使用apache amoro + trino+minio搭建iceberg数据湖架构
使用apache amoro + trino+minio搭建iceberg数据湖架构
以下是基于 Apache Amoro + Trino + MinIO 搭建 Iceberg 数据湖架构的核心步骤和关键配置:
架构组件角色
- MinIO:提供兼容 S3 API 的云原生对象存储,作为 Iceberg 表的底层存储系统。官方文档:
- Apache Iceberg:表格式层,负责数据文件管理、ACID 事务支持及元数据版本控制。
- Apache Amoro:湖仓管理系统,提供表管理、自动优化(如小文件合并)及多引擎协调(Trino/Flink/Spark)。官方文档:https://amoro.apache.org/quick-start/
- Trino:分布式 SQL 查询引擎,用于高性能分析查询。官方文档:https://trino.io/docs/current/connector/iceberg.html
另外,此文章不包括ETL数据写入到apache iceberg,这一章需要应用 apache flink + DolphinScheduler(调度系统),请自行研究。
部署流程
以下是使用docker-compose搭建Apache Amoro、MinIO和Trino的集成环境方案,可用于日常开发环境。
确保已安装Docker 27.0.3 和Docker Compose。
把下面的yaml保存到docker-compose.yml的文件中:
version: "3"
services:
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
amoro_network:
aliases:
- warehouse.minio
ports:
- 9001:9001
- 9000:9000
command: [ "server", "/data", "--console-address", ":9001" ]
amoro:
image: apache/amoro
container_name: amoro
ports:
- 8081:8081
- 1630:1630
- 1260:1260
environment:
- JVM_XMS=1024
networks:
amoro_network:
volumes:
- ./amoro:/tmp/warehouse
command: ["/entrypoint.sh", "ams"]
tty: true
stdin_open: true
trino:
image: trinodb/trino:419
container_name: trino
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
volumes:
- ./example.properties:/etc/trino/catalog/example.properties
networks:
amoro_network:
aliases:
- warehouse.trino
ports:
- 8080:8080
networks:
amoro_network:
driver: bridge
