一脸懵逼学习Hive的安装(将sql语句翻译成MapReduce程序的一个工具)
Hive只在一个节点上安装即可:
1.上传tar包:这个上传就不贴图了,贴一下上传后的,看一下虚拟机吧:
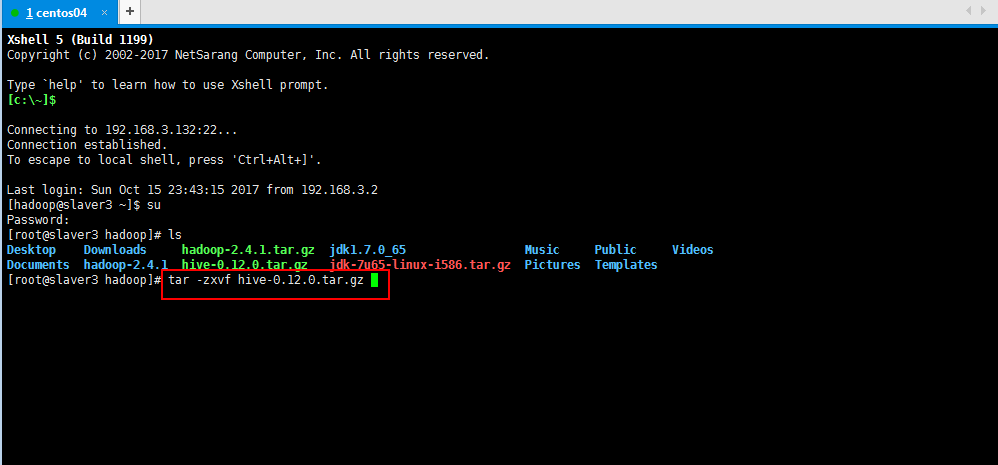
2.解压操作:
[root@slaver3 hadoop]# tar -zxvf hive-0.12.0.tar.gz
解压后贴一下图:
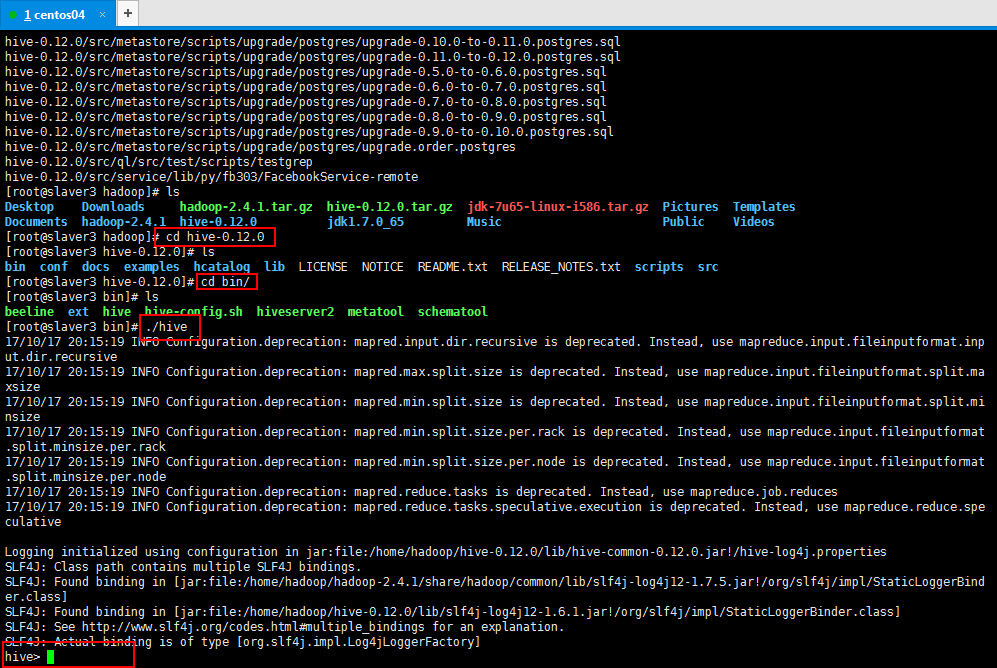
3:解压缩以后启动一下hive:
4:开始操作sql:
好吧,开始没有启动集群,输入mysql创建数据库命令,直接不屌我,我也是苦苦等待啊;
5:启动我的集群,如下所示,这里最后帖一遍部署以后集群关了,重新开启集群的步骤,不能按照部署集群的时候进行格式化一些操作,如下所示:
第一先:启动zookeeper集群(分别在master、slaver1、slaver2上启动zookeeker)
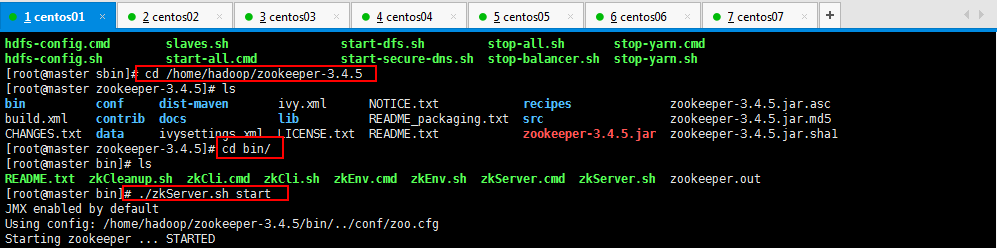


第二步:启动journalnode(分别在master、slaver1、slaver2上启动):
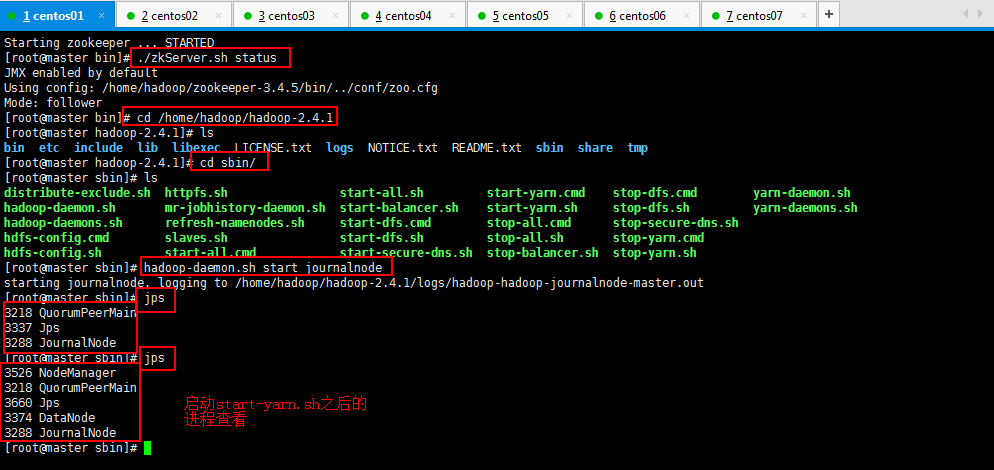
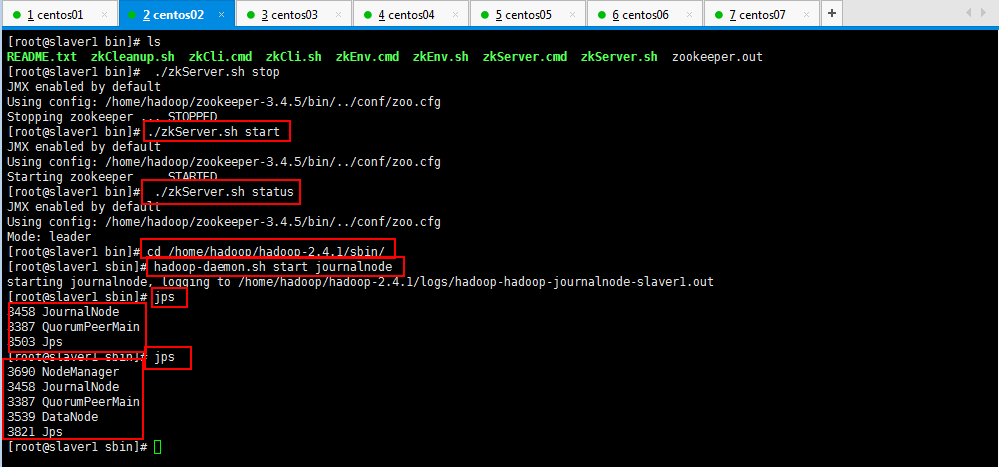
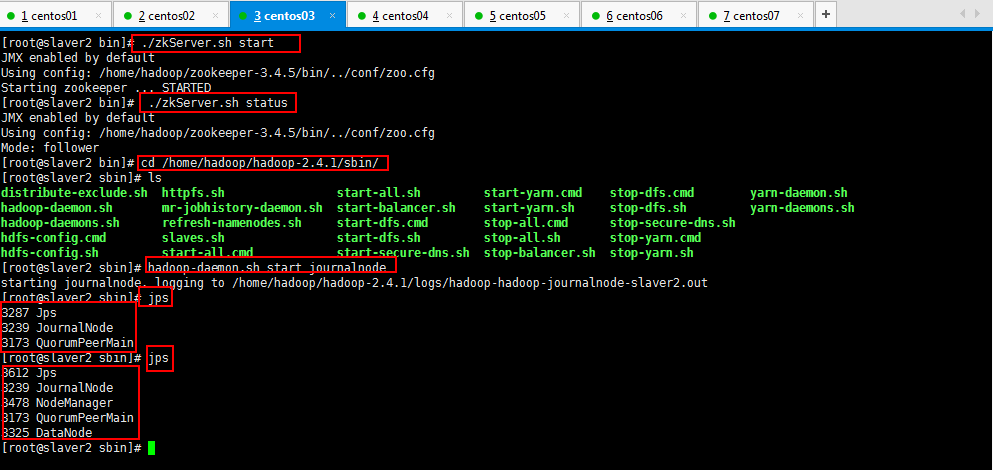
