高效安全迁移:PG高可用集群实战方案深度解析
PostgreSQL是一个开源的数据库管理系统,相比于其他开源数据库系统,PostgreSQL有更加丰富的数据类型和可扩展性,并因此被广泛采用。在实际工作中,若企业业务需求变动,则有可能面临PG高可用集群迁移的情况。
云掣具备丰富的帮助企业迁移数据平台的实战经验,提供专业的数据库运维托管服务,本文旨在通过一次PG高可用集群环境迁移但IP不变的成功客户案例,结合云掣在多次客户数据迁移过程中总结出的宝贵经验,与大家分享两种安全稳定迁移PG高可用集群的方案,并将两种方案的优缺点进行了对比,便于大家根据自己的情况择优选择。
一、客户背景
某客户线下环境有2套PG高可用自建集群,由于之前使用的CentOS系统,官方已经不再维护了,所以需由当前的CentOS环境迁至新的RedHat环境。2套PG均是REPMGR高可用集群架构,迁移切换后,新环境需使用旧环境的IP地址。
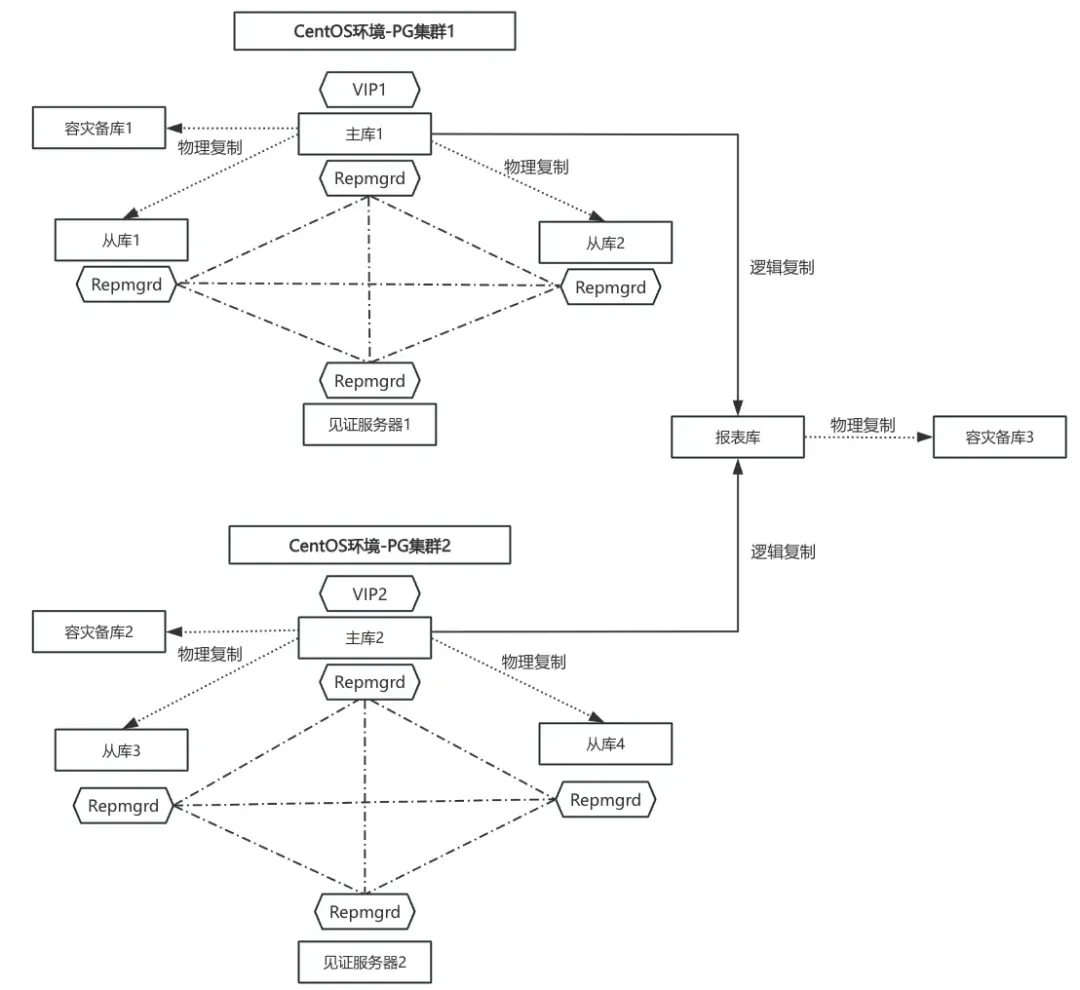
二、迁移方案
方案一
①在新的RedHat环境安装PG作为当前主库的从节点,通过REPMGR将当前主库数据克隆至RedHat环境的从节点。
②数据同步完成后安排时间先将CentOS环境的IP与RedHat环境的IP进行替换、然后将当前CentOS环境主节点切至RedHat环境的某个从节点。
③切换完成后,CentOS环境旧报表库的逻辑复制不再同步新数据,需在RedHat环境部署新报表库并重新创建新的逻辑复制将新主库数据同步至新报表库。
④RedHat环境新报表库数据同步完成后,重新部署新主库与新报表库的容灾备库。
⑤图例:
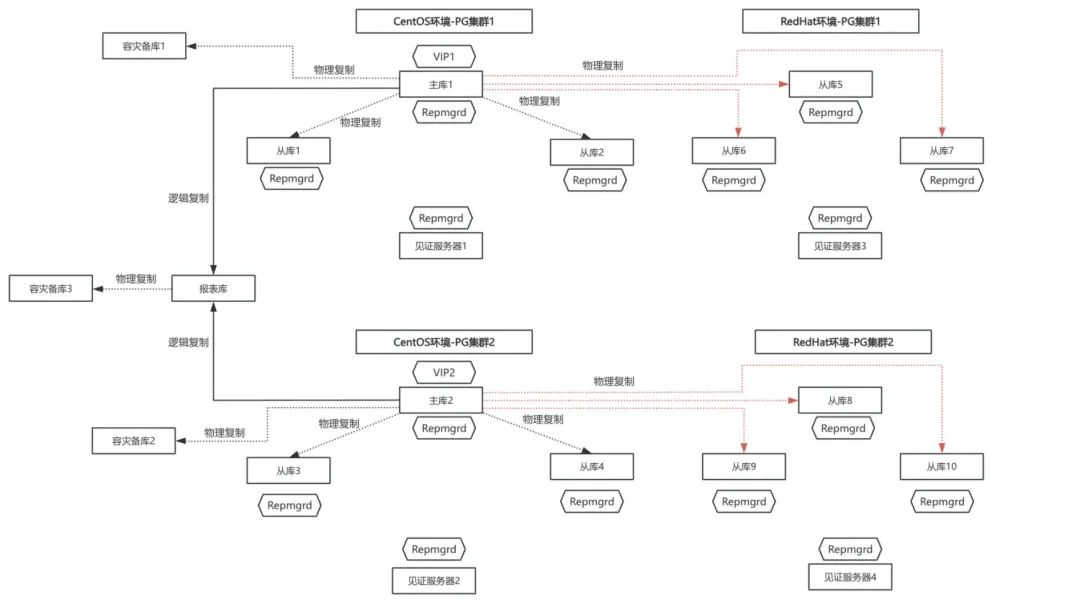
·新的RedHat环境搭建从库并克隆数据的架构图:
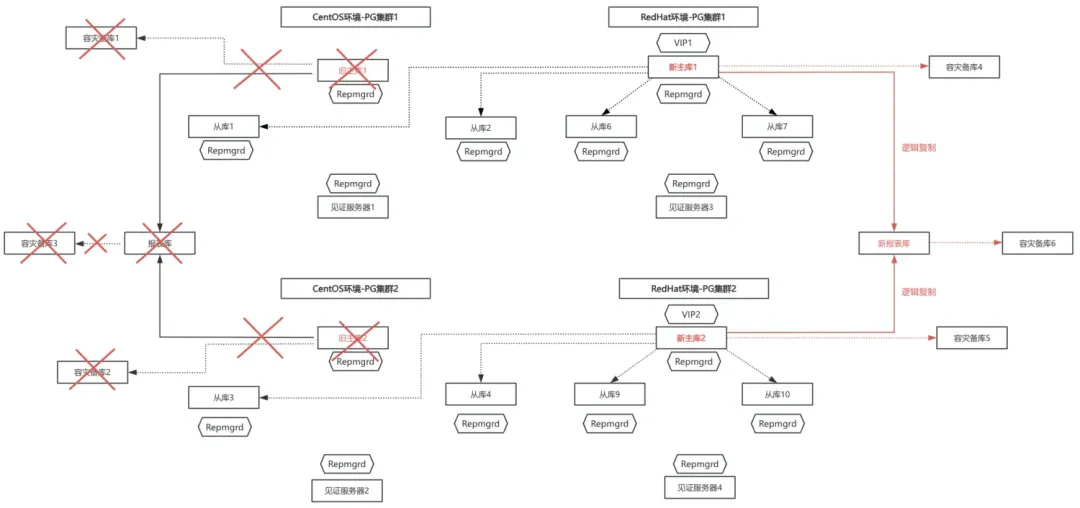
·切换RedHat环境的从库5、从库8为新主库,切换后通过逻辑复制同步新主库数据至新报表库的架构图:
方案二
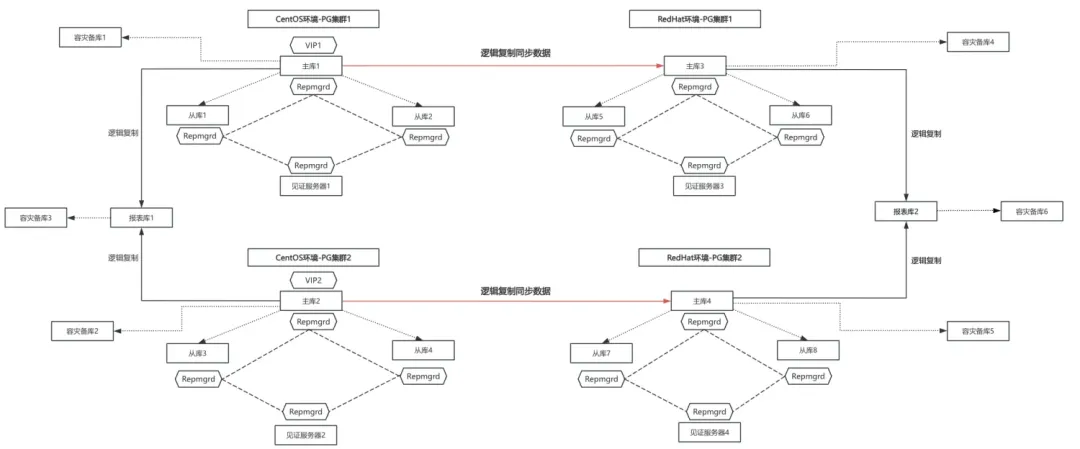
在新的RedHat环境搭建与当前CentOS环境完全相同的集群架构,通过逻辑复制将CentOS环境主库的数据同步至RedHat环境的主库,数据同步完成后安排时间暂停所有PG、将CentOS环境的IP与RedHat环境的IP进行替换、修改相关配置文件后重启PG。
两种方案优缺点对比
