TVM:TensorIR
TensorIR是一种用于深度学习的特定领域语言,主要有两个目的。
- 在各种硬件后端进行程序变换和优化的实现
- 用于自动张量化程序优化的抽象
import tvm
from tvm.script.parser import ir_module
from tvm.ir.module import IRModule
from tvm.script import tir as T
import numpy as np
IRModule
IRModule是TVM的中心数据结构,它包含深度学习程序。它是 IR 变换和模型构建的基本关注对象。
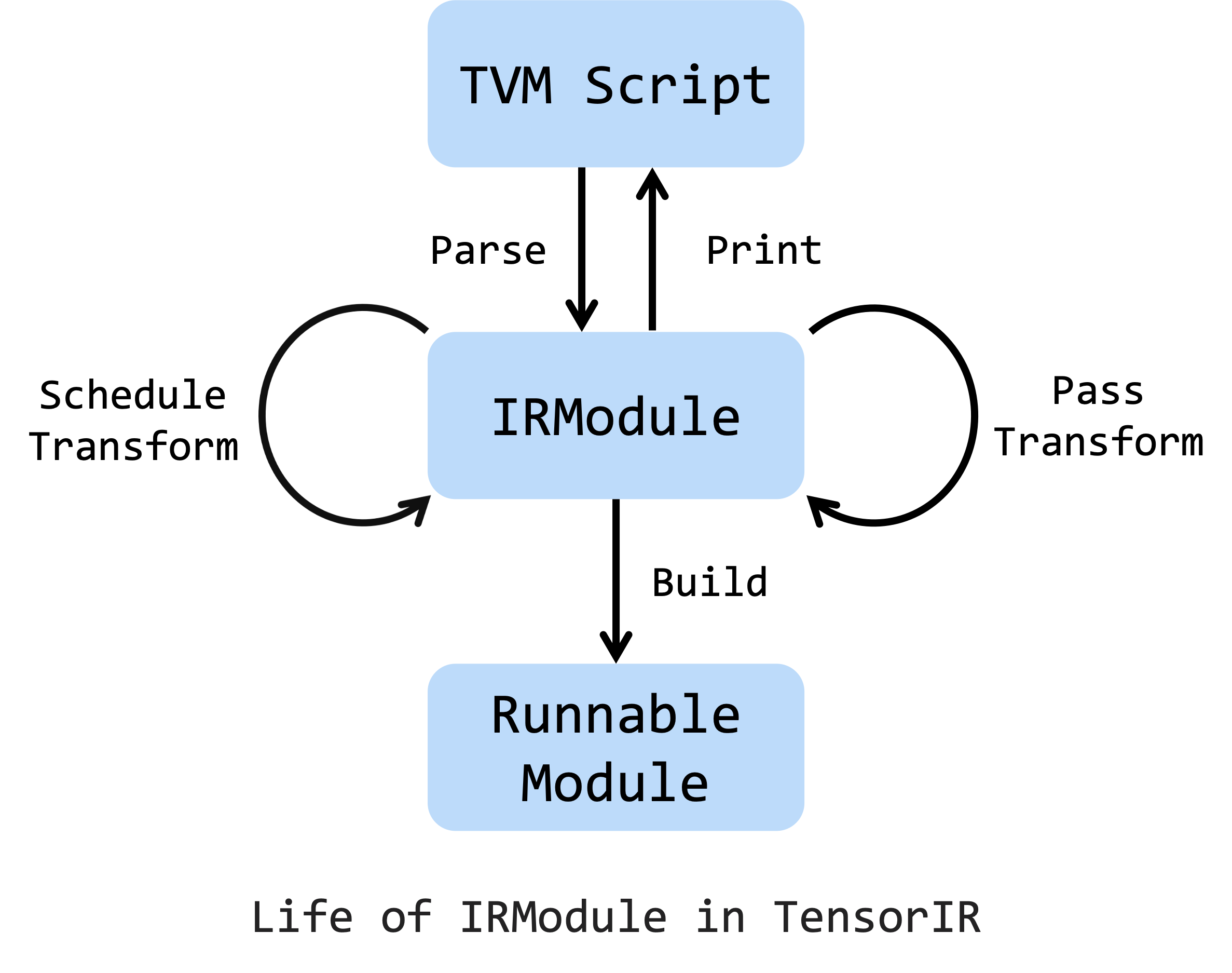
这是 IRModule 的生命周期(life cycle),它可以从 TVMScript 创建。TensorIR 调度原语(primitive)和传递(pass)是变换 IRModule 的两种主要方式。另外,对 IRModule 进行一系列的变换也是可以接受的。请注意,可以在 任何 阶段向 TVMScript 打印 IRModule。 在所有变换和优化完成后,可以将 IRModule 构建为可运行的模块,以部署在目标设备上。
基于 TensorIR 和 IRModule 的设计,能够创建新的编程方式:
1.用 TVMScript 写基于 Python-AST 语法的程序。
2. 用 python api 变换和优化程序。
3. 通过命令式的变换 API,交互式地检查和尝试性能。
Create an IRModule
IRModule 可以通过编写 TVMScript 来创建,TVMScript 是 TVM IR 的可圆润化(round-trippable)的语法。
与通过 张量表达式 创建计算表达式不同,TensorIR 允许用户通过 TVMScript(嵌入式 python AST 的语言)来编程。这种新方法使得编写复杂的程序并进一步调度和优化它成为可能。
@tvm.script.ir_module
class MyModule:
@T.prim_func
def main(a: T.handle, b: T.handle):
