Ai 文本生成式大模型 基础知识
提示工程-RAG-微调

工程当中也是这个次序 提示词工程 RAG 微调
- 先问好问题
- 再补充知识
- 最后微调模型

RAG相关技术细节
- 选择合适的 Chunk 大小对 RAG 流程至关重要。
- Chunk 过大:检索精度下降、浪费 Prompt(token) 空间;过小:信息太碎、检索和拼接(embedding)成本高。
- 综合文档结构、任务需求和模型限制等因素,通常选择数百到一千字左右进行切分。
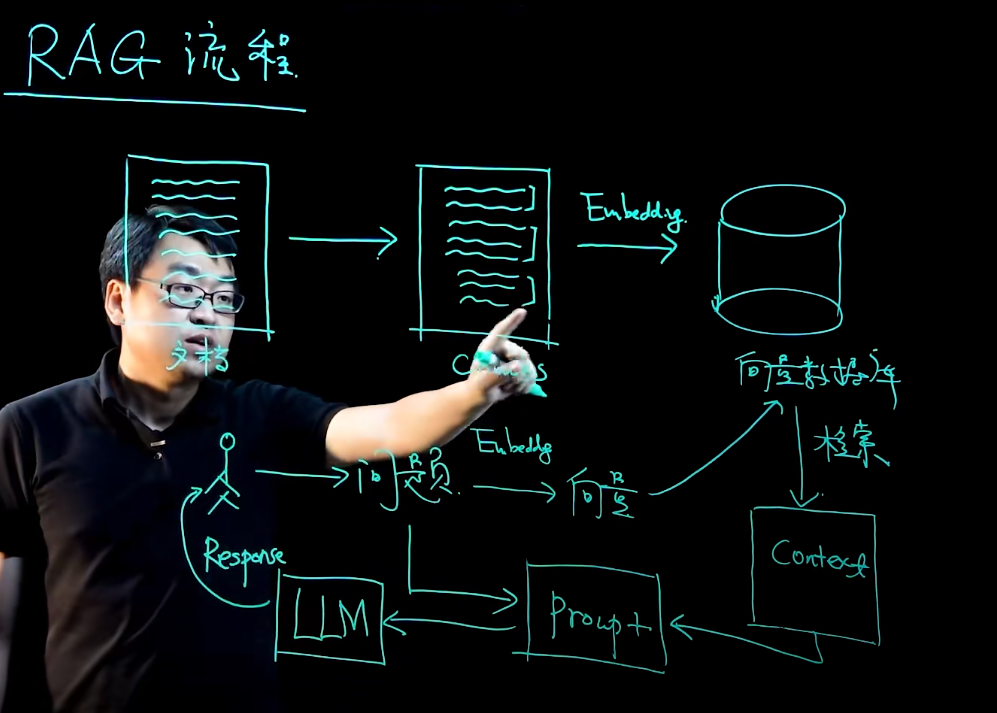
将文档拆分为合适大小的 Chunk 并向量化存入向量数据库;当用户提出问题时,也将问题向量化并检索相关片段,然后与提示一起传给大语言模型生成答案。
需注意事项,可改变rag结果
- 文档选择(ppt pdf excel)
- chunks大小
- embeding选择
- 用户的问题需要进一步处理
- 向量数据库检索
- raking拿到精排的信息,对相关信息进行排序
- prompt设计
- 使用什么样的大模型LLM (通用大模型还是开源大模型+微调)
- 回复直接返回还是二次处理
LoRA微调vs全量调整
模型微调,有些时候发现模型在某一个方面能力不够,对模型的改动

全量微调 每个参数都要通过学习的方法得出来 100亿参数要找100亿数得到新的结果
张三写文章,写了2000字,他本人比较啰嗦,还写了重复性的内容。不够简洁,传达的内容是有限的。
怀疑大模型的千亿参数的价值性
大模型学到的千亿参数,但他传达的信息是否还是非常有限?那么全量微调的话可能会浪费资源
“LoRA 微调不会直接修改原有的大模型参数,而是通过在其上叠加一组可训练的低秩矩阵(和,用较小的参数量来完成微调,从而在推理时得到新的有效权重(原权重 + ×)。”
二次训练有可能削弱原始能力
成本

针对大模型要处理的问题 收集合理的数据
微调需要多少gpu
全量微调的消耗
微调1B模型(10亿参数),16bit=2byte(fp16)
微调时哪些会用到显存
- 模型本身(模型多大就需要多少显存): 2GB
- Gradient: 2GB(和model weight类似)
- Optimizer state: 8G(保守为Gradien4倍)
- Activation: ~
model size x (~6) = 12GB
高效微调 估算
原模型保持不变 + 更少量参数(2%,<%1) => 新模型
- model weight 保持不变 一样载入GPU
- 小模块为Adapter weight 0.05GB
- Grandient Optimizer 0.25GB
QLoRA量化模型进一步缩小
SFT模型训练
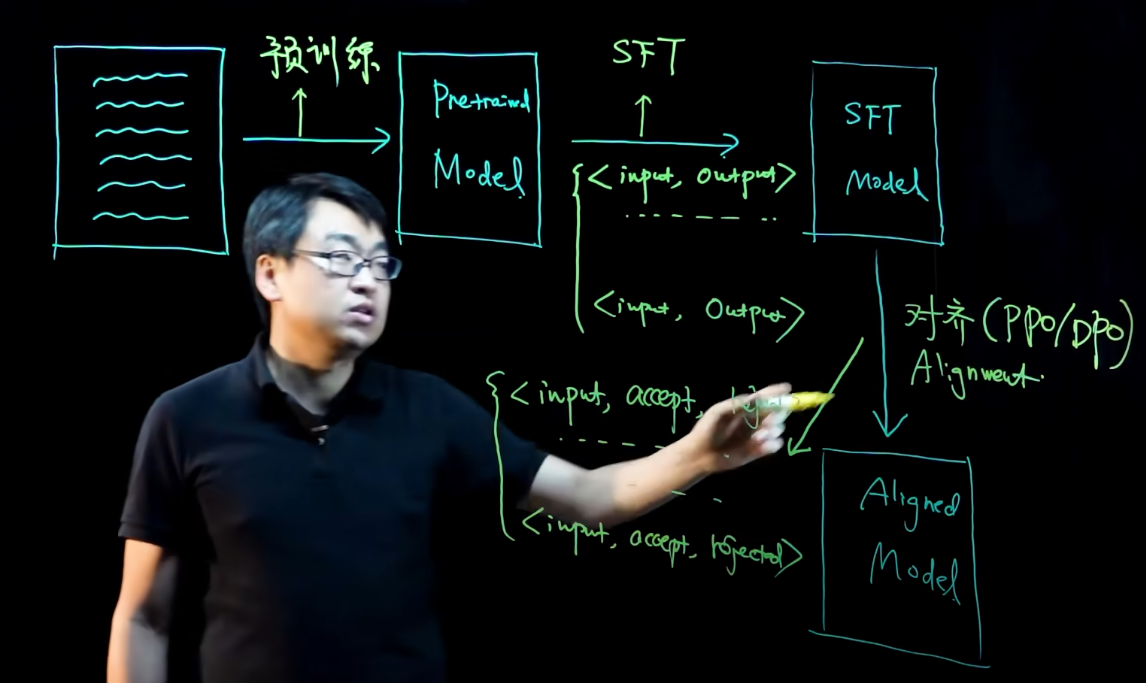
- 模型预训练 被海量数据训练 通用大模型
- 微调,私有化数据改良大模型 SFT(想要什么答案,放大模型),SFTmodel上线后 点赞或点踩 然后对其这些数据,然后再优化
大模型生成

被训练的大模型对文本有一定的理解能力
当你输入文字,会被大模型转化为向量,来对应
最后一个字会生成一个黑盒子,来决定下一个词是什么,黑盒子会一直嫁接到最后一个词
生成模型每个字都是一个个蹦出来的。具有随机性意味着不可控 不可控->产生幻觉
大模型调参
TopK 筛掉不可能出现的单词,控制随机性。从黑盒子里考虑概率最大
Topk每次从单个盒子中取出概率最大的前几 k=数量