方案一CentOS环境与RedHat环境之间PG的数据同步通过物理流复制实现,该方法的优点是同步数据速度快、操作简单、同步对象齐全。缺点是RedHat环境的报表库需要等切主后才能开始数据同步,报表库不可用的时间比较长。
方案二CentOS环境与RedHat环境之间PG的数据同步通过逻辑复制实现,逻辑复制操作麻烦、有很多限制,比如表必须都有主键、每个库都需要创建一个逻辑复制同步通道,逻辑复制的同步能力和稳定性比较差,可能出现同步状态异常或出现较大延迟。另外逻辑复制只同步数据,需用插件同步DDL语句,还需通过备份将CentOS环境的账号权限、视图等对象定义恢复至RedHat环境。该方法的优点是RedHat环境报表库的数据一开始就可以同步,报表库不可用的时间很短。
三、方案实施
确定操作方案
经与业务方沟通确认,报表库不可用时间长的影响较低,决定采用方案一进行迁移。
具体操作步骤
RedHat环境准备工作
①RedHat环境搭建PG、REPMGR,其中见证节点初始化PG,从节点采用REPMGR进行数据克隆、物理复制同步,记录数据克隆耗时及对当前主库的性能消耗影响。
②将RedHat环境部署的从节点和见证节点的PG,加入至当前主库所在的REPMGR集群。
③RedHat环境安装pg_probackup,用于WAL日志归档及备份任务设置。
④RedHat环境新报表库初始化PG。
RedHat环境新报表库同步测试
①梳理报表库数据信息
CentOS环境,当前报表库的数据分为3部分,第1部分由PG集群1的主库逻辑复制同步而来,第2部分由PG集群2的主库逻辑复制同步而来,第3部分是业务自身在报表库新增的schema。
对于RedHat环境的新报表库,第1、2部分的数据需待主库切换后由新主通过逻辑复制同步至新报表库,第3部分需要通过pg_dump将相关schema数据备份恢复至新报表库。
②备份恢复测试
针对业务自身在报表库新增的schema,需通过pg_dump备份的方式将数据恢复至新报表库,测试该部分数据备份恢复的耗时情况及期间的性能消耗情况。
备份恢复的方式是先用pg_dumpall将当前报表库所有对象结构进行备份再用pg_dump对相关schema的数据进行备份,相关命令如下:
--备份所有对象结构
pg_dumpall -s -U{user_name} -p{port} -f "/xxx/all_object.sql"
--备份指定schema数据