# We exchange data between function by handles, which are similar to pointer.
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# Create buffer from handles.
A = T.match_buffer(a, (8,), dtype="float32")
B = T.match_buffer(b, (8,), dtype="float32")
for i in range(8):
# A block is an abstraction for computation.
with T.block("B"):
# Define a spatial block iterator and bind it to value i.
vi = T.axis.spatial(8, i)
B[vi] = A[vi] + 1.0
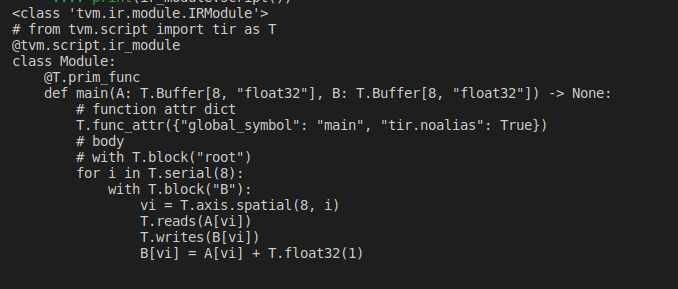
ir_module = MyModule
print(type(ir_module))
print(ir_module.script())
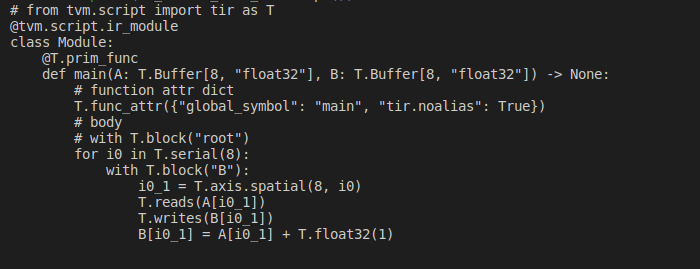
此外,还可以使用张量表达式 DSL 来编写简单的算子,并将其转换为 IRModule。
from tvm import te
A = te.placeholder((8,), dtype="float32", name="A")
B = te.compute((8,), lambda *i: A(*i) + 1.0, name="B")
func = te.create_prim_func([A, B])
ir_module_from_te = IRModule({"main": func})
print(ir_module_from_te.script())
Build and Run an IRModule
可以将 IRModule 构建为具有特定目标后端的可运行模块。
mod = tvm.build(ir_module, target="llvm") # The module for CPU backends.
print(type(mod))
输出结果:
<class 'tvm.driver.build_module.OperatorModule'>
准备好输入 array 和输出 array,然后运行该模块。
a = tvm.nd.array(np.arange(8).astype("float32"))
b = tvm.nd.array(np.zeros((8,)).astype("float32"))
mod(a, b)
print(a)
print(b)
输出结果:
[0. 1. 2. 3. 4. 5. 6. 7.]
[1. 2. 3. 4. 5. 6. 7. 8.]
