明明是同一条SQL,为什么有时候走索引a,有时候却走索引b ?
前言
想象你是一家餐厅的服务员,面前有两个菜单:
- 菜单A:按菜品分类排列(前菜、主菜、甜点)
- 菜单B:按价格从低到高排列
当顾客说:"我要最便宜的川菜"。
你会:
- 先用菜单B找到所有低价菜
- 从中筛选川菜
或者:
- 先用菜单A找到所有川菜
- 再按价格排序
这就是MySQL优化器的日常决策!
明明是同一条SQL,有时候走的索引a,而有时候走的索引b,就是它的锅。
今天这篇文章跟大家一起聊聊,MySQL选错索引的问题,希望对你会有所帮助。
1 一个让程序员崩溃的案例
现在有个需求:查询今年开始已付款的前100个订单。
给status字段创建了索引idx_status。
给create_time字段创建了索引idx_create_time。
查询订单的sql如下:
SELECT * FROM orders
WHERE status = 'paid' -- 状态条件
AND create_time > '2025-01-01' -- 时间条件
ORDER BY amount DESC
LIMIT 100;
周一执行计划如下:
使用索引:idx_status(状态索引)
扫描行数:500行
耗时:0.1秒
周二执行计划如下:
使用索引:idx_create_time(时间索引)
扫描行数:50万行
耗时:8秒
周一只扫描了500行数据,而周二却扫描了50万行数据。
周一耗时0.1秒,而周二耗时却又8秒。
同一SQL在不同时间性能差异80倍!
让我们拆解背后的原因。
2 揭秘优化器的"决策三步曲"
MySQL优化器的决策流程如下:
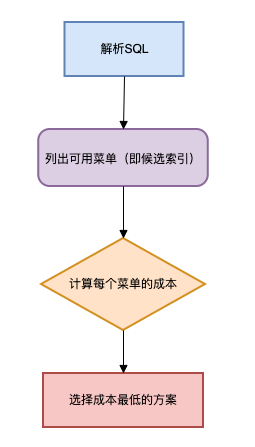
成本计算示例:
| 索引名称 | 预估扫描行数 | 回表次数 | 排序成本 | 总成本 |
|---|---|---|---|---|
| idx_status | 50万 | 50万次 | 需要排序 | 1050分 |
| idx_create_time | 5万 | 5万次 | 无需排序 | 600分 |
根据扫描行数、回表次数、排序成本,计算一个总成本的分数。
优化器会选择总成本更低的idx_create_time索引。
3 导致索引切换的四大真凶
真凶1:数据分布变化
场景还原:
- 周一数据:已支付订单5万条,其中2025年的5万条
- 周二数据:已支付订单50万条,其中2025年的50万条
这个例子中数据分布变化很大,周二的数据,比周一的数据一下子多了45万。
可能会影响总成本的分数。
我们可以通过下面的SQL查看数据分布:
SELECT
COUNT(*) AS total,
SUM(status='paid') AS paid_count,
SUM(create_time>'2023-01-01') AS new_orders
FROM orders;
真凶2:统计信息过期
统计信息过期,就像用去年的地图导航,新修的路不会出现在地图上。
MySQL的"地图"就是统计信息。
我们可以通过ANALYZE TABLE ... DELETE STATISTICS命令删除统计信息:
ANALYZE TABLE orders DELETE STATISTICS;
这时候查询可能变成全表扫描:
EXPLAIN SELECT...
显示type: ALL
那么,如何解决这个问题呢?
