JPA环境配置
JPA概述
JPA(Java Persistence API)的简称,用于持久化的API。
JAVAEE5.0平台标准的ORM的规范使得应用程序以统一的方式访问持久层。
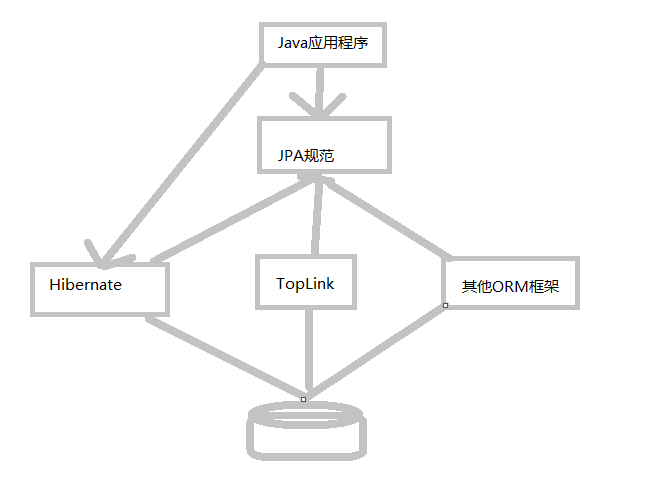
JPA和Hibernate的关系
JPA是Hibernate的一个抽象,就像JDBC和JDBC驱动的关系一样。
PA是规范:JPA本质上是一种ORM规范,不是ORM框架,因为JPA并未提供实现,它只是制定了一些规范,提供了一些编程的API接口,但具体实现则由各ORM厂商提供实现。
Hibernate是实现:Hibernate除了做为一个ORM框架之外,它也是一种JPA实现。从功能上来说,Hibernate是JPA的一个子集。
JPA的优势
标准化: 提供相同的 API,这保证了基于JPA 开发的企业应用能够经过少量的修改就能够在不同的 JPA 框架下运行。
简单易用,集成方便: JPA 的主要目标之一就是提供更加简单的编程模型,在 JPA 框架下创建实体和创建 Java 类一样简单,只需要使用 javax.persistence.Entity 进行注释;JPA 的框架和接口也都非常简单,
可媲美JDBC的查询能力: JPA的查询语言是面向对象的,JPA定义了独特的JPQL,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
支持面向对象的高级特性:JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,最大限度的使用面向对象的模型
JPA的组成
ORM 映射元数据:JPA 支持 XML 和 JDK 5.0 注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中。
JPA 的 API:用来操作实体对象,执行CRUD操作,框架在后台完成所有的事情,开发者从繁琐的 JDBC和 SQL代码中解脱出来。
查询语言(JPQL):这是持久化操作中很重要的一个方面,通过面向对象而非面向数据库的查询语言查询数据,避免程序和具体的 SQL 紧密耦合。
JPA环境配置:
首先我们使用Eclipse来创建一个JPA的项目(我们这里通过Hibernate来实现JPA所以准备好HibernateJar包):


配置好EclipseLink和hibernate的jar包,然后增加数据库连接
项目生成后src下META-INF里面会生成一个persistence.xml,这个文件放着这里面与命名都是规范不需要更改
我们首先来创建个实体类作为测试。Student.java类
package com.miya.jpa.entity;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.NamedQuery;
import javax.persistence.Table;
@Table(name="tal_student")
@Entitypublic class Student {
public Student() {
super();
}
public Student(String name, String pass, Integer age, String phone, String address) {
super();
this.name = name;
this.pass = pass;
this.age = age;
this.phone = phone;
this.address = address;
}
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
private Integer id;
private String name;
private String pass;
private Integer age;
private String phone;
private String address;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPass() {
return pass;
}
public void setPass(String pass) {
this.pass = pass;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + ", pass=" + pass + ", age=" + age + ", phone=" + phone
+ ", address=" + address + "]";
}
}
@Table注解:指定数据表名
@Entity注解:声明持久化类,加上了这个注解必须要有主键所以我这里将ID做为主键使用@Id生命。
@GeneratedValu()注解中配置策略。
然后我们来配置一下persistence.xml文件
<persistence-unit name="JpaDemo1" transaction-type="RESOURCE_LOCAL">
<!-- 指定ORM实现类 -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<!-- 添加持久化类 -->
<class>com.miya.jpa.entity.Student</class>
<properties>
<!-- 配置数据库连接 -->
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="javax.persistence.jdbc.user" value="root" />
<property name="javax.persistence.jdbc.password" value="root" />
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver" />
<!-- Hibernate配置信息 -->
<property name="hibernate.hbm2ddl.auto" value="update" />
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
</properties>
</persistence-unit>
persistence-unit标签上属性
name :用于定义持久化单元的名字,必填项,
transaction-type:直接JAP的事务策略,RESOURCE_LOCAL(默认值),数据库级别的事物。只能针对一种数据库。不支持分布式事务。如果需要分布式事务的支持使用JTA
provider标签:
指定ORM框架的 javax.persistence.spi.PersistenceProvider 接口的实现类。若项目中只有一个实现可省略
main方法:
public static void main(String[] args) {
// 创建工厂
EntityManagerFactory factory = Persistence.createEntityManagerFactory("JpaDemo1");
// 创建与数据库之间的回话
EntityManager manager = factory.createEntityManager();
// 获取事务
EntityTransaction transaction = manager.getTransaction();
// 开启事务
transaction.begin();
Student student = new Student("张三丰", "123123", 22, "12312312312", "中国-未知");
manager.persist(student);
// 提交事务
transaction.commit();
// 关闭资源
manager.close();
factory.close();
}
JPA环境配置的更多相关文章
- Hibernate JPA 中配置Ehcache二级缓存
在Hibernate3 JPA里配置了一下非分布式环境的二级缓存,效果不错.具体过程如下: 1, 需要引入的jar包 http://ehcache.org/downloads/catalog 下载的包 ...