Transform an IRModule
IRModule 是程序优化的中心数据结构,它可以通过 Schedule 进行转换。调度包含多个原语方法,以交互式地转换程序。每个原语都以某些方式改造程序,以带来额外的性能优化。
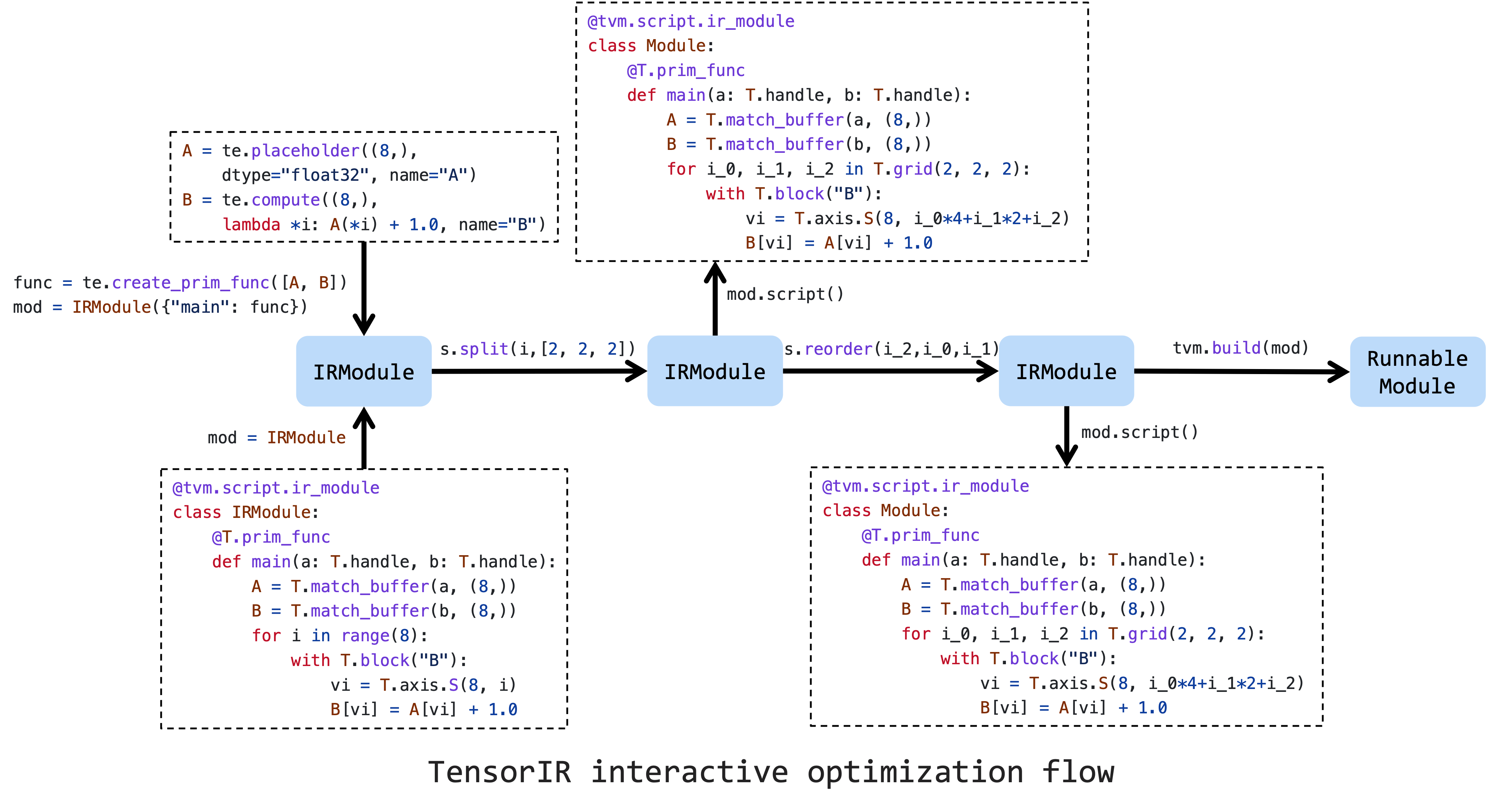
上面的图片是优化张量程序的典型工作流程。首先,需要在由 TVMScript 或 Tensor Expression 创建的初始 IRModule 上创建调度。然后,一连串的调度原语将有助于提高性能。最后,我们可以将其降低并构建为可运行的模块。
这里只演示了非常简单的变换。首先,在输入的 ir_module 上创建调度。
sch = tvm.tir.Schedule(ir_module)
print(type(sch))
输出结果:
<class 'tvm.tir.schedule.schedule.Schedule'>
将该循环分为 3 个循环,并打印结果。
# Get block by its name
block_b = sch.get_block("B")
# Get loops surrounding the block
(i,) = sch.get_loops(block_b)