运行jps命令检验,master、slaver1、slaver2上多了JournalNode进程;
第三步:启动HDFS(在slaver3上执行):
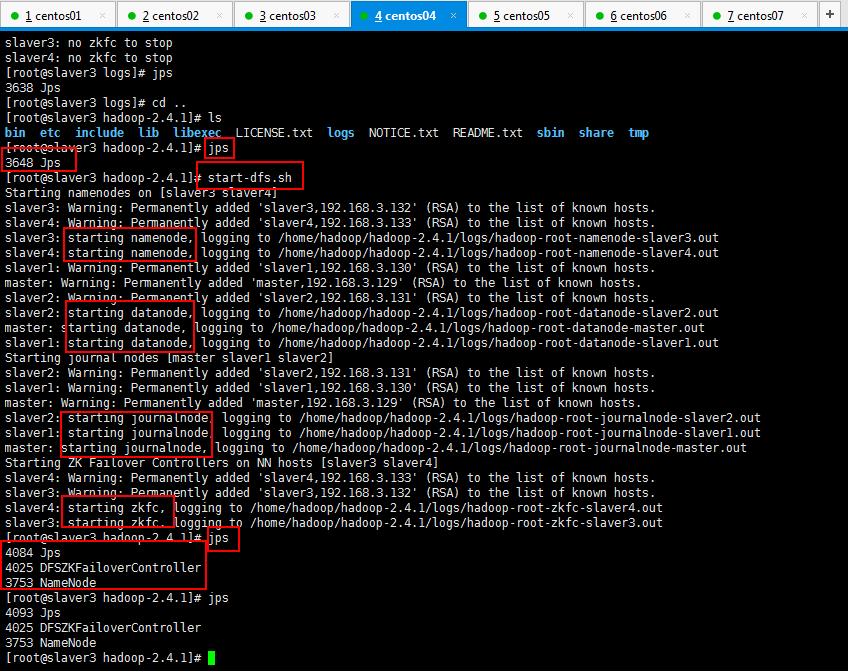
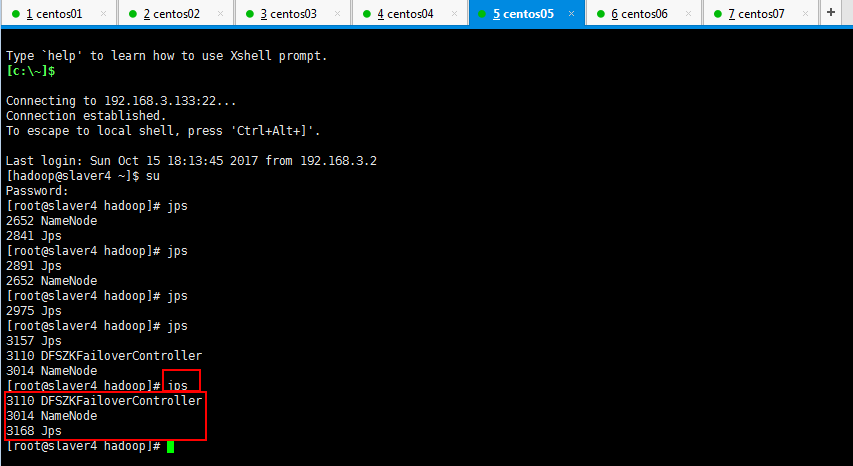
第四步:启动YARN(#####注意#####:是在weekend03上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)


6:然后操作hive,开始居然还报错了,对于一个小白来说,每一个错都是刻骨铭心啊,下面贴一下错误,也许能帮助到他人;

错误如下所示:
hive> create database user;
FAILED: Execution Error, return code from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:Got exception: org.apache.hadoop.ipc.RemoteException org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /user/hive/warehouse/user.db. Name node is in safe mode.
