redis的使用场景和基本数据类型
一:redis使用的场景
redis是一个高性能的NoSQL数据库,特点是高性能,持久存储,适应高并发的应用场景。
下面看看它的使用场景
1、取最新N个数据的操作
比如取网站的最新文章,通过下面方式,我们可以将最新的5000条评论的ID放在Redis的List集合中,并将超出的部分从数据库中获取
1)使用PUSH latest.comments <ID> 命令,向list集合中插入数
2)插入完成后再用LTRIM latest.comments 0 5000 命令使其永远保持最近5000个ID
3)然后我们就可以根据最新需要取最新的5000个评论
比如你还有不同的维度,比如某个分类的最新N条,那么你还可以在新建一个按此分类的List,也只存ID
2、排行榜应用,去TOP N 操作
这个需求与上面不同之处在于,前面的操作时间为权重, 这个是以某条件为权重, 游戏里面比如按等级排序,这时候就可以用sorted set了,将要排序的值设置成 sorted set的score,将具体的数据设置成相应的值,
每次只需要执行一条ZADD命令
3、需要精确设置过期时间的应用
比如你可以把上面说到的sorted set的score值设置成过期时间的时间戳,那么就可以简单地通过过期时间排序,定时清除过期数据了,不仅是清除Redis中的过期数据,你完全可以把 Redis里这个过期时间当成是对数据库中数据的索引,用Redis来找出哪些数据需要过期删除,然后再精准地从数据库中删除相应的记录。
4、 计数器应用
Redis的命令都是原子性的,你可以轻松地利用INCR,DECR命令来构建计数器系统。
5、 Uniq操作,获取某段时间所有数据排重值
这个使用Redis的set数据结构最合适了,只需要不断地将数据往set中扔就行了,set意为集合,所以会自动排重。
6、 实时系统,反垃圾系统
通过上面说到的set功能,你可以知道一个终端用户是否进行了某个操作,可以找到其操作的集合并进行分析统计对比等。没有做不到,只有想不到。
7、 Pub/Sub构建实时消息系统
Redis的Pub/Sub系统可以构建实时的消息系统,比如很多用Pub/Sub构建的实时聊天系统的例子。
8、 构建队列系统
使用list可以构建队列系统,使用sorted set甚至可以构建有优先级的队列系统。
二:数据类型
redis最为常用的数据类型有5种:string,hash,list,set和SortedSet。
redisObj
redis内部使用一个redisObject的对象来表示所有的key和value。redisObj主要信息如下图所示:
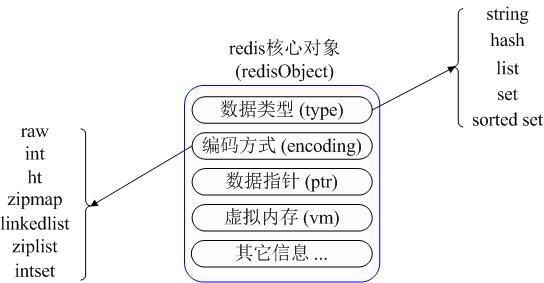
type:代表一个value对象具体是何种数据类型,
encoding:是不同数据类型在redis内部的存储方式,比如:type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值类型存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示。
vm:这里需要特殊说明下vm字段,只有打开了redis的虚拟内存功能,此字段才会真真的分配内存,该功能默认是关闭的。vm的功能我们在稍后讨论,通过上图可以发现redis使用redisObject来表示所有的key-value数据是比较浪费内存的,当然这些内存管理的成本的付出也是为了给redis不同数据类型提供一个统一的管理接口,实际作者也提供了许多方法帮助我们尽量节省内存使用。这个也在稍后探讨。下面我们先来逐一分析下这五种数据类型的使用和内部实现方式
String
常用命令:set,get,decr,incr, mset, mget等。
应用场景:String是最常用的一种数据类型,普通的key-value存储都可以归为此类。
实现方式:String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr,decr等操作时,会转成数值型进行计算,此时redisObject的encoding字段为int。
Hash
常用命令: hmset, hmget, hdel, hlen等。
应用场景
我们简单举个实例来描述下Hash的应用场景,比如我们要存储一个用户信息对象数据,包含以下信息:
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储,主要有以下2种存储方式:
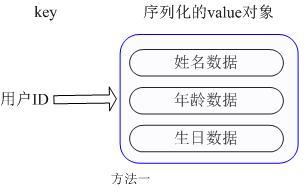
第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
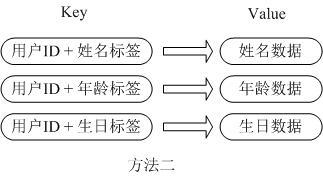
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对儿,用用户ID+对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户ID为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的。
那么Redis提供的Hash很好的解决了这个问题,Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口,如下图:
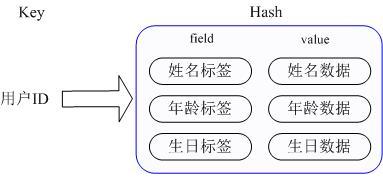
也就是说,Key仍然是用户ID, value是一个Map,这个Map的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。很好的解决了问题。
这里同时需要注意,Redis提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部Map的成员很多,那么涉及到遍历整个内部Map的操作,由于Redis单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应,这点需要格外注意。
实现方式:上面已经说到Redis Hash对应Value内部实际就是一个HashMap,实际这里会有2种不同实现,这个Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,对应的value redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht
List
常用命令: lpush,rpush,lpop,rpop,lrange等。
应用场景: Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现,比较好理解,这里不再重复。
实现方式:Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
Set
常用命令:sadd,spop,smembers,sunion 等。
应用场景:Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
实现方式:set 的内部实现是一个 value永远为null的HashMap(ps:这点和java中set的实现基本相同),实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
Sorted Set
常用命令:zadd,zrange,zrem,zcard等.
