVIDIA 显卡,默认情况下会使用第三方开源驱动,并且一般情况下,第三方开源驱动和系统兼容性更好.由于 NVIDIA 显卡驱动不是开放的,所以对 Linux 系统的原生支持 ...
- ubuntu 14.04 LTS 安装ss客户端
附: 配置pac模式 ss客户端 ss客户端 前提环境 python (用最新的就行) pip (注:python工具) build-essential 以上可以通过一条命令解决: sudo apt- ...
- Zabbix 3.0 for Ubuntu 14.04 LTS 安装
准备工作 apt-get install gettextapt-get install unzipapt-get install rar一.安装主程序 代码: 全选wget http://repo.z ...
随机推荐
- dom4j读取某个元素的某个属性
一.dom4j介绍 dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的.dom4j是一个非常非常优秀的Java XML API,具有性能优异.功能强大和极端易用使用的特点, ...
- Maven 的classifier的作用
直接看一个例子,maven中要引入json包,于是使用了 <dependency> <groupId>net.sf.json-lib</groupId> <a ...
- 基于Zabbix IPMI监控服务器硬件状况
基于Zabbix IPMI监控服务器硬件状况 zabbix ipmi 公司有多个分部,且机房没有专业值班,机房等级不够.在这种情况下,又想实时监控机房环境,于是使用IPMI方式来达到目的.由于之前已经 ...
- codePrinter
3天前,荆老师给了我一台打印机,让我完成省赛代码打印系统的测试. 打印机型号为 HP P1007,算是一台比较老的打印了. 本文记录了从打印机驱动安装到代码打印WEB部署的全过程 1. 安装打印机驱动 ...
- IBM云的商务动作之我见(2):IBM 和 VMware 战略合作推进混合云
本系列文章基于公开信息,对IBM云的近期商务动作比如收购.战略合作.整合等,给出本人的快速分析,仅仅代表本人个人观点,和本人所在的公司和所在的岗位没有任何关系: (1)IBM 收购 Blue Box ...
- BZOJ 1036: [ZJOI2008]树的统计Count [树链剖分]【学习笔记】
1036: [ZJOI2008]树的统计Count Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 14302 Solved: 5779[Submit ...
- NOIP2013火柴排队[逆序对]
题目描述 涵涵有两盒火柴,每盒装有 n 根火柴,每根火柴都有一个高度. 现在将每盒中的火柴各自排成一列, 同一列火柴的高度互不相同, 两列火柴之间的距离定义为: ∑(ai-bi)^2 其中 ai 表示 ...
- Google Material Design的图标字体使用教程
使用教程 1. 打开Material icons下载页 2. 选择要下载的图标 (目前不能多选>_<) 3.选择要下载的格式即可 图标字体使用教程 [方法一] STEP 1: 引入字体文件 ...
- [随记]Eval的连接方法
在 .NET 3.5 及以下版本中,如下做法是错误的: <asp:Label ID="_column" runat="server" Text='栏目 I ...
- jQuery基础课程
环境搭建 搭建一个jQuery的开发环境非常方便,可以通过下列几个步骤进行. 下载jQuery文件库 在jQuery的官方网站(http://jquery.com)中,下载最新版本的jQuery文件库 ...