我做了个开源数据应用平台 Lumina:数据人的快乐,终于轮到我了(内含在线 Demo)
我做了个开源数据应用平台 Lumina:数据人的快乐,终于轮到我了(内含在线 Demo)
先上干货:在线 Demo 与账号
- GitHub:https://github.com/TNT-Likely/Lumina
- 网址:https://lumina.zeabur.app/
- 测试账号:
testlumina- 密码:
123456- 友情提示:演示环境是只读,创建/更新/删除可能被拦截(但你依然可以体验大部分流程)。
大家好,我是一个“不想复制 CSV 去做 KPI 报表”的数据人。某天我意识到,摸鱼不如摸框架,于是撸了个开源数据产品平台——Lumina。
一句话版本:
- 连接数据库 → 配数据集(SQL/表)→ 配视图(图表)→ 拼仪表盘 → 订阅推送
- 支持组织/角色权限、公共/签名分享、计划任务与通知通道
- 前后端 TypeScript 单仓,工程化走起(日志、健康检查、只读演示环境……)
为什么做 Lumina?
- 给业务看:别总让我发截图了,点开就能看,手机也能看,最好还能订阅到邮箱/群里。
- 给数据看:一套数据集,多个视图复用。今天柱状图,明天折线图,后天 KPI 卡——别再写三遍 SQL。
- 给工程看:别担心,日志、鉴权、限流、健康检查都安排了;二次开发也不痛(TypeScript 全栈)。
Lumina 能干啥?(一分钟懂)
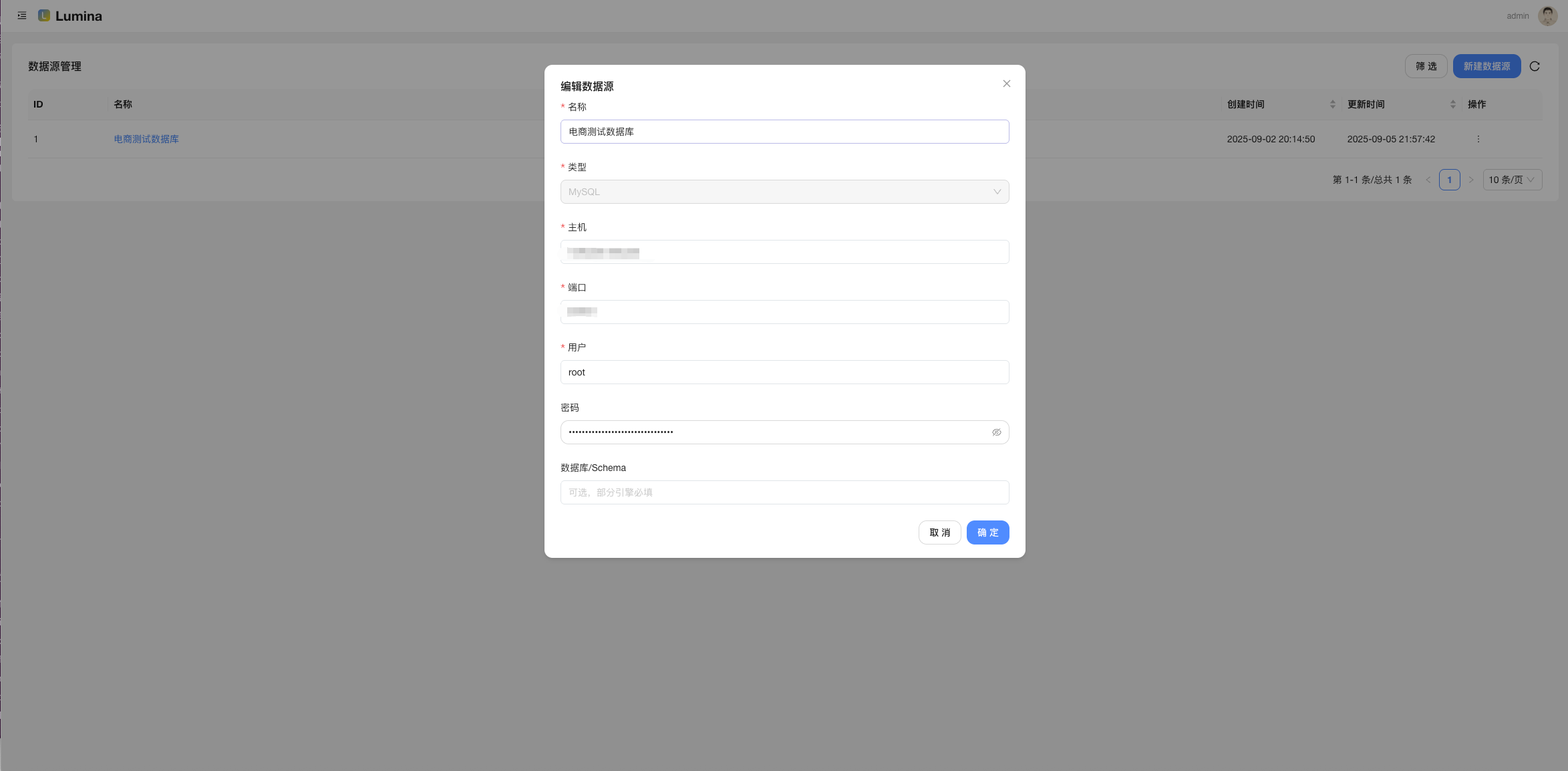
- 数据源(Datasource):连 MySQL(更多在路上),一键枚举库/表/字段,连接测试要有。
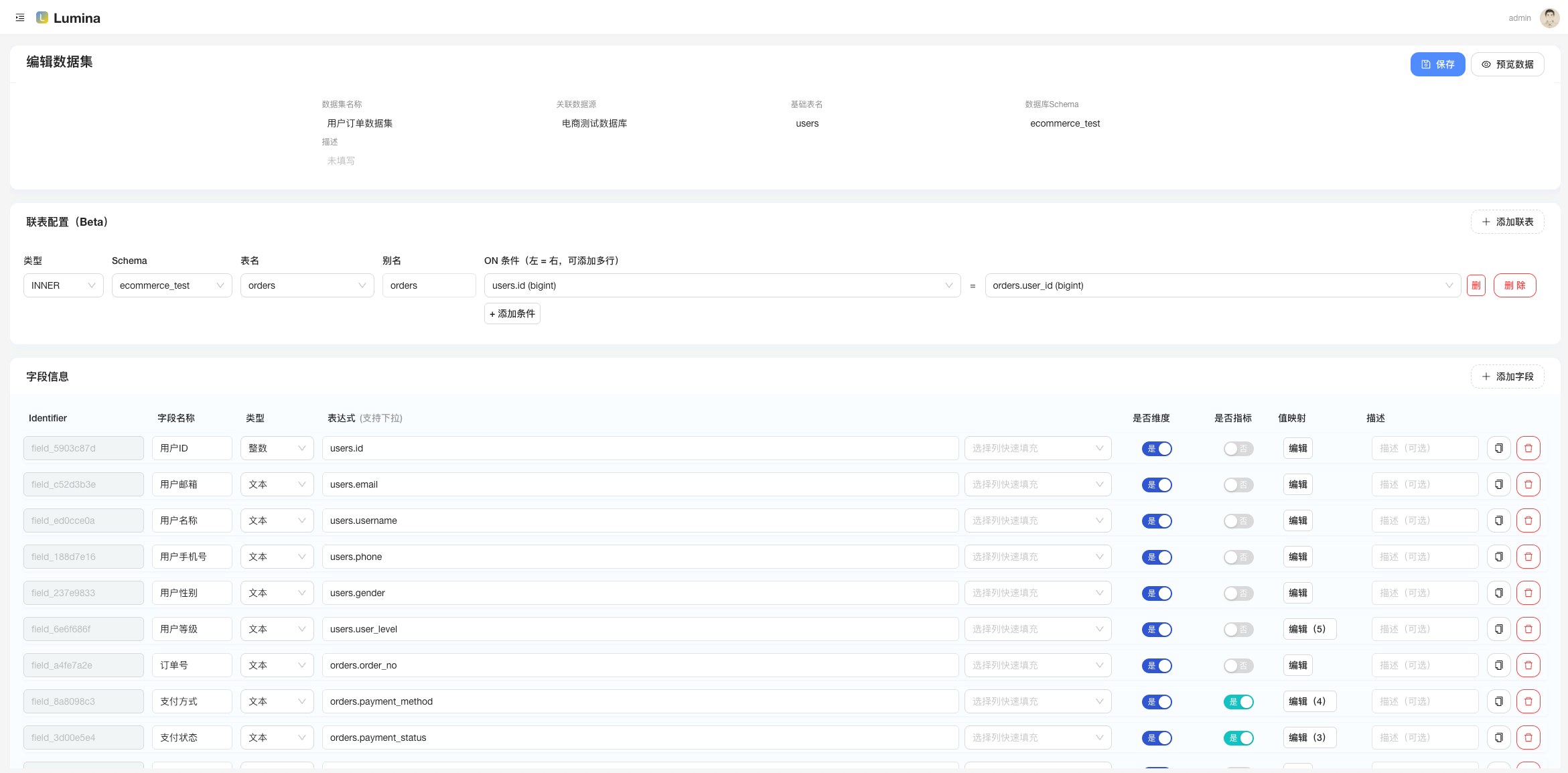
- 数据集(Dataset):基于表或 SQL 建模,字段命名/别名/筛选项统一个口径。
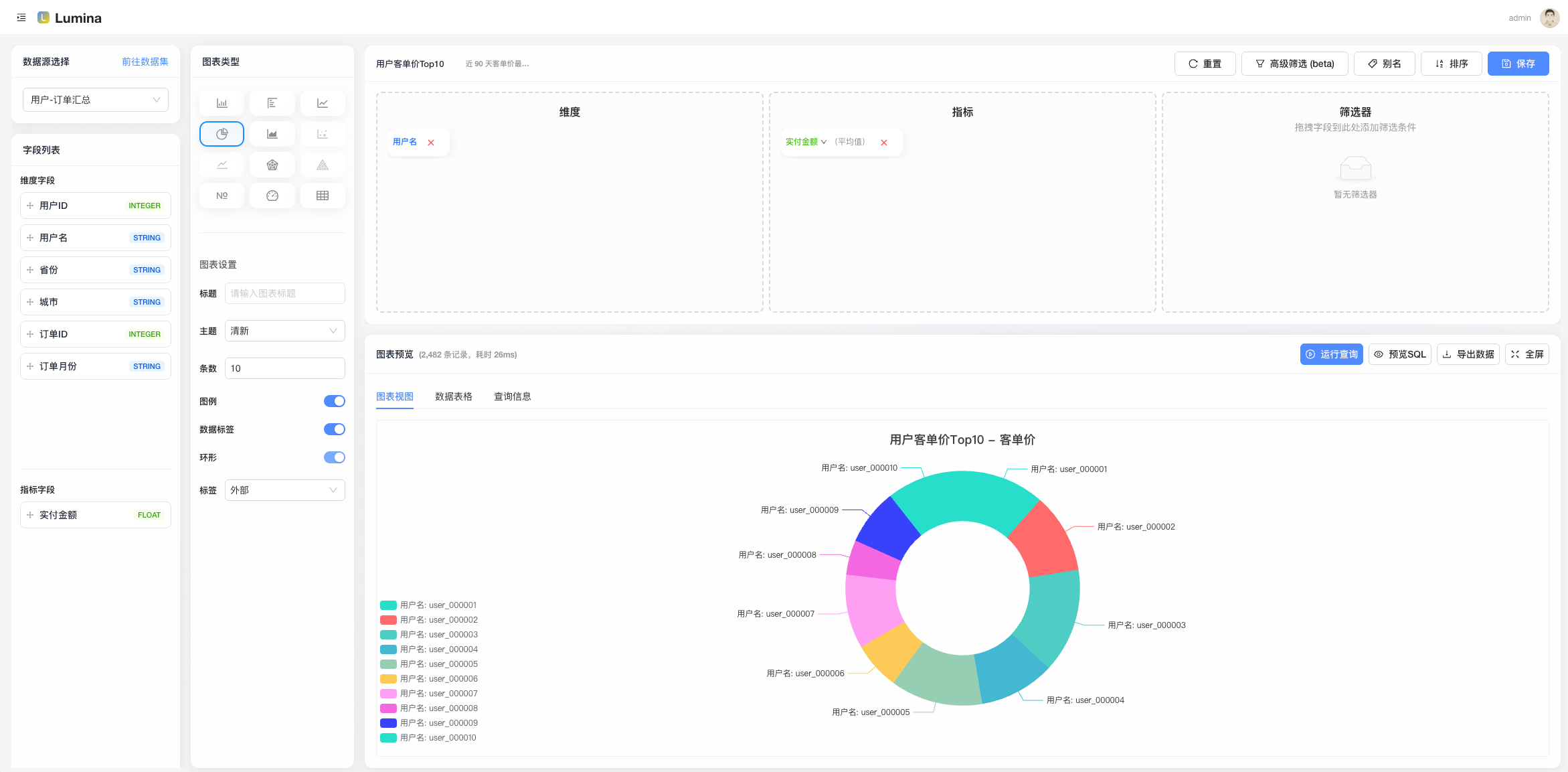
- 视图(View):拖拉拽绑定数据集,调一调维度/度量,预览看看效果,再发布。
- 仪表盘(Dashboard):把多个视图拼在一起,布局一摆,领导 KPI 就上线了。
