痛苦调优10小时,我把 Spark 脚本运行时间从15小时缩短到12分钟!
周一我就有个困惑,还写成文章了:如何从 Spark 的 DataFrame 中取出具体某一行,里面提了自己猜想的几种解决方案。
没想到这么快就要面对这个问题了,我用小孩子都听得懂的例子描述一下我在干什么。
简单生动小例子
说一所小学有好几个班级,现在要 以班级为单位 给孩子们按照身高进行排序,并且记录下来。
问题就是,全学校只有一条测身高的尺子,而且因为孩子们过于顽劣等主客观因素,测量身高、按身高排序、登记身高这些过程,必须在一间教室里进行。 没有被轮到测量的班级,就在操场活动。
而最让老师感到头疼的是:组织孩子们进教室这一过程。测身高呀、记录呀、排序呀,都用不了几分钟,唯独让孩子们进教室这件事,要让老师们使出九牛二虎之力,而且特别耗时。
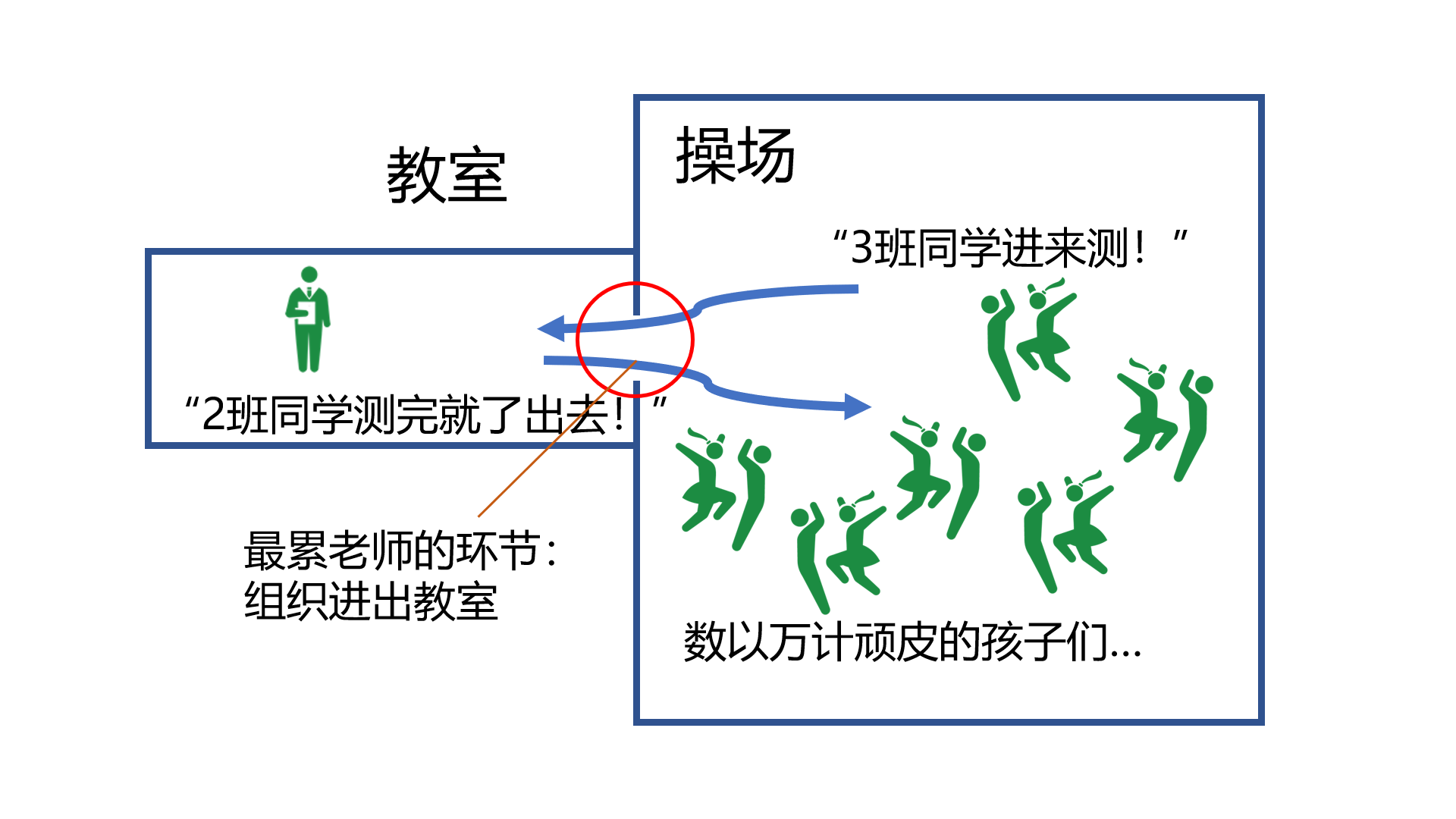
好消息是,组织一个班进教室,和组织一百个班同时进教室,花费的时间差不多。 因此,一般来讲,老师都是直接把所有学生全部叫进这间教室来的。
但是我面临一个棘手的情况。我的操场上,有 2200 个班级,每个班级有 16 万人。我的教室也很大,但是肯定装不下 2200 × 16 万人 ≈ 3 亿人。
于是我就想着,我一个班一个班测,这是最直观的、最好管理的。
“来,一班,进教室!”...花了十几分钟才都叫进来...花了几十秒就都测好了、排好序了、记录好了...“好了!一班出去!二班进来!”...
