HashMap 底层分析
以下基于 JDK1.7 分析

如图所示,HashMap底层是基于数组和链表实现的,其中有两个重要的参数:
---容量
---负载因子
容量的默认大小是16,负载因子是0.75,当HashMap的size > 16* 0.75时就会发生扩容(容量和负载因子都可以自由调整)
put方法
首先会将传入的key做hash运算计算出hashcode,然后根据数组长度取模计算出在数组中的index下标
由于在计算中位运算比取模运算效率高的多,所以HashMap规定数组的长度为2^n,这样用2^n -1做位运算与取模效果一致,并且效率还要高处许多。
由于数组的长度有限,所以难免会出现不同的key通过运算得到的index相同,这种情况可以利用链表来解决,HashMap会在table[index]处形成链表,采用头插法将数据插入到链表中。
get方法
get和put类似,也是将传入的key计算出index,如果该位置上是一个链表就需要遍历整个链表,通过key.equals(k)来找到对应的元素。
Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator();
while (entryIterator.hasNext()) {
Map.Entry<String, Integer> next = entryIterator.next();
System.out.println("key=" + next.getKey() + " value=" + next.getValue());
}
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println("key=" + key + " value=" + map.get(key)); }
map.forEach((key,value)->{
System.out.println("key=" + key + " value=" + value);
});
强烈建议使用第一种 EntrySet 进行遍历。
第一种可以把 key value 同时取出,第二种还得需要通过 key 取一次 value,效率较低, 第三种需要 JDK1.8 以上,通过外层遍历 table,内层遍历链表或红黑树。
notice
在并发环境下HashMap容易出现死循环
并发场景发生扩容,调用resize()方法里的rehash()时,容易出现环形链表,这样当获取一个不存在的key时,计算出的index正好是环形链表的下标时就会出现死循环。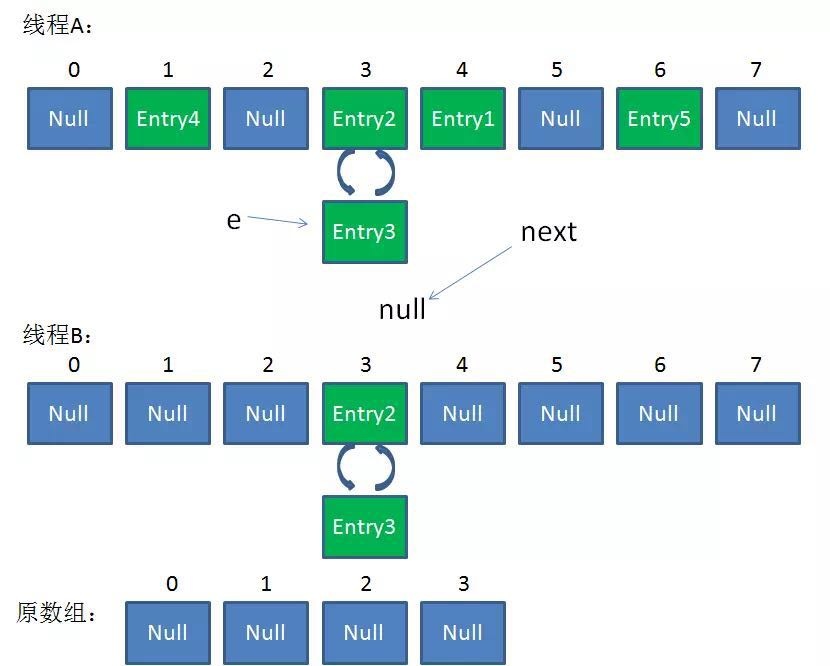
所以 HashMap 只能在单线程中使用,并且尽量的预设容量,尽可能的减少扩容。
在 JDK1.8 中对 HashMap 进行了优化: 当 hash 碰撞之后写入链表的长度超过了阈值(默认为8),链表将会转换为红黑树。
假设 hash 冲突非常严重,一个数组后面接了很长的链表,此时重新的时间复杂度就是 O(n) 。
如果是红黑树,时间复杂度就是 O(logn) 。
大大提高了查询效率。
HashMap 底层分析的更多相关文章
- HashMap底层分析
以下基于 JDK1.7 分析. 如图所示,HashMap 底层是基于数组和链表实现的.其中有两个重要的参数: 容量 负载因子 容量的默认大小是 16,负载因子是 0.75,当 HashMap 的 si ...