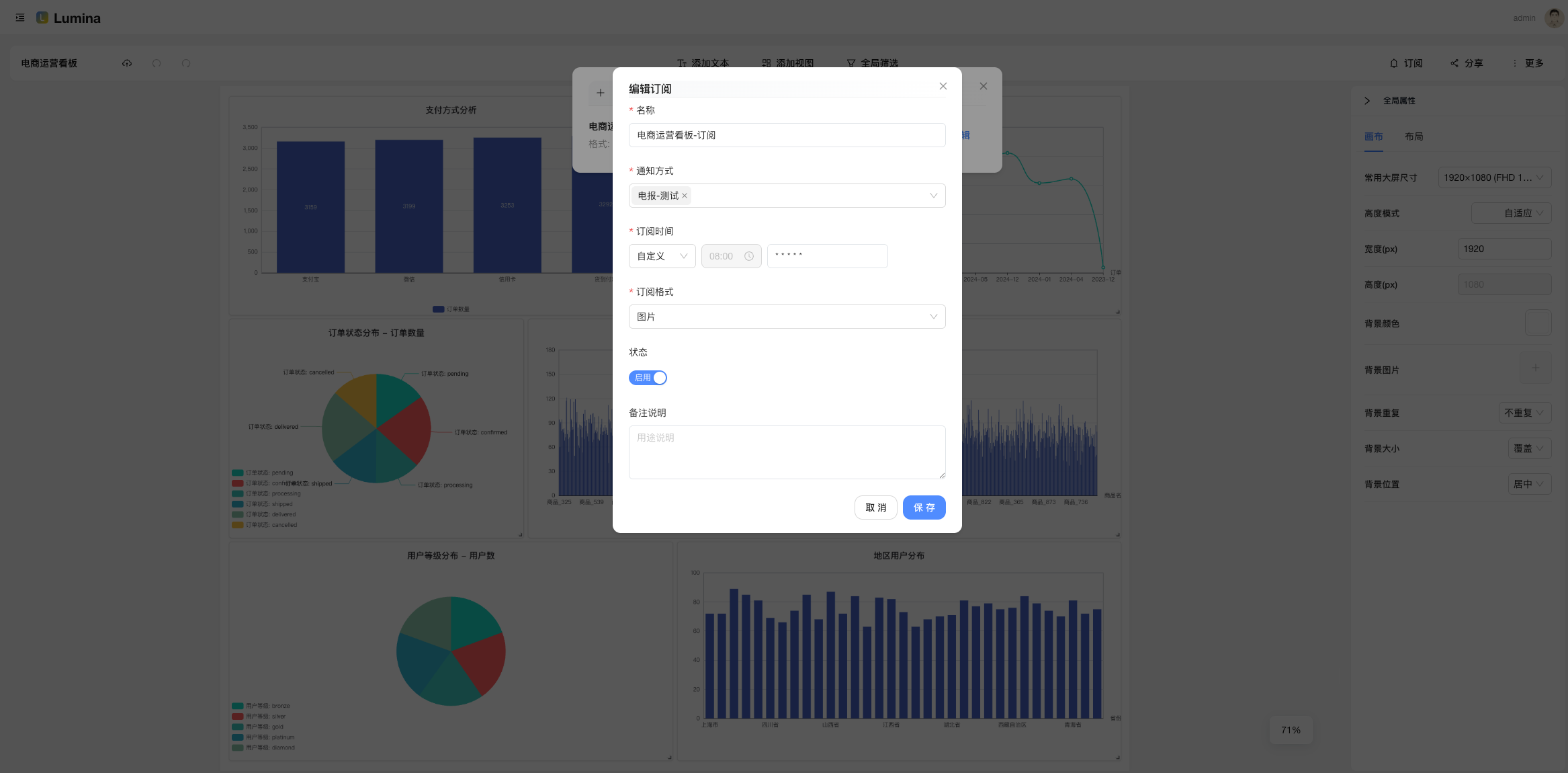
- 通知(Notification)+ 订阅(Subscription):定时任务按 Cron 来,结果推送到邮箱/Webhook。
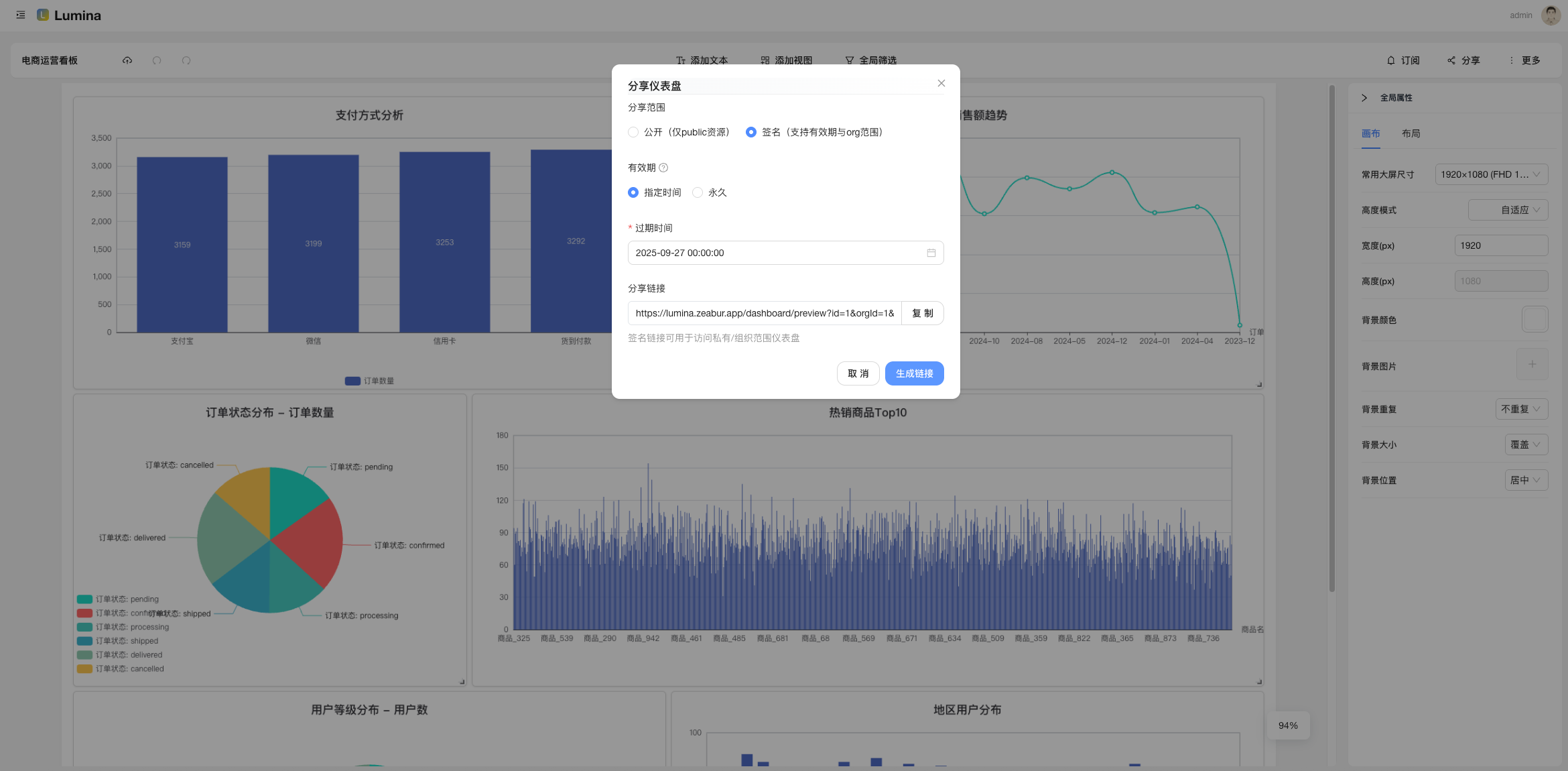
- 分享(Public/Sign):公开链接或者签名访问,外部同学也能看(可精细控制)。
- 权限与组织:多组织/多角色(Admin/Editor/Viewer),不给点权限,谁都动不了。
五分钟上手(不画饼,给路径)
打开 Demo 并登录(见文首),挑个「数据源」连上;
![]()
新建「数据集」:选表或写 SQL,预览字段,保存;
![]()
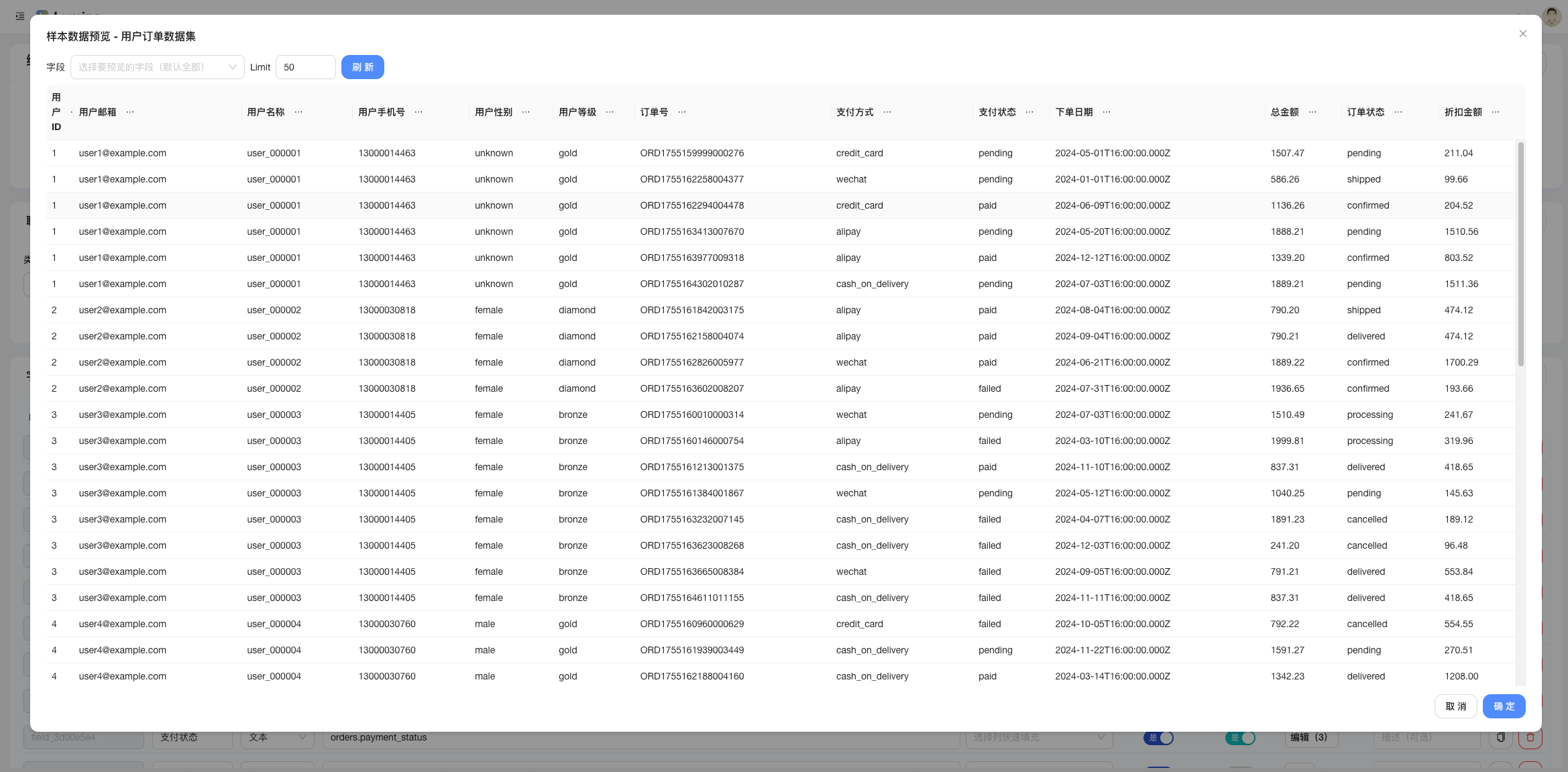
- 新建「视图」:选数据集,配置维度/度量(柱状、折线等),预览 OK;
- 新建「仪表盘」:把视图加进去,摆个舒服的布局;