如此往复,等到了第 2200 个班的时候,已经过去了快一个月...
内位看官讲话了:你把他们都叫进来不就行了?反正前面有条件:『组织一个班进教室,和组织一百个班同时进教室,花费的时间差不多。』
有道理,这就是我上午在做的事:把教室修大一点。
我请了土地局的人、请了工程师、请了施工队,尝试了各种方法,每次费尽力气修好(能容纳 5 亿人那种),教室就因为各种原因塌了。
唉!我计算过,理论上明明可以建成的呀!
我就不甘心,就一直尝试,反反复复,然后几小时过去了。
这是又有位看官讲话了:别修教室了,你把孩子们分成几批,一次叫几个班进教室不就得了!
有道理,可是这样原有的管理逻辑需要改一部分,着实花费了我一些时间。此外,还花了大量时间 debug 。
我初步设置为 100 班为一批进教室:
- 原来我需要做『喊孩子们进教室』这件事 2200 次(每个班含一次)
- 现在我只做『喊孩子们进教室』这件事 22 次,你看看,是不是快了 100 倍
对照解释
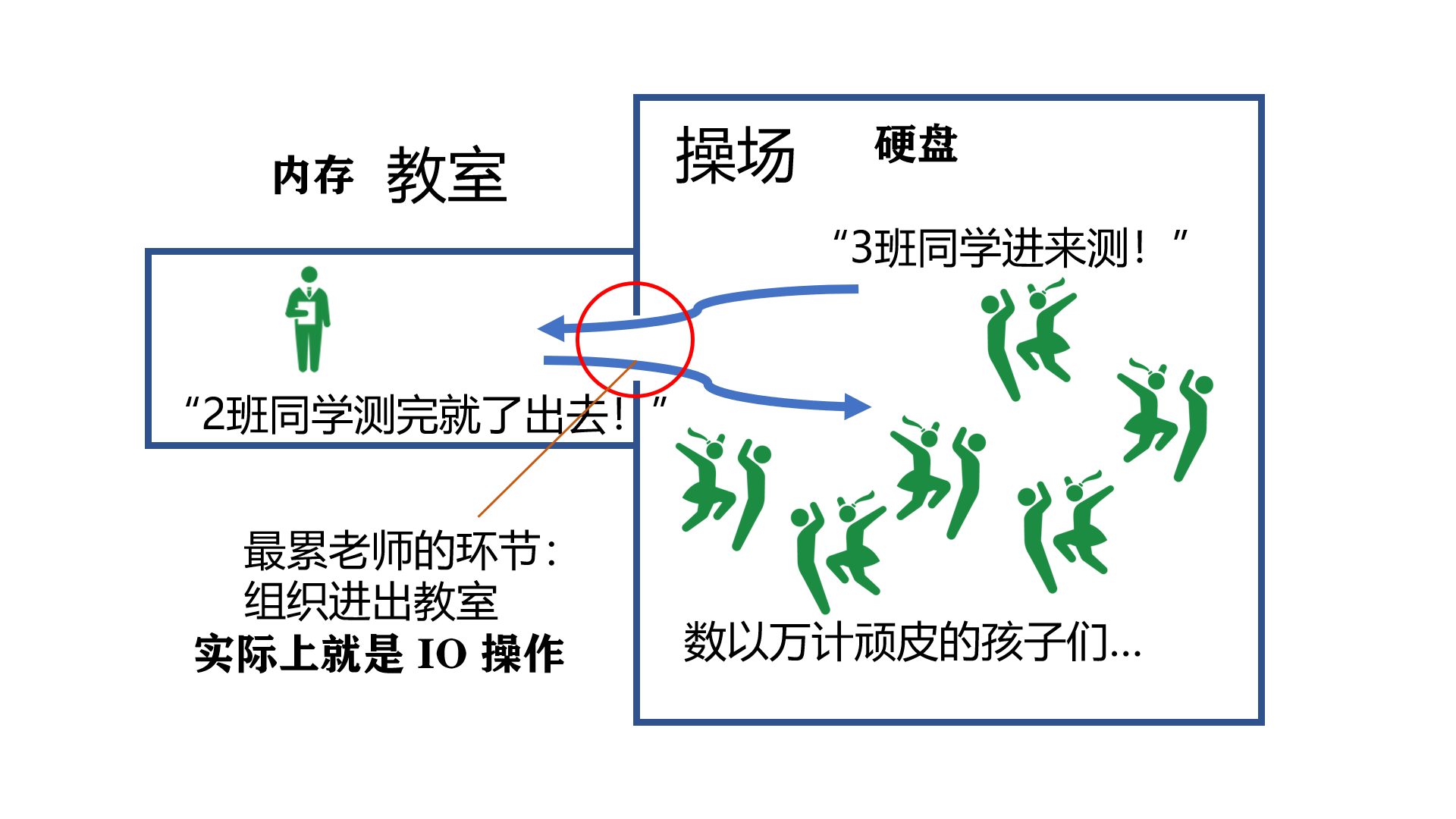
上面其实就是我做的事的简化版,其中:
- 「教室」就是计算机的「内存」,你得把数据拿进内存才能对其进行排序什么的计算
- 「进教室」就是计算机的「IO操作」,计算机的内存很贵,一般的电脑都是 8G、16G 这种,而硬盘相对便宜,有 256G、512G,甚至几个 T 之多,因此数据一般都放在硬盘上,需要用时,在读到内存里,这个读的过程叫做「IO操作」
- 「IO操作」相比计算,相当耗费时间
以下是我的工作日志节选(脱敏版):
首先我是『把每个班级单独叫进教室』,很耗时。
7月19日早上大概9:30开始的,到7月20日半夜0:23结束,一共 2200 列,每一列都有 160000 个数据,都要进行排序操作,还涉及到 IO 操作,一共用时 15 小时。这其中用时为 IO时间 和 对每一列处理时间:
$$\alpha \times time_{\text{IO}} * 列 + \beta \times 行 \log_2{行}$$
而其中,相比 IO ,计算时间(比如排序)可以忽略不计,因此时间可以记为
$$\alpha \times time_{\text{IO}} * 列$$
于是我想着,能不能『把所有班级一下全叫进教室』,毕竟:
- 我的机器内存有 8G
- 数据顶多使用 4G