- Spring-Data-Jpa环境配置与实际应用
上次我们讲述了<Spring-Data-Jpa概述与接口>,接下来我们再讲讲Spring-Data-Jpa环境配置与实际应用. Spring-Data 方法定义规范与使用配置 简单条件查询 ...
- Spring JPA 简单配置使用
JPA 常用配置: # JPA (JpaBaseConfiguration, HibernateJpaAutoConfiguration) spring.data.jpa.repositories.b ...
- uboot环境配置
uboot环境配置 通过配置uboot让它在启动过程中从tftp获取内核和设备树,并从在加载内核之后把通过启动参数将"从nfs挂载根文件系统"传入内核.这个配置主要是通过uboot ...
- 史上最全Windows版本搭建安装React Native环境配置
史上最全Windows版本搭建安装React Native环境配置 配置过React Native 环境的都知道,在Windows React Native环境配置有很多坑要跳,为了帮助新手快速无误的 ...
- Electron的环境配置
原文地址http://huisky.com/blog/161218121551123 本文介绍了Electron的环境配置,包括Electron下载.nodejs下载安装.NPM+Bower安装配置. ...
- Python开发环境配置
好久没有写博客了,自从6月份毕业后,进入一家做书法.字画文化宣传的互联网公司(www.manyiaby.com),这段时间一直在进行前端开发,对于后端的使用很少了,整天都是什么html.css.jav ...
- PHP_环境配置_python脚本_2017
Apache配置 需要安装:VC2015 httpd-2.4.16-win32-VC14.zip VC14就是2015的环境. 又比如:php-5.6.12-Win32-VC11-x86 VC11就是 ...
- PHP环境配置
PHP环境配置 1.Apache的安装 第一步: 1. 双击httpd-2.2.17-win32-x86-no_ssl.msi.出现 Windows 标准的软件安装欢迎界面,直接点“Next”继 ...
随机推荐
- easyui 进阶之tree的常见操作
前言 easyui是一种基于jQuery的用户界面插件集合,它为创建现代化,互动,JavaScript应用程序,提供必要的功能,完美支持HTML5网页的完整框架,节省网页开发的时间和规模.非常的简单易 ...
- java中的绝对路径和相对路径
1.基本概念的理解 绝对路径:绝对路径就是你的主页上的文件或目录在硬盘上真正的路径,(URL和物理路径)例如:C:/xyz/test.txt 代表了test.txt文件的绝对路径.http://www ...
- mybatis执行批量更新数据
1.业务需求:同时执行多记录批量操作 2.实现方法: 1)mapping: 2) dao 层 3)Service 层(注意要使用Transactional,否则可能会导致数据紊乱) 4)Con ...
- linux udp 函数说明
int recvfrom(int sockfd,void *buf, int len, unsigned int flags, struct sockaddr *from, int *fromlen) ...
- mongodb系列~mongodb定时删除数据
一 简介:本文介绍创建自动删除数据的TTL索引 二 目的 定时删除数据三 创建方法 db.collection.createIndex(keys, options) options: ex ...
- 配置Oracle GoldenGate安全性
本章介绍如何配置Oracle GoldenGate安全性. 本章包括以下部分: Overview of Oracle GoldenGate Security Options Encrypting Da ...
- 使用CloneDB克隆数据库
本节包含以下主题: 关于使用CloneDB克隆数据库 使用CloneDB克隆数据库 使用CloneDB克隆数据库后 关于使用CloneDB克隆数据库 出于测试目的或其他目的克隆生产数据库通常是必要的. ...
- 编程基础 - 0x00008 的0x代表什么?
总结: 二进制:0dXXXX 八进制:0XXXX 十六进制:0xXXXX ------------------------------- 1- 十六进制 以“0x”开始的数据表示16进制,计算机中每位 ...
- 【转】Java并发编程:同步容器
为了方便编写出线程安全的程序,Java里面提供了一些线程安全类和并发工具,比如:同步容器.并发容器.阻塞队列.Synchronizer(比如CountDownLatch).今天我们就来讨论下同步容器. ...
- 026_nginx引用lua遇到的坑
server { listen 80; listen 443 ssl; server_name www.jyall.com; access_log /data/log/nginx/*.www.jyal ...