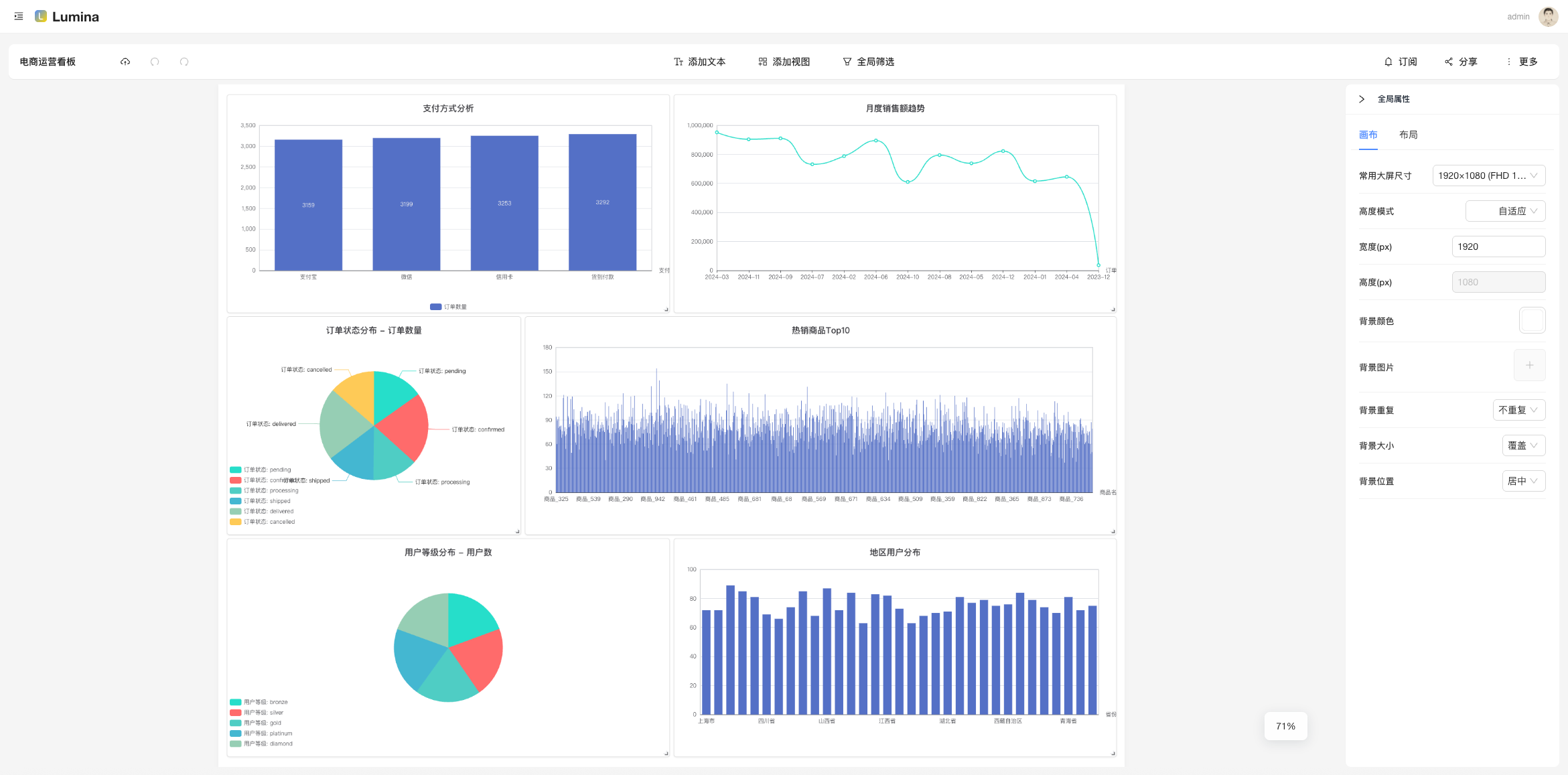
- 设置「订阅」:挑个仪表盘/视图,配置 Cron,选通知通道,跑一下测试;
- 分享给同事:公共链接 or 签名分享,权限拿捏好。
打不开脑洞?随便上一个产品留存/活跃/销售趋势,就能跑起来。
- 真·数据复用:Dataset 一处改名/校验,所有 View 自动受益,治理最省心。
- 订阅有测试:推送前先“试一下”,失败别等凌晨两点才知道。
- 演示环境只读:线上 Demo 安全放心玩,真正的写操作我们局部中间件精准拦截。
- 工程化:
- 结构化日志(AsyncLocalStorage 贯穿请求链路)
- 启动自检:MySQL / Redis / RabbitMQ 状态一网打尽
- 全局鉴权 + 局部只读中间件(精确到 create/update/delete 路由)
- 公共预览与签名分享,不登陆也能看(受控)
- 二次开发友好:Monorepo + TypeScript,全仓一致的工程体验。
图表类型(你想要的“花里胡哨”)
