Doris数据库使用
PROPERTIES (
"replication_num" = "1", //副本数
"colocate_with" = "group1",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
【6】Olap表
ENGINE=OLAP
明细模型
CREATE TABLE site_access_duplicate
(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0'
)
DUPLICATE KEY(site_id, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
聚合模型
CREATE TABLE site_access_aggregate
(
site_id INT DEFAULT '10',
city_code SMALLINT,
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(site_id, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
更新模型
CREATE TABLE site_access_unique
(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0'
)
UNIQUE KEY(site_id, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
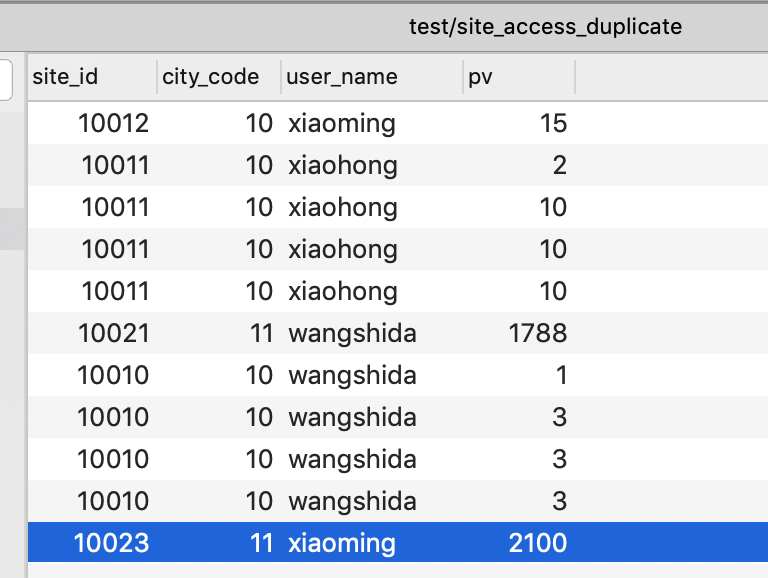
INSERT INTO site_access_duplicate
VALUES(10010,10,"wangshida",1),
(10011,10,"xiaohong",2),
(10012,10,"xiaoming",15)
delete from site_access_duplicate where site_id=10022
基础表
CREATE TABLE site_access_duplicate
(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0'
)
DUPLICATE KEY(site_id, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
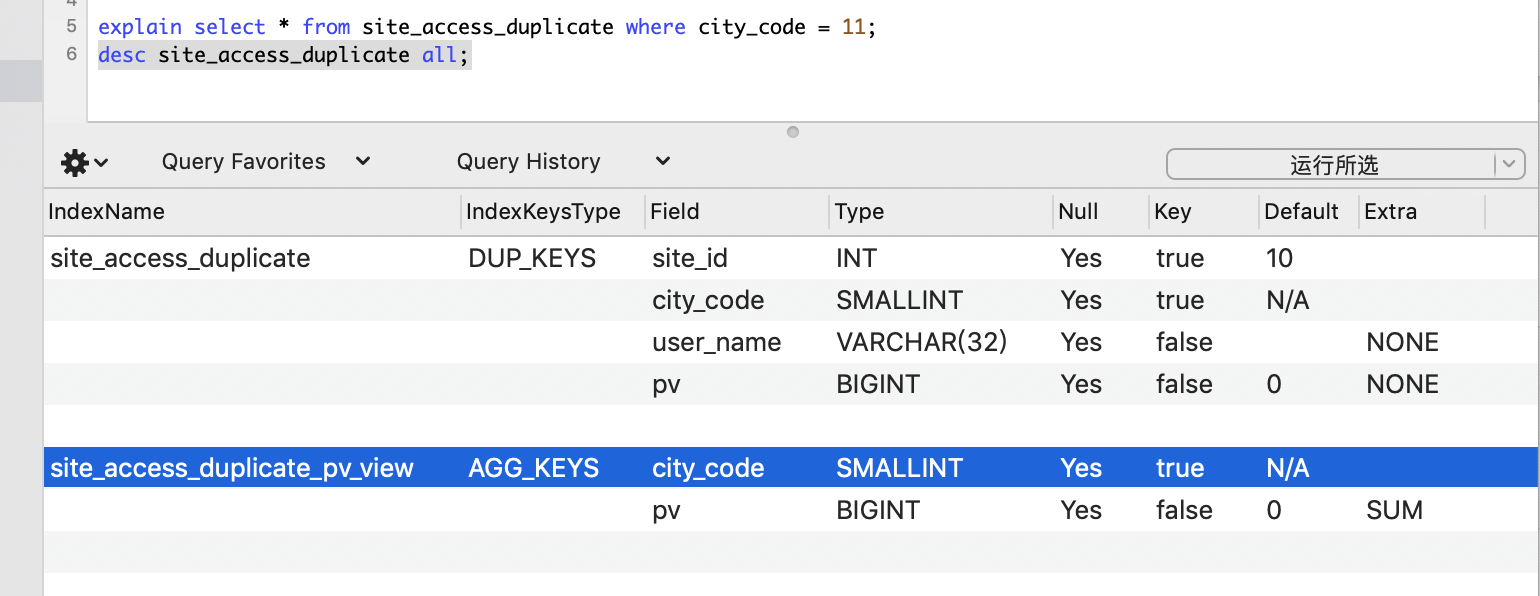
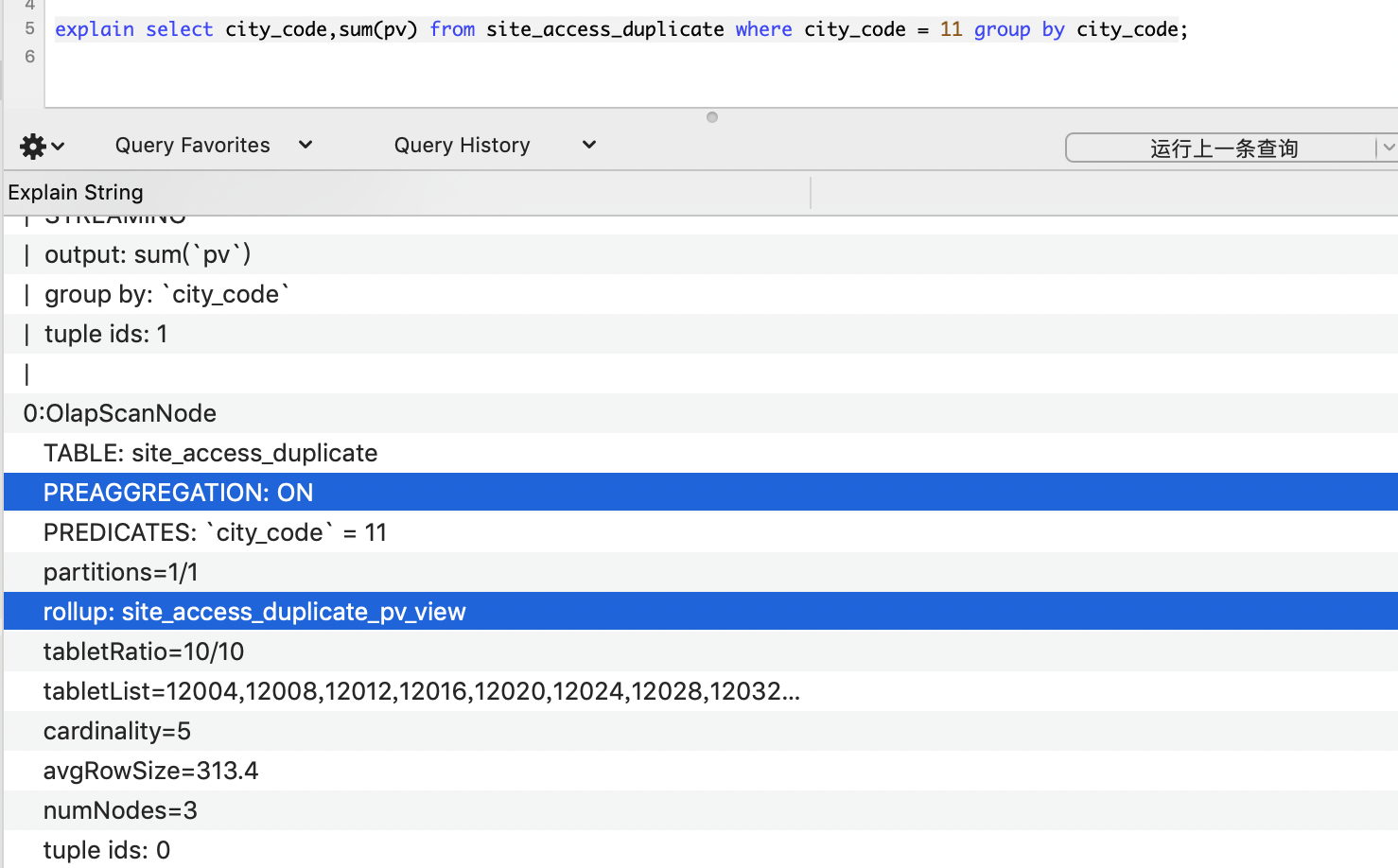
CREATE MATERIALIZED VIEW `site_access_duplicate_pv_view` AS
SELECT city_code, SUM(pv) AS sum_pv