TopP 加大候选集,让所有token出现的概率加起来等于P值,列如等于0.7
P=0.7表示黑盒子里前30%被圈定
大模型量化与蒸馏
量化(Quantization):降低精度(FP16 → INT8 → INT4)或减少参数(671B → 70B)来减少显存占用(降低精度会带来一定的信息损失)。
蒸馏(Distillation):用大模型训练小模型,使其在低参数量的情况下保持较高性能。
DeepSeek vs Qwen:DeepSeek 产生的数据被 Qwen 用于学习,因此 Qwen 无法超越 DeepSeek。
在部署 LLM 时,可以 先量化(降低精度),再蒸馏(减少参数),从而在显存占用和推理速度之间找到最优平衡点。
模型推理需要的显存
- 模型大小 多少参数 x 多少精度
- KV Cache 加速生成,随着每个单词的生成,会增加缓存->每个token显存 x token数
(base) root@DESKTOP-GP1B0QA:~/.cache/huggingface/hub# du -sh models--deepseek-ai--DeepSeek-R1-Distill-Qwen-14B/
28G models--deepseek-ai--DeepSeek-R1-Distill-Qwen-14B/
(base) root@DESKTOP-GP1B0QA:~/.cache/huggingface/hub# cd models--deepseek-ai--DeepSeek-R1-Distill-Qwen-14B/
(base) root@DESKTOP-GP1B0QA:~/.cache/huggingface/hub/models--deepseek-ai--DeepSeek-R1-Distill-Qwen-14B# ls
blobs refs snapshots
(base) root@DESKTOP-GP1B0QA:~/.cache/huggingface/hub/models--deepseek-ai--DeepSeek-R1-Distill-Qwen-14B#
huggingface deepseek-14b fp16未量化14B有 28G
PS C:\Users\DK> ollama show deepseek-r1:14b
Model
architecture qwen2
parameters 14.8B
context length 131072
embedding length 5120
quantization Q4_K_M
Parameters
stop "<|begin▁of▁sentence|>"
stop "<|end▁of▁sentence|>"
stop "<|User|>"
stop "<|Assistant|>"
License
MIT License
Copyright (c) 2023 DeepSeek
PS C:\Users\DK> ollama show deepseek-r1:32b
Model
architecture qwen2
parameters 32.8B
context length 131072
embedding length 5120
quantization Q4_K_M
Parameters
stop "<|begin▁of▁sentence|>"
stop "<|end▁of▁sentence|>"
stop "<|User|>"
stop "<|Assistant|>"