pg_dump -Fd -v -a -U{user_name} -p{port} -d{db_name} -n{schema_name} -j2 -f "/xxx/{schema_name}.dump"
--恢复所有对象结构
psql -U{user_name} -p{port} -d{db_name} -f /xxx/all_object.sql >> /xxx/all_object.log 2>&1
--恢复指定schema数据
pg_restore -p{port} -d{db_name} -U{user_name} -j2 /xxx/schema_name.dump >> /xxx/{schema_name}.log 2>&1
③逻辑复制同步测试
针对由PG集群1、2的主库逻辑复制同步至报表库的数据,将RedHat环境从库5、从库8作为单独新主启动,测试新主逻辑同步至新报表库所需耗时及期间的性能消耗情况。
RedHat环境从库5、从库8数据同步完成后,单独作为新主启动,作为测试逻辑复制同步的源端:
--操作步骤如下
a.stop PG;
b.修改postgres.auto.conf,注释掉synchronous_standby_names、primary_conninfo、primary_slot_name;
c.删掉pg data目录下的standby.signal文件;
d.start PG
创建RedHat环境新主至新报表库的逻辑复制同步任务:
--新报表库部分命令如下
create subscription {sub_name} connection 'host={master_ip} port={port} dbname={db_name} user={user_name} password={password}' publication {pub_name};
alter subscription {sub_name} refresh publication ;
RedHat新主库与新报表库安装pgl_ddl_deploy插件:
--新主库部分命令如下
CREATE EXTENSION pgl_ddl_deploy;
INSERT INTO pgl_ddl_deploy.set_configs (set_name,include_schema_regex,driver) VALUES('{pub_name}','{schema_name}','native'::pgl_ddl_deploy.driver);
