聚类-31省市居民家庭消费水平-city
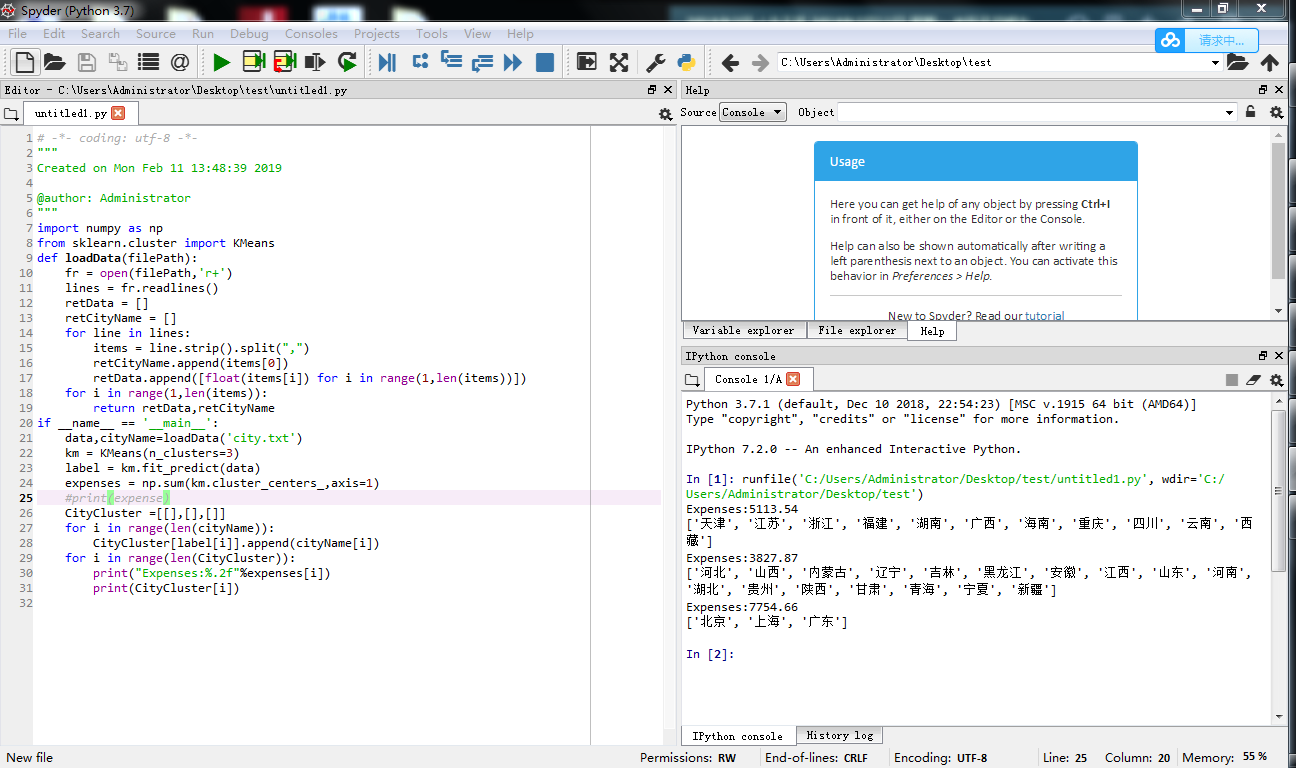
===分三类的=====
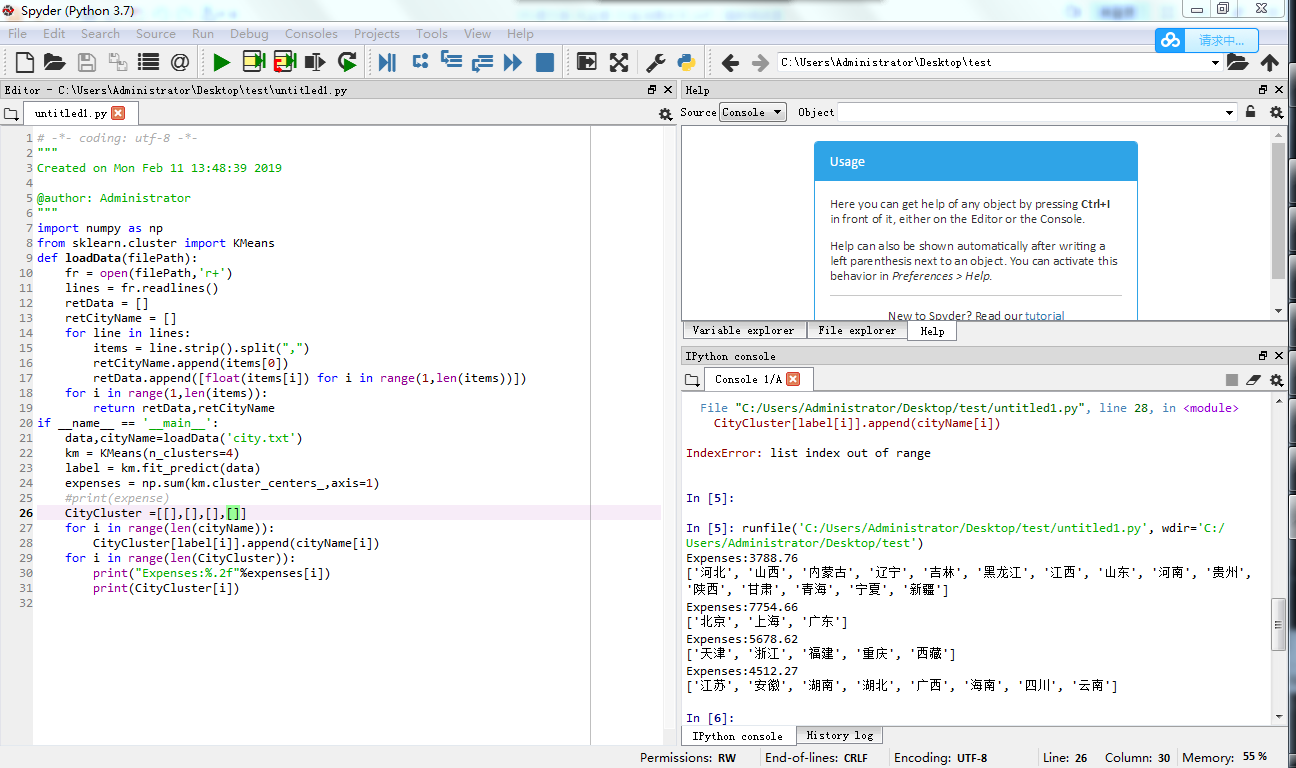
======分四类的========
直接写文件名,那么你的那个txt文件应该是和py文件在同一个路径的
============code===========
import numpy as np
from sklearn.cluster import KMeans
def loadData(filePath):
fr = open(filePath,'r+')
lines = fr.readlines()
retData = []
retCityName = []
for line in lines:
items = line.strip().split(",")
retCityName.append(items[0])
retData.append([float(items[i]) for i in range(1,len(items))])
for i in range(1,len(items)):
return retData,retCityName
if __name__ == '__main__':
data,cityName=loadData('city.txt')
km = KMeans(n_clusters=3)
label = km.fit_predict(data)
expenses = np.sum(km.cluster_centers_,axis=1)
#print(expense)
CityCluster =[[],[],[]]
for i in range(len(cityName)):
CityCluster[label[i]].append(cityName[i])
for i in range(len(CityCluster)):
print("Expenses:%.2f"%expenses[i])
print(CityCluster[i])
=========
- import numpy as np
- from sklearn.cluster import KMeans
- def loadData(filePath):
- fr = open(filePath,'r+')
- lines = fr.readlines()
- retData = []
- retCityName = []
- for line in lines:
- items = line.strip().split(",")
- retCityName.append(items[0])
- retData.append([float(items[i]) for i in range(1,len(items))])
- return retData,retCityName
- if __name__ == '__main__':
- data,cityName = loadData('city.txt')
- km = KMeans(n_clusters=4)
- label = km.fit_predict(data)
- expenses = np.sum(km.cluster_centers_,axis=1)
- #print(expenses)
- CityCluster = [[],[],[],[]]
- for i in range(len(cityName)):
- CityCluster[label[i]].append(cityName[i])
- for i in range(len(CityCluster)):
- print("Expenses:%.2f" % expenses[i])
- print(CityCluster[i])
聚类-31省市居民家庭消费水平-city的更多相关文章
- <第一周> city中国城市聚类 testdata学生上网聚类 例子
中国城市聚类 # -*- coding: utf-8 -*- kmeans算法 """ Created on Thu May 18 22:55:45 2017 @auth ...