The reported blocks needs additional blocks to reach the threshold 0.9990 of total blocks .
The number of live datanodes has reached the minimum number . Safe mode will be turned off automatically once the thresholds have been reached.
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkNameNodeSafeMode(FSNamesystem.java:)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInt(FSNamesystem.java:)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:)
Caused by: org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /user/hive/warehouse/user.db. Name node is in safe mode.
The reported blocks needs additional blocks to reach the threshold 0.9990 of total blocks .
The number of live datanodes has reached the minimum number . Safe mode will be turned off automatically once the thresholds have been reached.
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkNameNodeSafeMode(FSNamesystem.java:)
... more
)
然后百度了一下,大眼一瞄,可能是防火墙的原因,先关防火墙,先从这种解决问题的方向为入口,不然都是大问题了,然后七台机器的防火墙都关了:
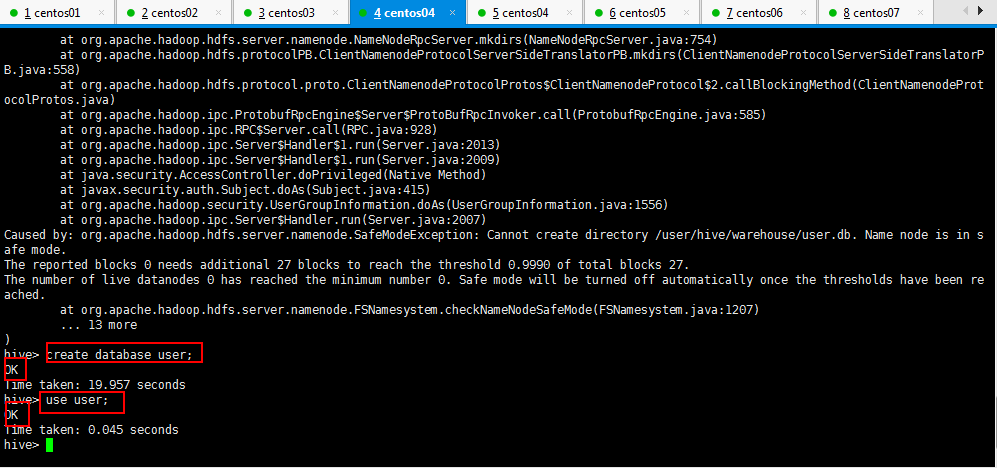
然后就可以了,具体的HIVE学习,待慢慢深学,至少现在入门了;
6:可以将hive配置环境变量,这样就可以在任何位置启动它了,不用每次都要切换到hive的目录了:
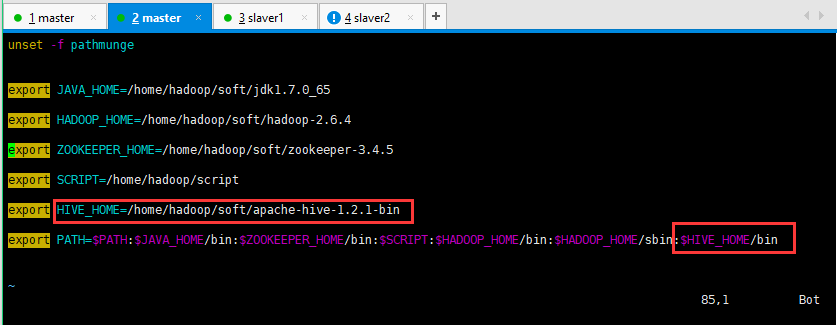
7:启动好hive可以查看数据库(show databases;),创建数据库(create database test;),删除数据库(drop database test;),使用数据库(use test;),创建数据表(create table tb_user(id int,name string);),将数据传输到hadoop分布式集群上面:
创建vim tb_user文件,写上几行数据:
然后将测试数据上传到集群上面:[root@master data_hadoop]# hadoop fs -put tb_user /user/hive/warehouse/test.db/tb_user
可以在浏览器查看到已经上传成功了:
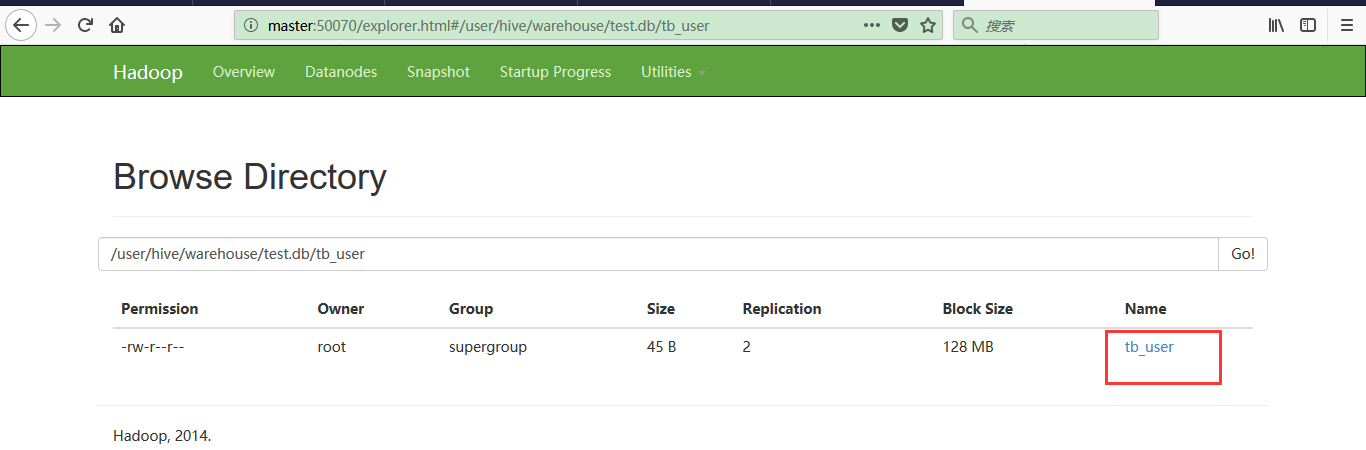
下面可以使用hive命令进行查询操作:
由于上传数据格式的差异化,这里查询需要注意对数据进行定义数据格式;不然无法解析
hive> select * from tb_user;
OK
NULL NULL
NULL NULL
NULL NULL
NULL NULL
NULL NULL
Time taken: 5.338 seconds, Fetched: row(s)
hive>
清空一张表(清空以后还可以继续进行查询,看看是否清空即可):hive> truncate table tb_user;
详细hive的学习见下篇博客,完结;
待续......
一脸懵逼学习Hive的安装(将sql语句翻译成MapReduce程序的一个工具)的更多相关文章
- 【HIVE】sql语句转换成mapreduce
1.hive是什么? 2.MapReduce框架实现SQL基本操作的原理是什么? 3.Hive怎样实现SQL的词法和语法解析? 连接:http://www.aboutyun.com/thread-20 ...