我开始着手「扩大教室」,尝试了很多,和配置文件 .conf 、 spark-shell 、 spark-env.cmd 、 JVM -Xmx4g 等等这种资料、操作大战了一上午,无果。
我认为我的尝试产生了效果,因为原有的错误不报了, collect 这个过程也能走完(孩子们都能进教室,之前是进不去的),但是一旦涉及到操作(collect 结束后会卡顿很久,无法返回应有的 Array),就会爆 JVM heap 。此外,经过一些其他调整后,不爆 heap 了,爆 GC overhead limit exceeded 这种垃圾回收问题。
那我有理由怀疑是性能被硬件限制了。
于是我考虑:『把孩子们分成几批,一次叫几个班进教室』。
有很多 bug ,我最后选择的是一次叫 100 个班级,用时大概 12 分钟。
“调优”结束。
总体来看,思路上几乎没什么难度,花费了这么多时间,主要是因为:
- 不甘心自己的某个思路不可行,一股脑硬试下去
- 经验不足
啊!要是用时15小时的代码不是1个月前的我写的,而是别人写的,那我把他调到 12 分钟,还显得我蛮厉害的 开个玩笑,我希望大家写出的代码都是很棒的,这样咱们都可以节省出时间休息
好了,回去睡觉了,明天还得接着给“孩子们”做别的工作;而且还有另一所学校另一个工作(同时被领导安排两个工作并行有点难顶啊)。
我是小拍,天津大学研究生在读,微信 PiperLHJ ,如果您也在从事 Spark 相关工作,务必加我微信,我非常需要高手让我骚扰

别忘了点在看~
痛苦调优10小时,我把 Spark 脚本运行时间从15小时缩短到12分钟!的更多相关文章
- shell脚本学习之6小时搞定(1)
shell脚本学习之6小时搞定(1) 简介 Shell是一种脚本语言,那么,就必须有解释器来执行这些脚本. Unix/Linux上常见的Shell脚本解释器有bash.sh.csh.ksh等,习惯上把 ...
- HBase调优案例(三)——Spark访问HBase慢
负载信息:RegionServer:3个 Region:5400多个 现象:在使用Spark对HBase进行scan操作时发现有些task执行比较慢 原因分析:查看Spark应用的executor日志 ...
- 找出1小时内占用cpu最多的10个进程的shell脚本
cpu时间是一项重要的资源,有时,我们需要跟踪某个时间内占用cpu周期最多的进程.在普通的桌面系统或膝上系统中,cpu处于高负荷状态也许不会引发什么问题.但对于需要处理大量请求的服务器来讲,cpu是极 ...