License
MIT License
Copyright (c) 2023 DeepSeek
PS C:\Users\DK> ollama list
NAME ID SIZE MODIFIED
haimianbb:latest ec9919f2d5e3 3.6 GB 3 days ago
deepseek-qwen16b:latest 4d3e7e769b60 29 GB 9 days ago
deepseek-r1:7b 0a8c26691023 4.7 GB 11 days ago
bge-m3:latest 790764642607 1.2 GB 12 days ago
deepseek-coder-v2:latest 63fb193b3a9b 8.9 GB 2 weeks ago
gemma:latest a72c7f4d0a15 5.0 GB 2 weeks ago
qwen:14b 80362ced6553 8.2 GB 2 weeks ago
llama3:latest 365c0bd3c000 4.7 GB 2 weeks ago
deepseek-r1:70b 0c1615a8ca32 42 GB 2 weeks ago
nomic-embed-text:latest 0a109f422b47 274 MB 2 weeks ago
deepseek-r1:32b 38056bbcbb2d 19 GB 2 weeks ago
deepseek-r1:14b ea35dfe18182 9.0 GB 2 weeks ago
PS C:\Users\DK>
#Q4_K_M 代表的是 4-bit 量化,使用了一种高效的量化方法 (GPTQ Q4_K_M 量化方案)
ollama int4量化需要9GB


| Token 数量 | FP16 KV Cache(2 Byte) | FP8 KV Cache(1 Byte) | INT4 KV Cache(0.5 Byte) |
|---|---|---|---|
| 512 | 3GB | 1.5GB | 0.75GB |
| 1024 | 6GB | 3GB | 1.5GB |
| 2048 | 12GB | 6GB | 3GB |
| 4096 | 24GB (OOM) | 12GB (勉强) | 6GB |
| 8192 | 48GB (OOM) | 24GB (OOM) | 12GB |
1. 适合使用这个 KV Cache 计算表的模型
7B 级别 Transformer 模型:
LLaMA 2-7B / LLaMA 3-7B
DeepSeek 7B
Mistral 7B
ChatGLM3-6B
Baichuan 7B
Qwen-7B
这些模型通常有 64 个 Attention Heads,每个 Head 维度为 128
RAG 增加了输入 Token 数
- RAG 需要从外部知识库(如向量数据库)检索相关信息,并将其作为额外的上下文提供给 LLM。
- 这意味着 输入序列(prompt + retrieved context)变长了,从而 需要存储更多 KV Cache。
Ai 文本生成式大模型 基础知识的更多相关文章
- OSI七层模型基础知识及各层常见应用
OSI Open Source Initiative(简称OSI,有译作开放源代码促进会.开放原始码组织)是一个旨在推动开源软件发展的非盈利组织.OSI参考模型(OSI/RM)的全称是开放系统互 ...