SELECT pgl_ddl_deploy.deploy('{pub_name}') from pgl_ddl_deploy.set_configs;
SELECT pgl_ddl_deploy.add_role(oid) from pg_roles where rolname='{user_name}';
select * from pgl_ddl_deploy.set_configs;
--新报表库部分命令如下
CREATE EXTENSION pgl_ddl_deploy;
SELECT pgl_ddl_deploy.add_role(oid) from pg_roles where rolname='{user_name}';
alter subscription {sub_name} refresh publication;
正式切换整体步骤
①准备好RedHat环境,清理新报表库测试时的相关环境,令其满足切换条件,包括RedHat环境PG与REPMGR搭建完成、从库数据同步完成、新报表库初始化完成。
②因后续RedHat环境与CentOS环境IP需互换,IP更换后PG在REPMGR集群中需重新注册,提前注销REPMGR集群中的从节点、见证节点。
③关闭业务。
④关闭PG及监控,先关主库,后关从节点、见证节点、报表库、容灾备库,最后停监控告警。
⑤整体替换IP,将CentOS环境与RedHat环境的IP进行替换。
⑥修改REPMGR与PG相关配置文件中与IP有关的相关内容。
⑦启动PG,先启主库,后启从节点、见证节点、报表库。
⑧将主节点、从节点、见证节点重新注册至REPMGR集群。
⑨切主,将主节点由CentOS环境的主库切至RedHat环境的其中一个从库,切换后VIP会绑定新主。
⑩将切换后的旧主作为新主的从节点,重新加入REPMGR集群。
⑪ 开启监控告警。
⑫处理RedHat环境新报表库,将CentOS环境报表库自身产生的数据通过备份恢复至RedHat环境新报表库,将需同步的数据由RedHat环境新主库逻辑复制同步至新报表库。
⑬WAL归档与备份任务,确认复制同步状态及延迟情况,核对同步对象数量、表数据量是否一致。
⑭ 业务,确认业务是否正常。
四、总结
通过两种不同的迁移方案,均可实现PG高可用集群的迁移切换,便于结合业务需求使用更为稳定的物理复制同步方案,使客户的PG集群整体平稳迁至新环境。