接下来,在docker-compose.yml所在的目录下创建example.properties文件:
connector.name=iceberg
iceberg.catalog.type=rest
iceberg.rest-catalog.uri=http://<IP地址>:1630/api/iceberg/rest
iceberg.rest-catalog.warehouse=<amoro 创建的 iceberg catalog name>
fs.native-s3.enabled=true
s3.endpoint=http://<IP地址>:9000
s3.region=us-east-1
s3.aws-access-key=admin
s3.aws-secret-key=password
最后一步骤:使用以下命令启动docker容器:
docker-compose up -d
启动之后,trino容器可能会出现启动失败。不要着急,接下来将amoro配置完,重启容器即可。
配置
minio 创建 bucket
打开http://localhost:9000在浏览器中,输入admin/password登录minio界面。
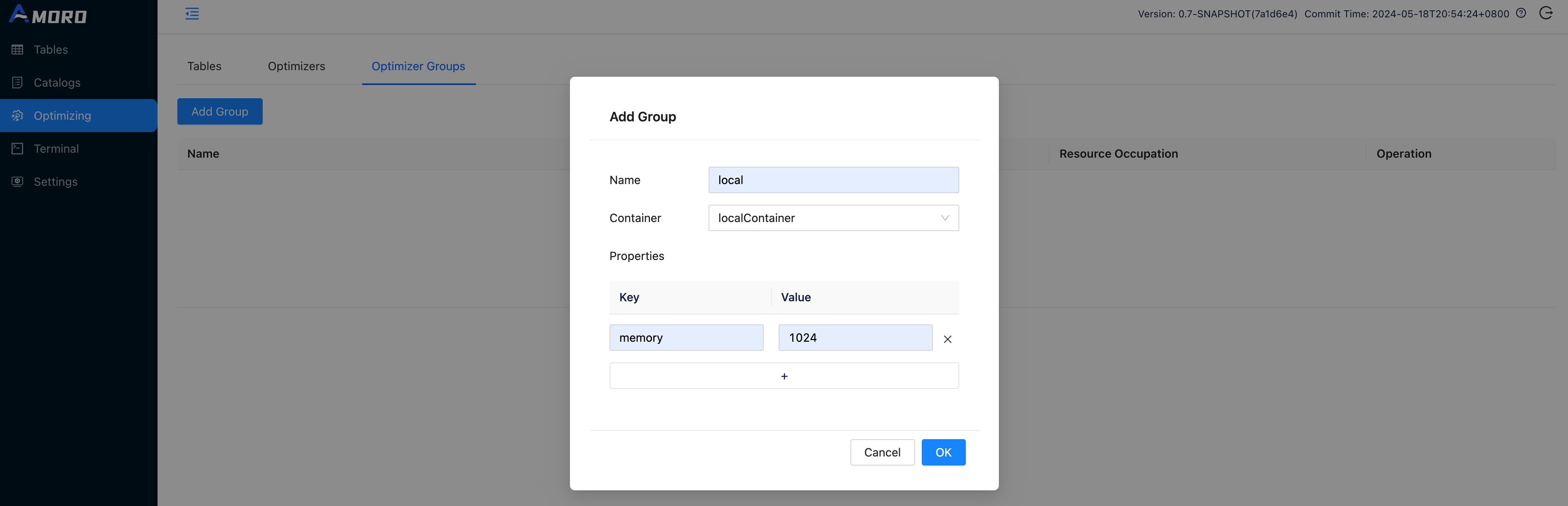
amoro 配置
Create optimizer group
Open http://localhost:1630 in a browser, enter admin/admin to log in to the dashboard.
Click on Optimizing in the sidebar, choose Optimizer Groups and click Add Group button to create a new group befre creating catalog
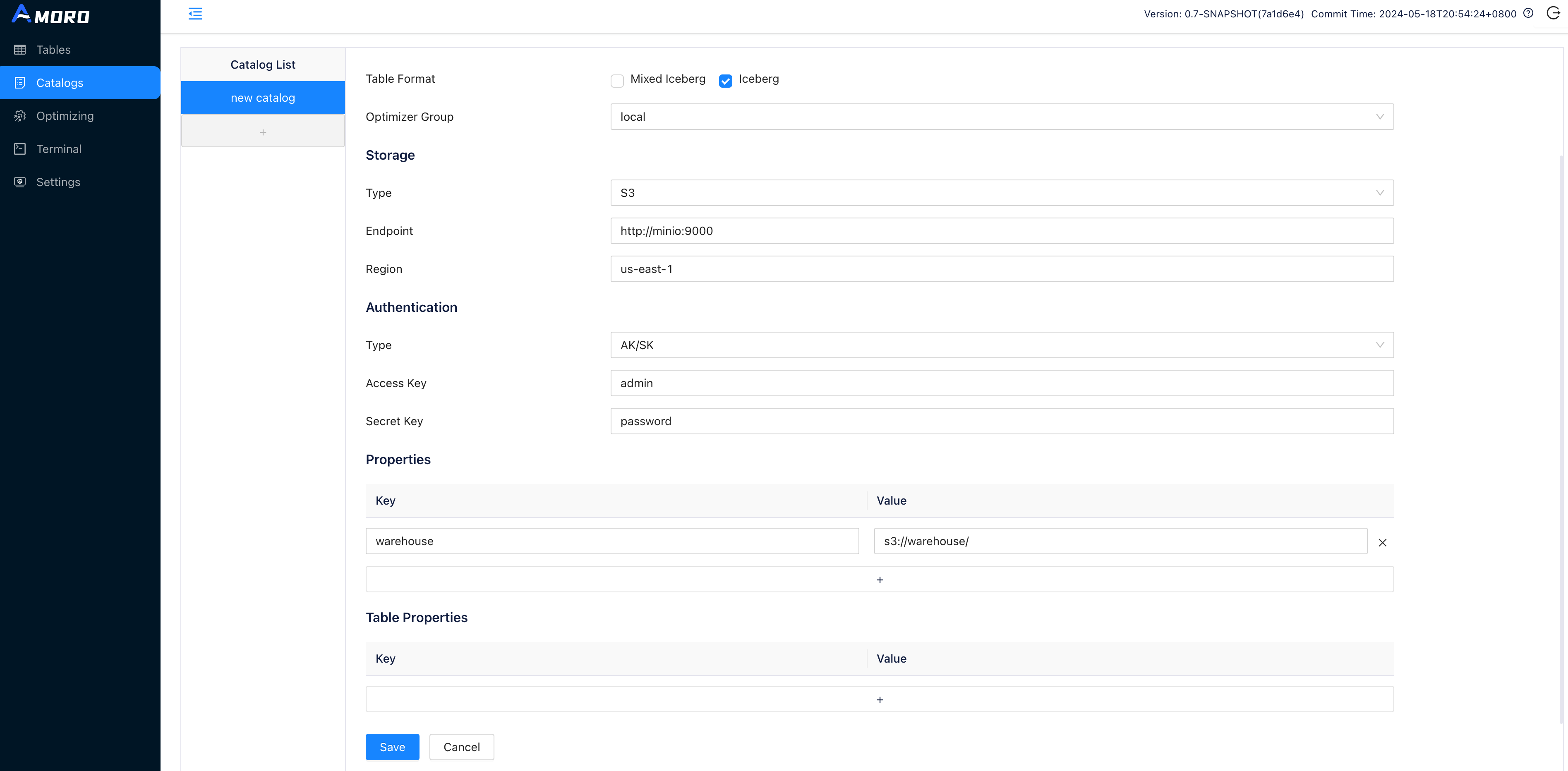
Create catalog
Click on Catalogs in the sidebar, click on the + button under Catalog List to create a test catalog, and name it to demo_catalog:
o use the Iceberg Format, select Type as Internal Catalog, and choose Iceberg as Table Format.
按照上面配置的,修改example.properties文件。然后执行以下命令:
docker stop tirno
docker rm trino
docker-compose up trino
Demo steps
Initialize tables
Click on amoro system Terminal in the sidebar, you can create the test tables here using SQL. Terminal supports executing Spark SQL statements for now.
CREATE DATABASE IF NOT EXISTS db;
CREATE TABLE IF NOT EXISTS db.tb_users (
id INT,
name string,