FROM site_access_duplicate
GROUP BY city_code ORDER BY city_code
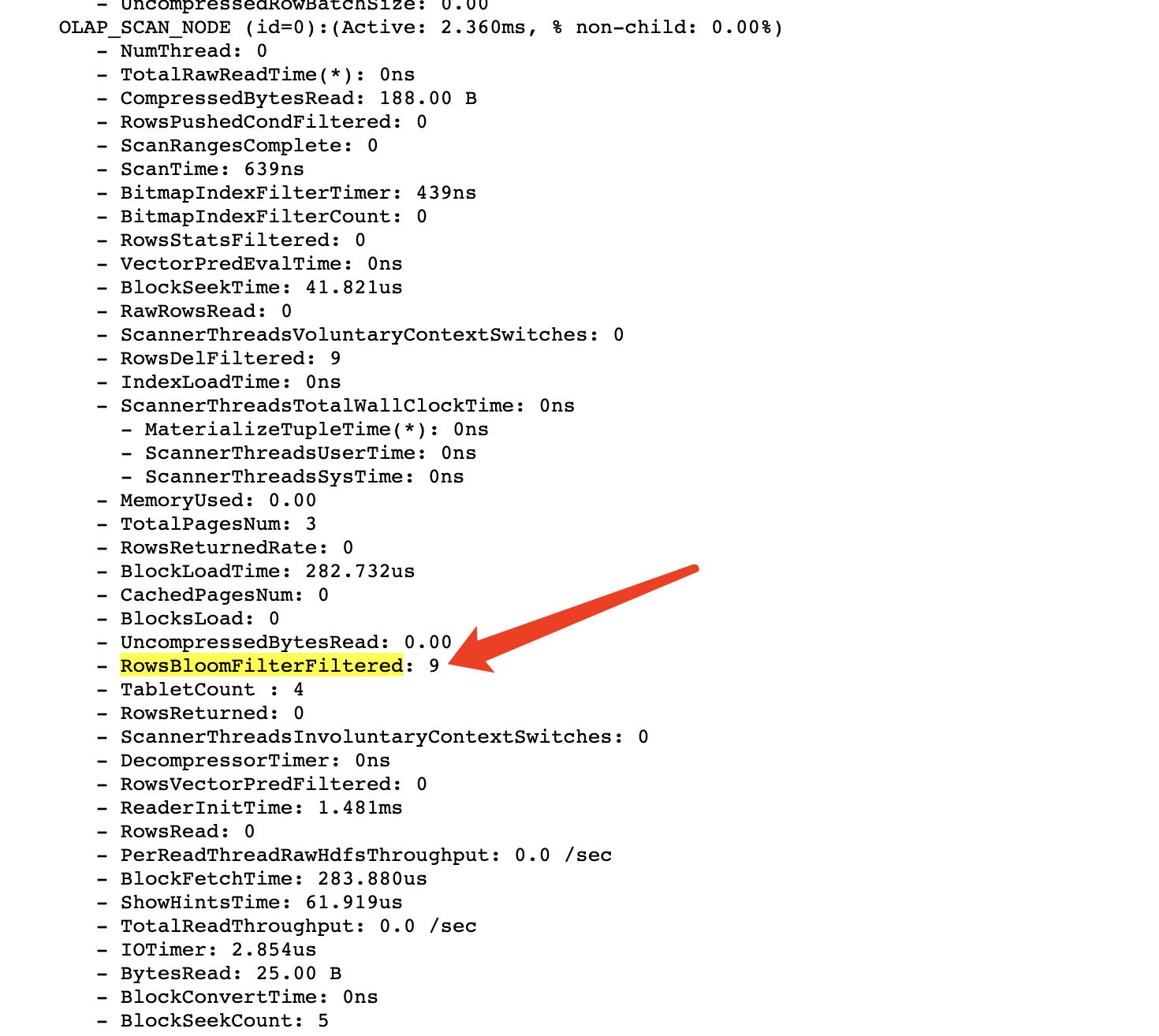
ALTER TABLE site_access_duplicate SET ("bloom_filter_columns" = "user_name");
select * from site_access_duplicate where user_name = 'xiaoming';
7、集群管理
查看Fe集群状态 show frontends \G
查看Be集群状态 show backends \G
Doris数据库使用的更多相关文章
- 新型MPP的Doris数据库:数据模型和数据分区使用详解
Apache Doris是一个现代化的MPP分析性数据库产品.是一个由百度开源,在2018年贡献给Apache基金会,成为有顶级开源项目.仅需要亚秒级响应时间即可获得查询结果,可以有效地支持实时数据分 ...
- 通过Nginx TCP反向代理实现Apache Doris负载均衡
概述 Nginx能够实现HTTP.HTTPS协议的负载均衡,也能够实现TCP协议的负载均衡.那么,问题来了,可不可以通过Nginx实现Apache Doris数据库的负载均衡呢?答案是:可以.接下来, ...
- Apache Doris 单节点(可多节点)Docker集群制作教程
集群制作Author:苏奕嘉脚本研发Author:种益调研测试Author:杨春东 前言 Apache Doris是当下非常火热和流行的MPP架构OLAP数据库,很多同学想自学/测试Doris的使用和 ...
- SQL 错误 [1105] [HY000]: errCode = 2, detailMessage = select list expression not produced by aggregation output (missing from GROUP BY clause?): ......
SQL 错误 [1105] [HY000]: errCode = 2, detailMessage = select list expression not produced by aggregati ...
- JSP应用开发 -------- 电纸书(未完待续)
http://www.educity.cn/jiaocheng/j9415.html JSP程序员常用的技术 第1章 JSP及其相关技术导航 [本章专家知识导学] JSP是一种编程语言,也是一种动 ...
- Apache Doris ODBC外表数据库主流版本及其ODBC版本对应关系
本文是在CentOS 7.9下测试通过 使用的Doris是:0.15.0 unixODBC版本是:2.3.1 1.PostgreSQL 以下是PostgreSQL数据库版本和PostgreSQL OD ...