- Ubuntu 14.10 下Ganglia监控Spark集群
由于Licene的限制,没有放到默认的build里面,所以在官方网站下载的二进制文件中并不包含Gangla模块,如果需要使用,需要自己编译.在使用Maven编译Spark的时候,我们可以加上-Pspa ...
- 转 对菜鸟开发者的叮咛:花一万个小时练习Coding,不要浪费一万小时无谓地Debugging
原文见http://blog.jobbole.com/74825/ Coding 之于科技的重要性不言可喻,也不再是软体工程师的专利,医师.律师.会计师.护理师.金融从业人员,甚至是听起来摸不着边的政 ...
- 清北学堂2019.8.10 & 清北学堂2019.8.11 & 清北学堂2019.8.12
Day 5 杨思祺(YOUSIKI) 今天的难度逐渐上升,我也没做什么笔记 开始口胡正解 今天的主要内容是最小生成树,树上倍增和树链剖分 最小生成树 Prim 将所有点分为两个集合,已经和点 1 连通 ...
- uwsgi 启动脚本 每隔三小时重启
针对 s10ops项目 来进行的重启 [root@ayibang-server scripts]# cat /home/liujianzuo/server/scripts/monitor_uwsgi ...
- 10个提供免费PHP脚本下载的网站
本文将重点介绍10个PHP脚本的免费资源下载站.之前推荐 <16个下载超酷脚本的热门网站>,这些网站除了PHP脚本,还有JavaScript.Java.Perl.ASP等脚本.如果你已是脚 ...
- Spark升级--在CDH-5.15.1中添加spark2
一.环境准备 jdk-1.8+scala-2.11.X+python-2.7 二.创建目录 mkdir -p /opt/cloudera/csd 修改权限 chown cloudera-scm:clo ...
- spark脚本日志输出级别设置
import org.apache.log4j.{ Level, Logger } Logger.getLogger("org").setLevel(Level.WARN) Log ...
随机推荐
- centos 安装mbstring(mb_strlen )
部署onethink框架的时候,检测到mb_strlen未支持, 在网上检索一大堆教程,最多的就是先检测一下需要安装的安装包 yum search php 楼主小白满心欢喜地输入,一对照返回的结果, ...
- Linux新建用户无法登陆系统的解决方案
前言 出现这个问题的原因,就是大家没有从基础开始学Linux,导致很多基础操作不会使用,遇到问题反而用搜索引擎搜索,得到一堆相似的答案,你就信了,因为重复就是权威.而你不清楚的是,这个答案是无数人复制 ...
- cv算法工程师成长路线
前言 一,计算机系统 1.1,计算机系统书籍 1.2,设计模式教程 二,编程语言 2.1,C++ 学习资料 2.2,Python 学习资料 三,数据结构与算法 3.1,数据结构与算法课程 3.2,算法 ...
- 一份阅读量30万+免费且全面的C#/.NET面试宝典
前言 C#/.NET/.NET Core相关技术常见面试题汇总,不仅仅为了面试而学习,更多的是查漏补缺.扩充知识面和大家共同学习进步.该知识库主要由自己平时学习实践总结.网上优秀文章资料收集(这一部分 ...
- linux终端高级玩法详细介绍
专注于收集整理更多好玩技巧 更改终端命令行颜色 vi /etc/profile PS1='[\[\e[32m\]\u\[\e[0m\]\[\e[35m\]@\[\e[0m\]\[\e[33m\]\h\ ...
- 在PyCharm中打包Python项目并将其运行到服务器上的方法
在PyCharm中打包Python项目并将其运行到服务器上的方法 在PyCharm中打包Python项目并将其运行到服务器上的过程,可以分解为几个关键步骤:创建项目.设置项目依赖.打包项目.配置服务器 ...
- OSG开发笔记(三十一):OSG中LOD层次细节模型介绍和使用
前言 模型较大的时候,出现卡顿,那么使用LOD(细节层次)进行层次细节调整,可以让原本卡顿的模型变得不卡顿. 本就是LOD介绍. Demo LOD 概述 LOD也称为层次细节模 ...
- php open_basedir的使用
今天跨省问为什么file_exists检测一个相对路径的文件无法获取到true,文件明明有,但是获取不到,我看了一下,感觉可能是因为这个文件是软链接过来的有关系. 然后他找了找发现是和这么一个文件.u ...
- k8s之Helm
官方文档: https://helm.sh/zh/docs/intro/using_helm/ Helm 帮助您管理 Kubernetes 应用-- Helm Chart,Helm 是查找.分享和使用 ...
- 为什么Spring官方不推荐使用 @Autowired?
前言 很多人刚接触 Spring 的时候,对 @Autowired 绝对是爱得深沉. 一个注解,轻松搞定依赖注入,连代码量都省了. 谁不爱呢? 但慢慢地,尤其是跑到稍微复杂点的项目里,@Autowir ...