使用场景:Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
实现方式:Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
参考:https://blog.csdn.net/u013256816/article/details/51133134
redis的使用场景和基本数据类型的更多相关文章
- Redis的使用场景 by 杨卫华
转载自新浪微博架构师杨卫华的博客 http://timyang.net/tag/redis/,省略了部分内容 按:杨卫华在2010年就已经测试了Redis的性能,并给出了初步的结论:“Redis性能惊 ...
- redis的适应场景
redis应用场景: 1.对数据高并发读写 2.对海量数据的高效存储和访问 3.对数据的高可扩展性和高可用性 做分布式扩展很简单,因为没有固定的表结构 redis介绍: redis是一个key-val ...
- redis 发展史 应用场景
引言 在Web应用发展的初期,那时关系型数据库受到了较为广泛的关注和应用, 原因是因为那时候Web站点基本上访问和并发不高.交互也较少. 而在后来,随着访问量的提升,使用关系型数据库的Web站点多多少 ...
- redis的使用场景和优缺点
使用场景和优缺点: 2 Redis用来做什么? 通常局限点来说,Redis也以消息队列的形式存在,作为内嵌的List存在,满足实时的高并发需求.而通常在一个电商类型的数据处理过程之中,有关商品,热销, ...
- redis系列-redis的使用场景
redis越来越受大家欢迎,提升下速度,做下缓存,完成KPI之利器呀.翻译一篇文章<<How to take advantage of Redis just adding it to yo ...
- Redis 数据结构使用场景
转自http://get.ftqq.com/523.get 一.redis 数据结构使用场景 原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的 ...
- Lua脚本在redis分布式锁场景的运用
目录 锁和分布式锁 锁是什么? 为什么需要锁? Java中的锁 分布式锁 redis 如何实现加锁 锁超时 retry redis 如何释放锁 不该释放的锁 通过Lua脚本实现锁释放 用redis做分 ...
- redis作为缓存场景使用,内存耗尽时,突然出现大量的逐出,在这个逐出的过程中阻塞正常的读写请求,导致 redis 短时间不可用
redis 突然大量逐出导致读写请求block 内容目录: 现象 背景 原因 解决方案 ref 现象 redis作为缓存场景使用,内存耗尽时,突然出现大量的逐出,在这个逐出的过程中阻塞正常的读写请 ...
- redis学习教程二《四大数据类型》
redis学习教程二<四大数据类型> 四大数据类型包括:字符串 哈希 列表 集合一 : Redis字符串 Redis字符串命令用于管理Redis中的字符串 ...
随机推荐
- 手机连接WiFi有感叹号x怎么回事?如何消除手机WiFi感叹号?
经过多年的革新,现在的安卓系统已经非常优秀了,某些程度已经超越iOS,卡顿和耗电也不再是安卓系统的代名词了.而为了体验到最优秀的安卓系统,不少人都会购买海外的手机,因为海外手机的安卓系统都比较精简,非 ...
- Nginx 用最快方式让缓存失效
陶辉103 一般让及时缓存失效针对nginx官方是收费的 我们可以用第三方模块 https://github.com/FRiCKLE/ngx_cache_purge proxy_cache_path ...
- Linux命令归纳
Linux基本命令 Linux Xshell远程连接 ssh 用户名@id地址 例如: ssh root@192.168.11.53 增加类指令 创建文件夹 mkdir 文件名 mkdir -p 路径 ...
- Django-urls路由系统
Django的路由系统 Django 1.11版本 URLConf官方文档 URL配置(URLconf)就像Django 所支撑网站的目录.它的本质是URL与要为该URL调用的视图函数之间的映射表. ...
- 字符串哈希及KMP
字符串很神奇,因为它在计算机中应用很广泛,就每一个程序都需要用到字符串,所以学好字符串是非常重要的. 接下来就介绍两个字符串的基本操作 1:字符串hash 一种可以查找几个字符串有几个不同的字符串. ...
- Android Studio导入jar包
使用开源框架是,可以直接复制源代码到自己的项目(本人在Android Studio中操作报R程序包不存在),也可以使用jar包,下面记录一下今天使用SmartImageView.jar的过程,不记录S ...
- 【BZOJ2431】【HAOI2009】逆序对数列 DP
题目大意 问你有多少个由\(n\)个数组成的,逆序对个数为\(k\)的排列. \(n,k\leq 1000\) 题解 我们考虑从小到大插入这\(n\)个数. 设当前插入了\(i\)个数,插入下一个数可 ...
- Linux查看实时网卡流量的几种方式
Linux查看实时网卡流量的几种方式 来源 https://www.jianshu.com/p/b9e942f3682c 在工作中,我们经常需要查看服务器的实时网卡流量.通常,我们会通过这几种方式查 ...
- 从App业务逻辑中提炼API接口
2.1 从App业务逻辑中提炼API接口 业务逻辑思维导图 功能-业务逻辑思维导图 基本功能模块关系 功能模块接口UML(设计出API) 在设计稿标注API 编写API文档 2.2 设计API的要点 ...
- redis在centos7下安装
https://blog.csdn.net/wzygis/article/details/51705559 1.redis下载地址:http://www.redis.cn/download.html ...