- 本周六 Apache DolphinScheduler & Doris 将联合线上 Meetup
活动背景 2020年,大数据成为国家基建的一个重要组成,大数据在越来越多的领域展现威力.随着大数据的应用场景越来越多,大家对数据的响应速度和数据加工工作流的方便程度也提出了更高的要求.在这种背景下,相 ...
- Doris开发手记1:解决蛋疼的MySQL 8.0连接问题
笔者作为Apache Doris的开发者,平时感觉相关Doris的文章写的很少.主要是很多时候不知道应该去记录一些怎么样的问题,感觉写的不好就会很慌张.新的一年,希望记录自己在Doris开发过程之中所 ...
- [Apache Doris] Apache Doris 元数据设计及DDL操作源码阅读
元数据设计 如上图,Doris 的元数据主要存储4类数据: 用户数据信息.包括数据库.表的 Schema.分片信息等. 各类作业信息.如导入作业,Clone 作业.SchemaChange 作业等. ...
- 基于Ansible实现Apache Doris快速部署运维指南
Doris Ansible 使用指南 Apache Doris 介绍 Apache Doris是一个现代化的MPP分析型数据库产品.仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析.Apac ...
随机推荐
- python之在线书籍
人生苦短,我用python, 这里罗列一些可以查看python电子书的相关链接,平时没事多看看,一定会大有裨益!!! python3-cookbook[https://python3-cookbook ...
- golang之常用命令
golang常用操作与命令 1.执行golang文件 go run hello_world.go 2.编译成可执行文件(交叉编译) go build hello_world 则会生成hello_wor ...
- Redis中常见的延迟问题
使用复杂度高的命令 Redis提供了慢日志命令的统计功能 首先设置Redis的慢日志阈值,只有超过阈值的命令才会被记录,这里的单位是微妙,例如设置慢日志的阈值为5毫秒,同时设置只保留最近1000条慢日 ...
- Numpy本征值求解
技术背景 Numpy是一个Python库中最经常被用于执行计算任务的一个包,得益于其相比默认列表的高性能表现,以及易用性和可靠性,深受广大Python开发者的喜爱.这里介绍的是使用Numpy计算矩阵本 ...
- uniapp 消息推送
1.前言 作为一个非原生App的开发者,对于手机系统的推送机制了解是是非有限的,只有了解清楚这些机制,后期的开发才会少踩很多坑,本文将对推送机制逻辑进行一个简单的梳理与记录 2.推送流程 推送流程1. ...
- MySQL中INSERT INTO ... ON DUPLICATE KEY UPDATE浅析
最近在做一个阅读次数的需求的时候,有这样一个场景,如果数据库中没有数据,就进行INSERT操作,有数据的话,阅读次数就+1.此处有两种实现方式,一种是想将数据查出来,在Java中进行处理,没有就INS ...
- PM-企业数字化转型,数字化建设的重点
在数字化转型深入推进的大背景下,加强数据管理,释放数据要素价值,实现企业数据价值的内部循环,形成企业数据资产,是各个企业顺应时代发展趋势,积极探索业绩新亮点的必由之路. 数字化转型四个阶段: 一. 业 ...
- openEuler欧拉配置Nacos集群
一.安装Nacos systemctl stop firewalld systemctl disable firewalld mkdir -p /home/nacos tar xvf nacos- ...
- gdb 初次运行卡住 Starting program: [New Thread 0x1103 of process 843]
安装完后gdb一般会有提示: ==> gdbgdb requires special privileges to access Mach ports.You will need to codes ...
- JSchException: Algorithm negotiation fail问题解决之路
最近一个需求用到了SFTP上传功能,同事之前已经封装好了SFTP工具类,用的是JSch,本着不要重复造轮子的想法,就直接拿来用了.交代下环境,JDK为1.7,JSch版本为0.1.51.自测通过.测试 ...