- 已支持:柱状图、折线图、饼图、面积图、KPI 卡、表格、百分比图、雷达图、散点图等
- 规划中:地图、漏斗、仪表盘、热力图、更多自定义组件
- 说明:每种图表都支持基础配置与数据绑定,后续可扩展更多类型。
数据源支持 & 订阅渠道(你关心的“入”和“出”)
数据源(当前已支持,见 packages/query-engine):
- MySQL、PostgreSQL、ClickHouse、Oracle、SQL Server(MSSQL)、MongoDB、Elasticsearch(ES Search)
- 说明:统一入口 QueryEngine(type, config),底层连接器可按需扩展(适配器模式)。
订阅渠道(当前已支持,见 packages/notify):
- 邮件(SMTP)、钉钉机器人、飞书(Lark)、Slack、Telegram、Discord
- 规划中:企业微信、通用 Webhook、Server酱、Bark、短信、语音电话
- 彩蛋:提供“连通性测试”,尽量把失败拦在上线之前。
技术栈(简洁但不简单)
- Monorepo:pnpm + turbo
- 后端:Egg.js、Sequelize、ioredis、amqplib、JWT
- 前端:React + antd + Vite
- 其他:ESLint、统一 TS 类型、结构化日志、健康检查、限流
谁适合用?
- 中小团队的内部 BI 诉求:做 KPI 看板、日报订阅、运营复盘。
- 想要可二开、能长出来的开源基座:你可以把它当“开源低代码 BI 内核”。
- 想给客户/外部伙伴只读查看的场景:公共/签名分享就绪。
Roadmap(部分)
- 数据源更多友军:……(欢迎 PR)
- 视图联动与更丰富的图形库
- 更细粒度的权限模型与审计
本地体验(可选)
想自己跑一遍?下面是极简流程,详细请看仓库 README。
# 环境:Node 20+、pnpm 9+,准备 MySQL/Redis/RabbitMQ
pnpm install
pnpm -C apps/server dev
pnpm -C apps/web dev
开源与参与
- https://github.com/TNT-Likely/Lumina
- Star & Issue 都是对作者续命的“电池”
- 功能建议、Bug 反馈、文档纠错,通通欢迎!
- 如果你公司在用,也欢迎在评论区打个卡,给后来者一点信心。
最后:别让 KPI 吞噬你的周末
数据人的快乐,从摆脱“复制 CSV + 发截图”开始。用 Lumina,把习惯变流程,把流程变自动化。
- 在线 Demo:https://lumina.zeabur.app/
- 测试账号:
testlumina/123456
觉得还行,来个“三连”(点赞、收藏、转发),下次更新直接安排「更好看的图」和「更聪明的订阅」。
我做了个开源数据应用平台 Lumina:数据人的快乐,终于轮到我了(内含在线 Demo)的更多相关文章
- Airbnb开源 快速搭建企业级BI数据平台
最近在公司做一个数据可视化相关的项目,使用了Airbnb开源维护的企业级BI数据平台superset,相较于tableau这种收费的商业软件,Superset是开源维护的,同时图表的种类和颜值普遍偏高 ...
