用于文本分类的多层注意力模型(Hierachical Attention Nerworks)
论文来源:Hierarchical Attention Networks for Document Classification
1、概述
文本分类时NLP应用中最基本的任务,从之前的机器学习到现在基于词表示的神经网络模型,分类准确度也有了很大的提升。本文基于前人的思想引入多层注意力网络来更多的关注文本的上下文结构。
2、模型结构
多层注意力网络(HAN)的结构如下图所示:

整个网络结构包括四个部分:
1)词序列编码器
2)基于词级的注意力层
3)句子编码器
4)基于句子级的注意力层
整个网络结构由双向GRU网络和注意力机制组合而成,具体的网络结构公式如下:
1)词序列编码器
给定一个句子中的单词 $w_{it}$ ,其中 $i$ 表示第 $i$ 个句子,$t$ 表示第 $t$ 个词。通过一个词嵌入矩阵 $W_e$ 将单词转换成向量表示,具体如下所示:
$ x_{it} = W_e; w_{it}$
接下来看看利用双向GRU实现的整个编码流程:
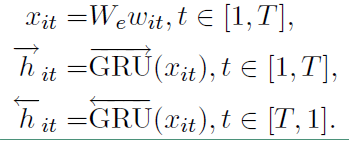
最终的 $h_{it} = [{\rightarrow{h}}_{it}, \leftarrow{h}_{it}]$ 。
2)词级的注意力层
注意力层的具体流程如下:
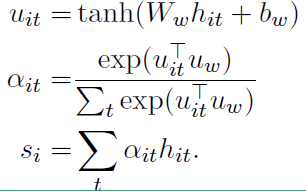
上面式子中,$u_{it}$ 是 $h_{it}$ 的隐层表示,$a_{it}$ 是经 $softmax$ 函数处理后的归一化权重系数,$u_w$ 是一个随机初始化的向量,之后会作为模型的参数一起被训练,$s_i$ 就是我们得到的第 $i$ 个句子的向量表示。
3)句子编码器
也是基于双向GRU实现编码的,其流程如下,
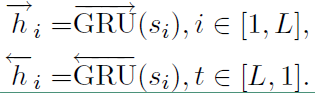
公式和词编码类似,最后的 $h_i$ 也是通过拼接得到的
4)句子级注意力层
注意力层的流程如下,和词级的一致
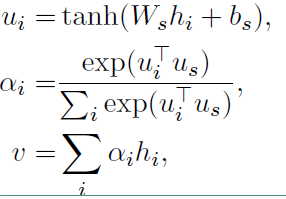
最后得到的向量 $v$ 就是文档的向量表示,这是文档的高层表示。接下来就可以用可以用这个向量表示作为文档的特征。
3、分类
直接用 $ softmax$ 函数进行多分类即可
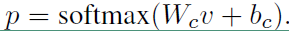
损失函数如下:
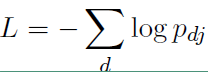
用于文本分类的多层注意力模型(Hierachical Attention Nerworks)的更多相关文章
- 用于文本分类的RNN-Attention网络
用于文本分类的RNN-Attention网络 https://blog.csdn.net/thriving_fcl/article/details/73381217 Attention机制在NLP上最 ...
- 文本分类实战(五)—— Bi-LSTM + Attention模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 将迁移学习用于文本分类 《 Universal Language Model Fine-tuning for Text Classification》
将迁移学习用于文本分类 < Universal Language Model Fine-tuning for Text Classification> 2018-07-27 20:07:4 ...
- 文本分类实战(六)—— RCNN模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 深度学习之文本分类模型-前馈神经网络(Feed-Forward Neural Networks)
目录 DAN(Deep Average Network) Fasttext fasttext文本分类 fasttext的n-gram模型 Doc2vec DAN(Deep Average Networ ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(七)—— Adversarial LSTM模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(四)—— Bi-LSTM模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(三)—— charCNN模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
随机推荐
- spring-framework-中文文档一:IoC容器、介绍Spring IoC容器和bean
5. IoC容器 5.1介绍Spring IoC容器和bean 5.2容器概述 本章介绍Spring Framework实现控制反转(IoC)[1]原理.IoC也被称为依赖注入(DI).它是一个过程, ...
- Web Worker 初探
什么是Web Worker? Web Worker 是Html5 提出的能够在后台运行javascript的对象,独立于其他脚本,不会影响页面的性能,也不会影响你继续对于页面进行操作.通俗点讲,就是后 ...
- Mysql Group by 使用解析
使用gruop by 分组 1. 方式一:select name from table1 group by name; 注意:group by 两侧都应该含有name,例如select country ...
- CSS制作镂空字体
1.效果图 2.html内容: <!doctype html><html lang="en"><head> <meta charset=& ...
- JavaScript 基础(二) - 创建 function 对象的方法, String对象, Array对象
创建 function 对象的两种方法: 方式一(推荐) function func1(){ alert(123); return 8 } var ret = func1() alert(ret) 方 ...
- [转]JS学习总结-技巧、方法、细节
变量转换 var myVar = "3.14159", str = ""+ myVar,// string类型 int = ~~myVar, // number ...
- TFS 2017 持续集成速记
VS2017许多激动人 心的功能,升级! TFS2017也升级,不支持SQL2012,升级!不过貌似开发版不能升级,好吧,开发版升2014企业版! 2017据说不支持XAML生成了,但后台菜单中还 ...
- 在 Centos 安装 MySQL
MySQL是开源的数据库管理系统,通常作为LEMP(Linux, Nginx, MySQL/MariaDB, PHP/Python/Perl)技术栈的一部分,而被安装.RedHat 会害怕 Oracl ...
- Jenkins 安装 on centos7
本文演示如何在CentOS7上安装jenkins. 1 准备工作 1.1 选择安装节点 因为在DevOps实践环境搭建规划中,Jenkins的任务需要执行docker swarm的相关命令,简单起见, ...
- HTMLTestRunner修改成Python3版本
修改前:HTMLTestRunner下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html BSTestRunner 下载地址:htt ...