- 量化投资学习笔记27——《Python机器学习应用》课程笔记01
北京理工大学在线课程: http://www.icourse163.org/course/BIT-1001872001 机器学习分类 监督学习 无监督学习 半监督学习 强化学习 深度学习 Scikit ...
- 4.无监督学习--K-means聚类
K-means方法及其应用 1.K-means聚类算法简介: k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低.主要处理过程包括: 1.随机选择k个点作为 ...
- Python机器学习--聚类
K-means聚类算法 测试: # -*- coding: utf-8 -*- """ Created on Thu Aug 31 10:59:20 2017 @auth ...
- R语言简单实现聚类分析计算与分析(基于系统聚类法)
聚类分析计算与分析(基于系统聚类法) 下面以一个具体的例子来实现实证分析.2008年我国其中31个省.市和自治区的农村居民家庭平均每人全年消费性支出. 根据原始数据对我国省份进行归类统计. 原始数据如 ...
- ajax省市线三级联动
<script type='text/javascript' src='http://ajax.useso.com/ajax/libs/jquery/1.7.2/jquery.min.js?ve ...
- mysql 省市联动sql 语句
/*MySQL Data TransferSource Host: localhostSource Database: virgoTarget Host: localhostTarget Databa ...
- Ajax省市地区下拉列表三级联动
SQL数据库表 --创建Province表 CREATE TABLE [dbo].[Province]( [Id] [int] NULL, [Name] [varchar](50) NULL, [or ...
- 2018房地产沉思录 z
在中国,房价问题几乎有一个铁律:越调控越暴涨. 刚刚进入5月,全国各地发布的调控政策数量就已经超过了115个.仅4月份,全国各种房地产调控政策合计多达33次,25个城市与部门发布调控政策,其中海南.北 ...
随机推荐
- Vue面试中经常会被问到的面试题
一.对于MVVM的理解 MVVM是 Model-View-ViewModel 的缩写. Model代表数据模型,也可以在Model中定义数据修改和操作的业务逻辑. View代表UI组件,它负责将数据模 ...
- 亲测实验,stm32待机模式和停机模式唤醒程序的区别,以及唤醒后程序入口
这两天研究了STM32的低功耗知识,低功耗里主要研究的是STM32的待机模式和停机模式.让单片机进入的待机模式和停机模式比较容易,实验中通过设置中断口PA1来响应待机和停机模式. void EXTI1 ...
- 利用Pluggable Protocol实现浏览器打开本地应用程序
https://www.cnblogs.com/liushaofeng89/archive/2016/05/03/5432770.html
- Win10系统提示对于目标文件系统过大
Win10系统提示对于目标文件系统过大 今天在复制MAC系统文件时,系统弹出窗口提示“对于目标文件系统,文件XXX过大”.出现这种情况的原因是FAT32的文件系统不支持复制大于4g的单个文件,而NTF ...
- CentOS install duplicity
yum -y updateyum -y install epel-releaseyum -y install ncftp screen # Compilers and related tools:yu ...
- .Net Core跨平台应用研究-HelloDDNS(动态域名篇)
.Net Core跨平台应用研究-HelloDDNS -玩转DDNS 摘要 为解决自己搭建的内网服务器需要域名而因没有超级用户密码不能开启光猫内置DDNS功能的问题,自己动手,基于.net core, ...
- 子线程更新UI界面的2种方法
一.一般我们都会在子线程完成一些耗时的操作. 1.Android中消息机制: 2.知识点: Message:消息,其中包含了消息ID,消息处理对象以及处理的数据等,由MessageQueue统一列队, ...
- PyCharm激活(License server)
打开激活窗口 选择 Activate new license with: License server (用license server 激活) 在 License sever address 处填入 ...
- 使用Microsoft.Office.Interop.Excel.dll 文件来生成excel 文件
日常工作中经常需要将后台的数据导出成excel 格式,这里通过调用微软提供的类库来生成excel 文件. 具体是引用 了Microsoft.Office.Interop.Excel.dll 类库文件 ...
- 教你如何下载并破解IAR
最近参加项目要写STM8的工程的,所以用到IAR,所以就自己安装了一次然后写个心得. 因为我用到的是STM8,所以我就下载了STM8的,不过其他过程都一样的. 首先去到IAR SYSTEMS的官网,找 ...