- HashMap底层原理分析(put、get方法)
1.HashMap底层原理分析(put.get方法) HashMap底层是通过数组加链表的结构来实现的.HashMap通过计算key的hashCode来计算hash值,只要hashCode一样,那ha ...
- Java——HashMap底层源码分析
1.简介 HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的. HashMap 最多只允许一条记录的key为 nu ...
- ArrayList、LinkedList、HashMap底层实现
ArrayList 底层的实现就是一个数组(固定大小),当数组长度不够用的时候就会重新开辟一个新的数组,然后将原来的数据拷贝到新的数组内. LinkedList 底层是一个链表,是由java实现的一个 ...
- HashMap的分析(转)
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
- HashMap底层结构、原理、扩容机制
https://www.jianshu.com/p/c1b616ff1130 http://youzhixueyuan.com/the-underlying-structure-and-princip ...
- HashMap底层数据结构和算法解析
1.Hash Map的数据结构? A:哈希表结构(链表散列:数组+链表)实现,结合数组和链表的优点.当链表长度超过8时,链表转换为红黑树. transient Node<K,V>[] ta ...
- hashMap 底层原理+LinkedHashMap 底层原理+常见面试题
1.源码 java1.7 hashMap 底层实现是数组+链表 java1.8 对上面进行优化 数组+链表+红黑树 2.hashmap 是怎么保存数据的. 在hashmap 中有这样一个结构 ...
- [转]java 的HashMap底层数据结构
java 的HashMap底层数据结构 HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在.在HashMap中,key-v ...
随机推荐
- Django 创建超级用户
Django自带的后台管理是Django明显特色之一,可以让我们快速便捷管理数据.后台管理可以在各个app的admin.py文件中进行控制 #创建超级用户 python manage.py creat ...
- Django 获取访问者信息
request内的META里有请求用户的信息 #定义视图方法 def get_ip(request): #打印头部所以信息 # print(request.META) # 获取ip信息 if &quo ...
- Django(十二)—关于查询知识点总结
https://www.cnblogs.com/haiyan123/p/7763710.html models.Book.objects.filter(**kwargs): querySet ...
- Day019--Python--反射
1. issubclass, type, isinstance issubclass 判断XXX类是否是XXX类的子类 type 给出XXX的数据类型. 给出创建这个对象的类 isinstance 判 ...
- pytest 6 生成html报告
前言:pytest-HTML是一个插件,pytest用于生成测试结果的HTML报告.兼容Python 2.7,3.6 1.github上源码地址[https://github.com/pytest-d ...
- poj 1523"SPF"(无向图求割点)
传送门 题意: 有一张联通网络,求出所有的割点: 对于割点 u ,求将 u 删去后,此图有多少个联通子网络: 对于含有割点的,按升序输出: 题解: DFS求割点入门题,不会的戳这里
- HTML学习笔记Day11
一.CSS文档统筹 (一)网页自身的优化 (二)CSS规范 1.命名方法(语义化命名,结构化命名) ID:结构化 header footer class: .border0 . red: ...
- 10款 Mac 系统优化清理工具软件推荐和下载
本文内容及图片来源[风云社区 SCOEE] 在Windows上有各种安全卫士.系统助手等系统优化和清理工具,比如360安全卫士.腾讯安全管家等,同样MacOS系统也有很多好用的系统优化清理工具,体验比 ...
- net-snmp开发教程
目录 1................................................................................................ ...
- Linux拉你入门
前言:为了做一个更优秀的程序猿,Linux是必不可少的,因此利用闲杂的时间来增加自己对Linux的认识 (一)关于Linux命令编(至于怎样安装vmvare这一个章节就先不介绍了) 1.基础命令 1. ...