使用ANALYZE TABLE命令,刷新统计信息(相当于更新地图):
ANALYZE TABLE orders;
真凶3:索引覆盖度差异
点餐类比:
- 菜单A能直接看到菜品价格 → 无需问厨师(覆盖索引)
- 菜单B只能看到菜品名 → 需要问厨师详情(回表查询)
下面的SQL会走idx_status(需要回表):
SELECT * FROM orders WHERE status='paid';
下面的SQL会走idx_create_time(覆盖索引):
SELECT create_time FROM
orders WHERE create_time>'2023-01-01';
真凶4:索引碎片化
索引碎片化就像书本的目录页被撕破,找内容变得困难。
检查方法:
SHOW TABLE STATUS LIKE 'orders';
查看Data_free字段,值越大碎片越多。
优化方案:
使用ALTER TABLE命令重建索引。
ALTER TABLE orders ENGINE=INNODB;
4 问题排查四步法
第一步:查看当前执行计划
使用EXPLAIN查看当前SQL的执行计划:
EXPLAIN
SELECT * FROM orders
WHERE status='paid'
AND create_time>'2023-01-01';
第二步:检查统计信息
使用SHOW INDEX命令检查索引的统计信息:
SHOW INDEX FROM orders;
关注Cardinality字段,值越接近真实数据越好。
第三步:分析数据分布
使用下面的SQL分析数据分布:
SELECT
COUNT(*) AS total,
AVG(LENGTH(status)) AS status_avg_len
FROM orders;
第四步:追踪优化器思考过程
SET optimizer_trace="enabled=on";
SELECT * FROM orders WHERE ...;
SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
开启optimizer_trace,然后通过INFORMATION_SCHEMA.OPTIMIZER_TRACE表查看追踪优化器思考过程。
5 三大终极解决方案
方案1:引导优化器选择
使用FORCE INDEX强制使用指定索引:
SELECT * FROM orders FORCE INDEX(idx_status) WHERE ...;
方案2:创建更优索引
创建更优的联合索引:
ALTER TABLE orders
ADD INDEX idx_status_create_time(status,create_time);
方案3:定期维护计划
- 定期统计信息更新
- 定期碎片率检查
- 定期索引重建
总结
六个必须检查的点
- WHERE条件字段是否有合适索引
- ORDER BY/GROUP BY是否利用索引排序
- 统计信息是否最新(尤其大表每天更新)
- 是否存在索引碎片(每月检查一次)
- 是否出现索引合并(INDEX_MERGE)
- 是否使用覆盖索引(减少回表)
三条黄金法则
- 二八定律:20%的索引满足80%的查询
- 数据驱动:定期分析查询模式调整索引
- 防御编程:核心查询明确指定索引
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,我的所有文章都会在公众号上首发,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
本文收录于我的技术网站:http://www.susan.net.cn
明明是同一条SQL,为什么有时候走索引a,有时候却走索引b ?的更多相关文章
- oracle里要查看一条sql的执行情况,有没有走到索引,怎么看?索引不能提高效率?
index scan 索引扫描 full table scan是全表扫描 直接explain plan for 还有个set autotrace什么 索引一定能提高执行效率吗? 索引不能提高效率的情况 ...
- XPath注入跟SQL注入差不多,只不过这里的数据库走的xml格式
SQL注入这块不想细聊了,相信很多朋友都听到耳朵长茧,不外乎是提交含有SQL操作语句的信息给后端,后端如果没有做好过滤就执行该语句,攻击者自然可以随意操纵该站点的数据库. 比如有一个图书馆站点book ...
- 腾讯面试:一条SQL语句执行得很慢的原因有哪些?---不看后悔系列
说实话,这个问题可以涉及到 MySQL 的很多核心知识,可以扯出一大堆,就像要考你计算机网络的知识时,问你"输入URL回车之后,究竟发生了什么"一样,看看你能说出多少了. 之前腾讯 ...
- 一条SQL语句执行得很慢的原因有哪些?
说实话,这个问题可以涉及到 MySQL 的很多核心知识,可以扯出一大堆,就像要考你计算机网络的知识时,问你“输入URL回车之后,究竟发生了什么”一样,看看你能说出多少了. 之前腾讯面试的实话,也问到这 ...
- 一条SQL语句在MySQL中如何执行的
本篇文章会分析一个 sql 语句在 MySQL 中的执行流程,包括 sql 的查询在 MySQL 内部会怎么流转,sql 语句的更新是怎么完成的. 在分析之前我会先带着你看看 MySQL 的基础架构, ...
- 一条SQL语句执行得很慢的原因有哪些?(转)
一条 SQL 语句执行的很慢,那是每次执行都很慢呢?还是大多数情况下是正常的,偶尔出现很慢呢?所以我觉得,我们还得分以下两种情况来讨论. 1.大多数情况是正常的,只是偶尔会出现很慢的情况. 2.在数据 ...