- 想做一个整合开源安全代码扫描工具的代码安全分析平台 - Android方向调研
想做一个整合开源安全代码扫描工具的代码安全分析平台 - Android方向调研 http://blog.csdn.net/testing_is_believing/article/details/22 ...
- amundsen 来自lyft 的开源数据发现平台
amundsen 是来自lyft 开源的元数据管理.数据发现平台,功能点很全,有一个比较全的前端.后端以及 数据处理框架 参考架构图 说明 从官方介绍以及github代码仓库可以看出还是比较全的整体解 ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- 技术分享:如何用Solr搭建大数据查询平台
0×00 开头照例扯淡 自从各种脱裤门事件开始层出不穷,在下就学乖了,各个地方的密码全都改成不一样的,重要帐号的密码定期更换,生怕被人社出祖宗十八代的我,甚至开始用起了假名字,我给自己起一新网名”兴才 ...
- 大众点评开源分布式监控平台 CAT 深度剖析
一.CAT介绍 CAT系统原型和理念来源于eBay的CAL的系统,CAT系统第一代设计者吴其敏在eBay工作长达十几年,对CAL系统有深刻的理解.CAT不仅增强了CAL系统核心模型,还添加了更丰富的报 ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
- 大数据计算平台Spark内核全面解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着Spark在大数据计算领域的暂露头角,越来越多的 ...
- 2019你该掌握的开源日志管理平台ELK STACK
转载于https://www.vtlab.io/?p=217 在企业级开源日志管理平台ELK VS GRAYLOG一文中,我简单阐述了日志管理平台对技术人员的重要性,并把ELK Stack和Gra ...
随机推荐
- UFT 对文件的处理(scripting.filesystemObject)
1. 文件路劲 2. 文件大小 3.写 4. 读 5. 复制 6. 内容替换
- 彻底禁用Windows更新与安全中心【小白友好】
首先我们需要临时关闭安全中心 1.选择开始图标,点击"设置". 2.找到隐私和安全性后,进入"Windows安全中心" 3.点击开启Windows安全中心. 4 ...
- 对称分组加密—DES算法原理
目录 一些基础概念 时序图 步骤拆分 Reference 本文只关注一个核心任务 -- 如何把 64 位的明文,用 64 位的密钥,加密成 64 位的密文,并执行解密,需要理解这个过程. DES已经很 ...
- 智能手机无音频场景使用时Audio DSP低功耗的处理
智能手机(或智能手表)等用电池的电子设备对功耗比较敏感,因此不管是使用中还是待机时都要做低功耗处理来省电.前面的文章(智能手表音乐播放功耗的优化)讲了一款智能手表在播放音乐时的低功耗优化,这属于音频场 ...
- 从url中获取文件名
比如 https://abc.com/files/xx.zip,或许xx // 文件名转为小驼峰 export const kebabCase_to_camelCase = (fileName) =& ...
- GAMES103 cloth 隐式积分法
简介 隐式积分法 显示积分简单而言是通过, 过去的求解未来. 而隐式积分, 简单而言是我要求解现在, 但是我的未知量中也有现在的未知量. 简单而言就是需要通过方程组的思想来进行求解. 参考文献 代码参 ...
- ETLCloud:新一代ETL数据抽取工具的定义与革新
数据集成.数据治理已经成为推动企业数字化转型的核心动力,现在的企业比任何时候都需要一个更为强大的新一代数据集成工具来处理.整合并转化多种数据源. 而ETL(数据提取.转换.加载)作为数据管理的关键步骤 ...
- SciTech-Mathmatics-Proba. & Stats.: 概率理论的"派系"反直觉:{理论派:经典概率 + 事实派:频率 + 主观派:Belief/经验/判断概率} 和 "建立模型"的 "假设及前提
SciTech-Mathmatics-Proba. & Stats.: 概率理论的"派系"反直觉:{理论派:经典概率 + 事实派:频率 + 主观派:Belief/经验/判断 ...
- Attention、Self-Attention 与 Multi-Head Attention
Corpus语料库与DB数据库 World Knowledge世界常识库:OALD牛津高阶/Synonyms/Phrases/-, 新华字典/成语词典/辞海, 行业词典,大英百科,Wikipedia, ...
- Rust从入门到精通03-变量
1.变量声明语法 Rust 变量必须先声明,后使用. 对于局部变量,常见是声明语法为: let variable : i32 = 100; 由于 Rust 是有自动推导类型功能的,所以后面的 :i32 ...