云掣专注于可观测运维,致力解决企业上云难、用云难、管云难三大问题。基于云数据库提供7*24小时保障服务,提供开发支持、数据库体系规范、持续优化、数据库架构支持,保障企业数据库高效稳定运行。全面提升企业的运维效率和稳定性,助力企业完成云时代的数字化转型,满足客户在数据库管理和云迁移方面的多样化需求!
想了解或咨询更多有关云掣产品、服务、客户案例的朋友,点击云掣进入官网。
《数据资产管理白皮书》下载地址:https://www.dtstack.com/resources/1073/?src=szsm
《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057/?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001/?src=szsm
《数栈V6.0产品白皮书》下载地址:https://www.dtstack.com/resources/1004/?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szsm
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术群」,交流最新开源技术信息,群号码:30537511,项目地址:https://github.com/DTStack
高效安全迁移:PG高可用集群实战方案深度解析的更多相关文章
- MySQL高可用集群MHA方案
MySQL高可用集群MHA方案 爱奇艺在用的数据库高可用方案 MHA 是目前比较成熟及流行的 MySQL 高可用解决方案,很多互联网公司正是直接使用或者基于 MHA 的架构进行改造实现 MySQL 的 ...
- HA 高可用集群概述及其原理解析
HA 高可用集群概述及其原理解析 1. 概述 1)所谓HA(High Available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件 ...
- Haproxy+keepalived高可用集群实战
1.1 Haproxy+keepalived高可用集群实战 随着互联网火热的发展,开源负载均衡器的大量的应用,企业主流软件负载均衡如LVS.Haproxy.Nginx等,各方面性能不亚于硬件负载均衡 ...
- MongoDB高可用集群配置方案
原文链接:https://www.jianshu.com/p/e7e70ca7c7e5 高可用性即HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非 ...