- 一条SQL语句在MySQL中是如何执行的
概览 本篇文章会分析下一个sql语句在mysql中的执行流程,包括sql的查询在mysql内部会怎么流转,sql语句的更新是怎么完成的. 一.mysql架构分析 mysql主要分为Server层和存储 ...
- 一条 SQL 语句在 MySQL 中如何执行的
一 MySQL 基础架构分析 1.1 MySQL 基本架构概览 下图是 MySQL 的一个简要架构图,从下图你可以很清晰的看到用户的 SQL 语句在 MySQL 内部是如何执行的. 先简单介绍一下下图 ...
- 一条SQL语句执行得很慢的原因有哪些
说实话,这个问题可以涉及到 MySQL 的很多核心知识,可以扯出一大堆,就像要考你计算机网络的知识时,问你"输入URL回车之后,究竟发生了什么"一样,看看你能说出多少了. 之前腾讯 ...
- 一条SQL语句在MySQL中如何执行
一条SQL语句在MySQL中如何执行 本篇文章会分析一个 sql 语句在 MySQL 中的执行流程,包括 sql 的查询在 MySQL 内部会怎么流转,sql 语句的更新是怎么完成的. 在分析之前我会 ...
随机推荐
- C# Semaphore
1.Semaphore定义Semaphore,是负责协调各个线程, 以保证它们能够正确.合理的使用公共资源.也是操作系统中用于控制进程同步互斥的量. Semaphore常用的方法有两个WaitOne( ...
- Windows编程----CreateProcess函数
CreateProcess函数原型 CreateProcess 函数用于创建一个新进程(子进程)及其主线程,其函数原型如下: BOOL CreateProcess( LPCWSTR lpApplica ...
- nodejs 图片添加水印(png, jpeg, jpg, gif)
同步发布:https://blog.jijian.link/2020-04-17/nodejs-watermark/ nodejs 作为一个脚本语言,图片处理这方面有点弱鸡,无法跟 php 这种本身集 ...
- Mac port 443: Connection refused
MAC 安装brew raw.githubusercontent.com port 443: Connection refused 本人亲自认证过,踩过多种方案,最终认证的解决方案 原因:由于某些你懂 ...
- 为什么不建议通过Executors构建线程池
Executors类看起来功能还是比较强大的,又用到了工厂模式.又有比较强的扩展性,重要的是用起来还比较方便,如: ExecutorService executor = Executors.newFi ...
- Let’s Encrypt & Certbot 浅谈
前言 当我们想给网站启用HTTPS, 通常需要从证书颁发机构购买证书, 并配置到现有的HTTP服务上来实现HTTPS. 这里暗藏的痛点是: 我们需要花钱(买证书) 证书颁发机构(质量参差不齐, 不一定 ...
- LinkedBlockingQueue的poll方法底层原理
一.LinkedBlockingQueue的poll方法底层原理 LinkedBlockingQueue 的 poll 方法用于从队列头部移除并返回元素.如果队列为空,poll 方法会立即返回 nul ...
- 康谋分享 | 在基于场景的AD/ADAS验证过程中,识别挑战性场景!
基于场景的验证是AD/ADAS(自动驾驶和高级驾驶辅助)系统开发过程中的重要步骤,它包括对自动化系统进行一系列预定义场景的测试.测试中包含的场景越多,尤其挑战性场景越多,人们对正在测试的AD/ADAS ...
- kettle介绍-Step之Script Values/Mod(JavaScript 代码) 一
Script Values/Mod JavaScript 代码介绍 JavaScript 代码步骤提供了一个用户界面,用户可以编写 JavaScript 代码到脚本区,脚本区域中的每一行代码都会执行一 ...
- 【完结】【一本通提高】2025dsfzB哈希和哈希表做题笔记
2025年dsfz - 上学期B层字符串哈希专题做题笔记 笔记部分请看我的字符串哈希学习笔记 题目编号 标题 估分 正确 提交 Y 2066 Problem A [一本通提高篇哈希和哈希表]乌力波( ...