ts TIMESTAMP
) USING iceberg
PARTITIONED BY (days(ts));
INSERT OVERWRITE db.tb_users VALUES
(1, "eric", timestamp("2022-07-01 12:32:00")),
(2, "frank", timestamp("2022-07-02 09:11:00")),
(3, "lee", timestamp("2022-07-02 10:11:00"));
SELECT * FROM db.user;
Click on the RUN button uppon the SQL editor, and wait for the SQL query to finish executing. You can then see the query results under the SQL editor.
Initialize tables
start up the docker containers with this command:
docker exec -it tirno trino
trino> show catalogs;
Catalog
---------
example
jmx
memory
system
tpcds
tpch
(6 rows)
trino> show schemas in example;
Schema
--------------------
db
information_schema
(2 rows)
trino> show tables in example.db;
Table
-------
tb_users
(1 row)
trino> select * from example.db.tb_users;
id | name | ts
----+-------+--------------------------------
1 | eric | 2022-07-01 12:32:00.000000 UTC
2 | frank | 2022-07-02 09:11:00.000000 UTC
3 | lee | 2022-07-02 10:11:00.000000 UTC
(3 rows)
到此为止,我们的架构就搭建完成。
关键注意事项
- 首次启动需在Amoro中创建MinIO存储配置
- Trino查询前需在Amoro中创建表并同步元数据
- 生产环境建议配置持久化卷和网络隔离
使用apache amoro + trino+minio搭建iceberg数据湖架构的更多相关文章
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- 通过Apache Hudi和Alluxio建设高性能数据湖
T3出行的杨华和张永旭描述了他们数据湖架构的发展.该架构使用了众多开源技术,包括Apache Hudi和Alluxio.在本文中,您将看到我们如何使用Hudi和Alluxio将数据摄取时间缩短一半.此 ...
- 知名大厂如何搭建大数据平台&架构
今天我们来看一下淘宝.美团和滴滴的大数据平台,一方面进一步学习大厂大数据平台的架构,另一方面也学习大厂的工程师如何画架构图.通过大厂的这些架构图,你就会发现,不但这些知名大厂的大数据平台设计方案大同小 ...