- MongoDB分片技术原理和高可用集群配置方案
一.Sharding分片技术 1.分片概述 当数据量比较大的时候,我们需要把数分片运行在不同的机器中,以降低CPU.内存和Io的压力,Sharding就是数据库分片技术. MongoDB分片技术类似M ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- Apache httpd和JBoss构建高可用集群环境
1. 前言 集群是指把不同的服务器集中在一起,组成一个服务器集合,这个集合给客户端提供一个虚拟的平台,使客户端在不知道服务器集合结构的情况下对这一服务器集合进行部署应用.获取服务等操作.集群是企业应用 ...
- Mysql 高可用集群PXC
PXC是percona公司的percona xtraDB cluster,简称PXC.它是基于Galera协议的高可用集群方案.可以实现多个节点间的数据同步复制以及读写,并且可保障数据库的服务高可 ...
- Redis Cluster高可用集群在线迁移操作记录【转】
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
- Redis Cluster 4.0高可用集群安装、在线迁移操作记录
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
随机推荐
- Redis 集群实现分布式缓存的示例操作流程【Redis 系列之五】
〇.前言 Redis 集群的核心优势在于高可用性.可扩展性和高性能,特别适合需要处理大规模数据和高并发请求的应用场景. 本文先介绍了什么是 Redis 集群,然后通过示例,以手动和自动两种方式搭建集群 ...
- MaxKB web 站点知识库选择器的花样玩法
背景:MaxKB 创建知识库支持"web 站点"的这种形式,但是很多同学不知道怎么录入选择器来针对性的获取某一部分内容. 1. 选择器作用 选择器用于定位网页中特定的元素,以便获取 ...
- windows10 激活教程
1.环境 适用对象:VL版本的windows OEM版本请使用文末工具激活 1.1查询自己电脑版本 [win+R]->输入[slmgr /dlv]->查看[产品密钥通道] slmgr /d ...
- python同时给多个邮箱地址发送邮件
这个帖子内讲了怎么发邮件:https://www.cnblogs.com/becks/p/14589314.html 下图红框内于发送目标邮件地址有关 讲红框内信息修改为下方代码,即可实现向多人发送邮 ...
- Fiddler的安装和使用教程(详细)
一.安装 1.fiddler工具下载网址:http://www.telerik.com/download/fiddler. 2.运行 FiddlerSetup.exe一键完成安装. 3.安装成功后点击 ...
- 鸿蒙动画与交互设计:ArkUI 3D变换与手势事件详解
大家好,我是 V 哥. 在鸿蒙 NEXT 开发中,ArkUI 提供了丰富的 3D 变换和手势事件功能,可用于创建生动且交互性强的用户界面.下面详细介绍 ArkUI 的 3D 变换和手势事件,并给出相应 ...
- 俩天完美复刻DeepWiki,并且免费开源!
俩天完美复刻DeepWiki,并且免费开源! 大家好!今天非常高兴为大家介绍KoalaWiki项目 - 这是我们团队花费两天时间完美复刻一个免费开源的AI驱动代码知识库系统,可以说是DeepWiki的 ...
- Java--事务,操作数据库,实现转账
更新:2019/3/29 目录 简介 事务的四个特性 一个小Demo 目录结构 jdbc.properties JDBCUtil.java TestTransaction.java[核心代码] 数据库 ...
- ServletContext相关
简介 如何得到对象 有什么作用 1.获取全局配置参数 2.获取web工程中的资源 3.存取数据,servlet间共享数据 域对象 ServlerContext的生命周期 ServletContext ...
- 【记录】PDF|中英文PDF扫描版目录提取(一、QQ+GPT)
需求: 1)从PDF里快速提取目录: 2)不想下载任何软件. 文章目录 一.用现有常用软件直接导出目录 1 (推荐指数☆)QQ OCR文字识别 2 (推荐指数0星)GPT4 图像识别 3 (推荐指数0 ...