# Tile the loop nesting.
i_0, i_1, i_2 = sch.split(i, factors=[2, 2, 2])
print(sch.mod.script())
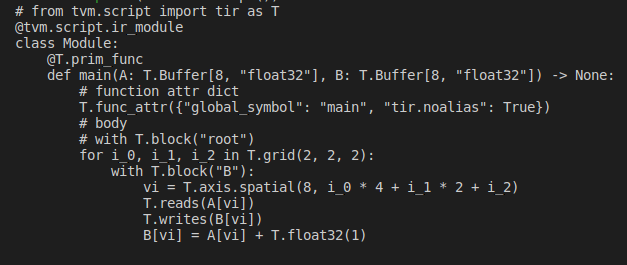
也可以重新调度循环的顺序。现在将循环 i_2 移到 i_1 的外面。
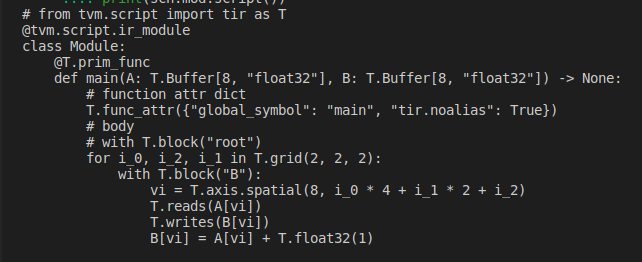
i_1)
print(sch.mod.script())
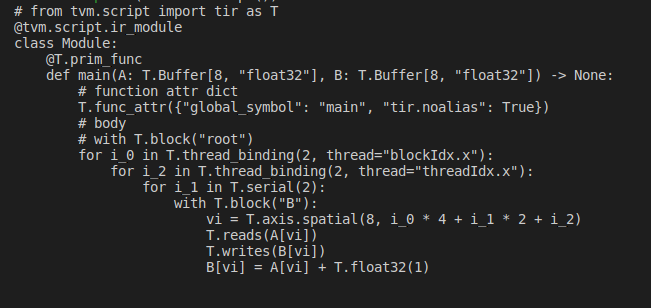
Transform to a GPU program
如果想在 GPU 上部署模型,线程绑定是必要的。幸运的是,也可以使用原语并做增量变换。
sch.bind(i_0, "blockIdx.x")
sch.bind(i_2, "threadIdx.x")
print(sch.mod.script())
# from tvm.script import tir as T
@tvm.script.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer[8, "float32"], B: T.Buffer[8, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i_0 in T.thread_binding(2, thread="blockIdx.x"):
for i_2 in T.thread_binding(2, thread="threadIdx.x"):
for i_1 in T.serial(2):
with T.block("B"):
vi = T.axis.spatial(8, i_0 * 4 + i_1 * 2 + i_2)
T.reads(A[vi])
T.writes(B[vi])
B[vi] = A[vi] + T.float32(1)
绑定线程后,现在用 cuda 后端构建 IRModule。
ctx = tvm.cuda(0)
cuda_mod = tvm.build(sch.mod, target="cuda")
cuda_a = tvm.nd.array(np.arange(8).astype("float32"), ctx)
cuda_b = tvm.nd.array(np.zeros((8,)).astype("float32"), ctx)
cuda_mod(cuda_a, cuda_b)
print(cuda_a)
print(cuda_b)
输出结果:
[0. 1. 2. 3. 4. 5. 6. 7.]
[1. 2. 3. 4. 5. 6. 7. 8.]
TVM:TensorIR的更多相关文章
- tvm install
一.系统需求:1.可以访问互联网2.关闭防火墙和selinux 二.安装步骤(进入软件包所在目录):1.rpm -ivh daemontools-0.76-1.el6.x86_64.rpm2.yum ...
- 关于 TVM
偶然间对 arm 中 mali 显示核心感兴趣,找到的 TVM.将了解到的信息做个备忘. TVM 是 Tensor Virtual Machine 的所写? 官网上,TVM 定义自己为一种 Inter ...
- TVM:
Hello TVM 发表于 2019-06-29 TVM 是什么?A compiler stack,graph level / operator level optimization,目的是(不同框 ...