- 使用Apache Hudi构建大规模、事务性数据湖
一个近期由Hudi PMC & Uber Senior Engineering Manager Nishith Agarwal分享的Talk 关于Nishith Agarwal更详细的介绍,主 ...
- 使用 Iceberg on Kubernetes 打造新一代云原生数据湖
背景 大数据发展至今,按照 Google 2003年发布的<The Google File System>第一篇论文算起,已走过17个年头.可惜的是 Google 当时并没有开源其技术,& ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- Apache 首次亚洲在线峰会: Workflow & 数据治理专场
背景 大数据发展到今天已有 10 年时间,早已渗透到各个行业,数据需 求越来越多,这使得大数据 业务间的依赖关系也越来越复杂,另外也相信做数据的伙伴肯定对如何治理数据也是痛苦之至,再加上现今云原生时代 ...
- COS 数据湖最佳实践:基于 Serverless 架构的入湖方案
01 前言 数据湖(Data Lake)概念自2011年被推出后,其概念定位.架构设计和相关技术都得到了飞速发展和众多实践,数据湖也从单一数据存储池概念演进为包括 ETL 分析.数据转换及数据处理的下 ...
- MinIO 搭建
MinIO 搭建 MinIO 是一个基于 Apache License v2.0 开源协议的对象存储服务.它兼容亚马逊 S3 云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片.视频.日志文 ...
随机推荐
- EmlBuilder:一款超轻量级的EML格式电子邮件阅读和编辑工具
EmlBuilder 是一款超轻量级的电子邮件阅读和编辑工具,针对EML格式的文件具有非常强大的解析和容错能力,可实现超文本邮件的编写,并具备内嵌图片的编辑功能.该工具内部使用EmlParse对电子邮 ...
- Linux运维面试题之:Root密码忘记如何解决
目录 6.5 Root密码忘记如何解决 6.5.1 系统自带救援模式 6.5.2 U盘.光盘救援系统 6.5 Root密码忘记如何解决 解决方案有两种:自救,别人救 解决方案 应用场景 1️⃣ 系统自 ...
- NSIS打包脚本模板
; Script generated by the HM NIS Edit Script Wizard. ; HM NIS Edit Wizard helper defines !define PRO ...
- 关于TFDMemtable的使用场景
TFDMemtable是FireDAC框架的内存数据集组件.也是处理数据最快速的组件.简单说是把数据快储在内存中进行处理,因此其数据是和数据源是隔离的. 使用场景: 1.把一些少量的经常会使用的数据放 ...
- Web前端入门第 31 问:CSS background 元素背景图用法全解
background 可设置背景色.渐变.背景图等,本文主要讲解背景图片的用法. 背景顾名思义就是背后的景色,始终居于元素背后,元素永远站在背景的身前. 本文示例中所使用的图片: background ...
- windows下jdk版本切换(bat)
1.jdk下载 Oracle官网 https://www.oracle.com/cn/ 资源->下载->Java下载 jdk当前最新版本 jdk22版本 jdk8版本 当前页面向下拉 2. ...
- python,下载图片到本地自定文件夹内的方法
比如,我们需要下载下面这张图,图片的网络地址:"https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000 ...
- 一条 SQL 语句在 MySQL 中的执行过程
一条 SQL 语句在 MySQL 中的执行过程 当一条 SQL 语句被提交到 MySQL 时,它会经历多个步骤,包括解析.优化.执行等.以下以 SELECT 语句为例,详细描述整个执行流程. 1. 客 ...
- web自动化的三大切换
元素有时在另一个页面里查找元素却报错找不到元素,可能是因为要查找的元素不在原来所在的页面. 一.iframe切换 有些定位元素定位不到,是因为元素在新的iframe页面里,但是driver还停留在原来 ...
- xna 渲染3d图片
我们在做一个3d显示的时候为了突出模型的某些部位以及更好的区别某些模块我们需要渲染各种不同的颜色来体现, 下面代码演示: public void loade() { spriteBatch = new ...