- 【数据库上】 第四讲 E-R模型基础知识
第四讲 E-R模型基础知识 一.数据库设计过程 数据库设计的关键阶段? 各个阶段设计的主要任务? 基础条件:清楚一个应用系统的功能需求与数据需求(直接与用户交互.数据流程图示例/UML类图等) 核心阶 ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- AI探索(一)基础知识储备
AI的定义 凡是通过机器学习,实现机器替代人力的技术,就是AI.机器学习是什么呢?机器学习是由AI科学家研发的算法模型,通过数据灌输,学习数据中的规律并总结,即模型内自动生成能表达(输入.输出)数据之 ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
- 大数据基础知识问答----hadoop篇
handoop相关知识点 1.Hadoop是什么? Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速 ...
- JMM模型基础知识笔记
概述 内存模型可以理解为在特定的操作协议下,对特定的内存或者高速缓存进行读写访问的过程抽象,不同架构下的物理机拥有不一样的内存模型,Java虚拟机也有自己的内存模型,即Java内存模型(JavaMem ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- 前端开发:css基础知识之盒模型以及浮动布局。
前端开发:css基础知识之盒模型以及浮动布局 前言 楼主的蛮多朋友最近都在学习html5,他们都会问到同一个问题 浮动是什么东西? 为什么这个浮动没有效果? 这个问题楼主已经回答了n遍.今天则是把 ...
- HTML+CSS基础知识(2)选择器的使用、盒子模型的讲解、列表的使用
文章目录 1.CSS基础知识 2.css样式 2.1.代码: 2.2 测试结果 3.CSS的语法 3.1 代码 4.块元素和行内元素 4.1 代码 4.2 测试结果 5.常用的选择器 5.1 代码块 ...
随机推荐
- Elm 和 Jetpack Compose 殊途同归及 MVVM 缺点分析
Html.lazy · An Introduction to Elm 可能搞 vdom 的都会到 lazy renderer 这一步,react 可能也可以这么搞或者已经这么搞了我不知道,Elm 提到 ...
- Qt编写物联网管理平台31-用户权限管理
一.前言 随着需求的不断变化,功能的增多,在用户信息这块,除了需要用户登录退出验证以外,还需要有个简单的用户权限逻辑处理,比如限定某些用户只有查看权限,没有删除记录.清空记录.系统设置的权限,与之相对 ...
- Qt开发经验小技巧101-110
如果需要在尺寸改变的时候不重绘窗体,则设置属性即可 this->setAttribute(Qt::WA_StaticContents, true); 这样可以避免可以避免对已经显示区域的重新绘制 ...
- Appium_iOS_Safari测试脚本(2)
经过多次调试,在Safari上的测试脚本终于可以运行了,不过部分元素还是无法识别,还需要继续调试: #!/usr/bin/env/python # -*-coding:utf-8-*- import ...
- Index - 此处的诗
虚构往事 正篇 嗯--本来发过两篇,但深愧于仓促的处理和并未完善的细节设定,隐藏了. 大概会是一个中篇的科幻故事,世界设定已经完善了(Shaya 可以作证!),但近期可能没有精力动笔. 番外 ...
- 工作流程调度器-DolphinScheduler
1.DolphinScheduler简介 Apache DolphinScheduler](https://dolphinscheduler.apache.org/)(目前处在孵化阶段)是一个分布式. ...
- 学Shiro完结版-3
第八章 拦截器机制--<跟我学Shiro> 8.1 拦截器介绍 Shiro使用了与Servlet一样的Filter接口进行扩展:所以如果对Filter不熟悉可以参考<Servlet3 ...
- oracle数据库 关闭归档模式
-- 1. 连接到数据库 CONNECT / AS SYSDBA; -- 2. 确保数据库处于mount状态 SHUTDOWN IMMEDIATE; STARTUP MOUNT; -- 3. ...
- Amoro提供grafana的metrics介绍
一.指标内容 +| Metric Name | Type | Tags | Description | +|---------------------------------------------- ...
- Atcoder ABC387F Count Arrays 题解 [ 绿 ] [ 基环树 ] [ 树形 dp ] [ 前缀和优化 ]
Count Arrays:一眼秒的计数题. 思路 显然,把小于等于的条件化为大的向小的连单向边,每个数的入度都是 \(1\),就会形成一个基环树森林. 那么考虑这个环上能填什么数.因为所有数都小于等于 ...