- TVM图优化(以Op Fusion为例)
首先给出一个TVM 相关的介绍,这个是Tianqi Chen演讲在OSDI18上用的PPThttps://files.cnblogs.com/files/jourluohua/Tianqi-Chen- ...
- TVM设备添加以及代码生成
因为要添加的设备是一种类似于GPU的加速卡,TVM中提供了对GPU编译器的各种支持,有openCl,OpenGL和CUDA等,这里我们选取比较熟悉的CUDA进行模仿生成.从总体上来看,TVM是一个多层 ...
- TVM调试指南
1. TVM安装 这部分之前就写过,为了方便,这里再复制一遍. 首先下载代码 git clone --recursive https://github.com/dmlc/tvm 这个地方最好使用--r ...
- TVM安装
因为现在NNVM的代码都转移到了TVM中,NNVM代码也不再进行更新,因此选择安装的是TVM. git clone --recursive https://github.com/dmlc/tvm su ...
- TVM:一个端到端的用于开发深度学习负载以适应多种硬件平台的IR栈
TVM:一个端到端的用于开发深度学习负载以适应多种硬件平台的IR栈 本文对TVM的论文进行了翻译整理 深度学习如今无处不在且必不可少.这次创新部分得益于可扩展的深度学习系统,比如 TensorFlo ...
- TVM性能评估分析(七)
TVM性能评估分析(七) Figure 1. Performance Improvement Figure 2. Depthwise convolution Figure 3. Data Fus ...
- TVM性能评估分析(六)
TVM性能评估分析(六) Figure 1. The workflow of development PC, compile, deploy to the device, test, then mo ...
随机推荐
- SSM - 狂神的项目示例
出于对狂神的崇拜,总结SSM项目. 基本介绍 项目分层 基本介绍 项目名称:ssmbuild 介绍:通过书籍管理系统实现一个简单的SSM项目,可以作为其他Java Web项目的借鉴. 主要功能模块:查 ...
- 【渗透测试】Vulnhub Corrosion 1
渗透环境 攻击机: IP: 192.168.226.129(Kali) 靶机: IP:192.168.226.128 靶机下载地址:https://www.vulnhub.com/entr ...
- VMware虚拟机上安装CentOS8详细教程
1.准备工作 1.1.需要准备好已安装完成的VMware虚拟机,如果您的电脑未安装VMware虚拟机,请参考以下连接:https://www.cnblogs.com/x1234567890/p/148 ...
- 【论文随笔】推荐系统综述_推荐模型、推荐技术与应用领域(A Survey of Recommendation Systems_ Recommendation Models, Techniques, and Application Fields)
前言 今天读的论文为一篇于2022年1月3日发表的论文,这篇文章是关于推荐系统的综述,主要研究了推荐系统在不同服务领域的应用趋势,包括推荐模型.技术和应用领域.通过分析2010年至2021年间发表的顶 ...
- Trae AI 工具使用记录--0手写代码创建桌面代办事项软件
使用的AI工具是最近字节跳动出品的Trae工具. 第一步 下载IDE,Trae(官网链接 https://www.trae.ai) 安装完成后注册.登录,可以直接使用github账号.第一个坑就是目前 ...
- Elasticsearch搜索引擎学习笔记(三)
索引的一些操作 集群健康 GET /_cluster/health 创建索引 PUT /index_test { "settings": { "index": ...
- 自己写的第一个java项目!
项目名为"零钱通" 细节参考 [零基础 快速学Java]韩顺平 零基础30天学会Java 基本版: 1 package project; 2 3 import java.text. ...
- 云服务器下如何部署Flask项目详细操作步骤
参考网上各种方案,再结合之前学过的Django部署方案,最后确定Flask总体部署是基于:centos7+nginx+uwsgi+python3+Flask之上做的. 本地windows开发测试好了我 ...
- SpringBoot+微信支付-JSAPI{微信支付回调}
引入微信支付SDK Maven: com.github.wechatpay-apiv3:wechatpay-java-core:0.2.12 Maven: com.github.wechatpay-a ...
- 继承中成员变量和成员方法的访问特点-java se进阶篇 day01
1.继承中成员变量的访问特点 1.成员变量重名 如图 父类中有age变量,子类中也有age变量,这时打印age,出现的是10还是20呢? 答:根据就近原则,出现的是20 2.使用父类成员变量--sup ...