- 一脸懵逼学习Hive的元数据库Mysql方式安装配置
1:要想学习Hive必须将Hadoop启动起来,因为Hive本身没有自己的数据管理功能,全是依赖外部系统,包括分析也是依赖MapReduce: 2:七个节点跑HA集群模式的: 第一步:必须先将Zook ...
- 一脸懵逼学习Hive的使用以及常用语法(Hive语法即Hql语法)
Hive官网(HQL)语法手册(英文版):https://cwiki.apache.org/confluence/display/Hive/LanguageManual Hive的数据存储 1.Hiv ...
- 一脸懵逼学习Hive(数据仓库基础构架)
Hive是什么?其体系结构简介*Hive的安装与管理*HiveQL数据类型,表以及表的操作*HiveQL查询数据***Hive的Java客户端** Hive的自定义函数UDF* 1:什么是Hive(一 ...
- 一脸懵逼学习Hadoop中的序列化机制——流量求和统计MapReduce的程序开发案例——流量求和统计排序
一:序列化概念 序列化(Serialization)是指把结构化对象转化为字节流.反序列化(Deserialization)是序列化的逆过程.即把字节流转回结构化对象.Java序列化(java.io. ...
- 一脸懵逼学习Nginx及其安装,Tomcat的安装
1:Nginx的相关概念知识: 1.1:反向代理: 反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到 ...
- 使用Hive或Impala执行SQL语句,对存储在HBase中的数据操作
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作(二)
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作
http://www.cnblogs.com/wgp13x/p/4934521.html 内容一样,样式好的版本. 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据 ...
随机推荐
- MIPI协议学习总结(一)【转】
转自:https://www.cnblogs.com/EaIE099/p/5200341.html 一.MIPI 简介: MIPI(移动行业处理器接口)是Mobile Industry Process ...
- new-delete-malloc-free关系总结
new-delete-malloc-free关系总结 写在前面的话 这个系列的笔记总结是根据网上的两篇基础拓展而来的 C++经典面试题(最全,面中率最高) C++面试集锦( 面试被问到的问题 ) 面试 ...
- 031_keepalive+nginx保证nginx高可用
一. yum -y install keepalived keepalived配置: keepalived.conf: vrrp_instance proxy { state BACKUP inter ...
- Zeppelin0.7.2结合hive解释器进行报表展示
前提:服务器已经安装好了hadoop_client端即hadoop的环境hbase,hive等相关组件 1.环境和变量配置①拷贝hive的配置文件hive-site.xml到zeppelin-0.7. ...
- Anaconda安装新模块
如果使用import导入的新模块没有安装,则会报错,下面是使用Anaconda管理进行安装的过程:1.打开Anaconda工具,如图: 2.可通过输入 conda list 查看已安装的模块 3.如果 ...
- Mysql41道练习题
1.自行创建测试数据 2.查询“生物”课程比“物理”课程成绩高的所有学生的学号.ps:针对的是自己的生物成绩比物理成绩高,再把符合条件的学生的学号查出来: # 查到 生物 和 物理的 id: sele ...
- 【原创】大数据基础之Logstash(3)应用之file解析(grok/ruby/kv)
从nginx日志中进行url解析 /v1/test?param2=v2¶m3=v3&time=2019-03-18%2017%3A34%3A14->{'param1':' ...
- Linux学习之CentOS(二)--初识linux的一些常用命令
Linux学习之CentOS(二)--初识linux的一些常用命令 在VM上安装完了CentOS6.4以后,看着linux系统成功跑起来,心里小激动了一把......但是前方学习的道路还很遥远... ...
- linux强制将数据写入磁盘,防止丢失内存的数据
sync命令文件系统管理 sync命令用于强制被改变的内容立刻写入磁盘,更新超块信息. 在Linux/Unix系统中,在文件或数据处理过程中一般先放到内存缓冲区中,等到适当的时候再写入磁盘, 以提高系 ...
- linq基本操作
一.Linq有两种语法: 1. 方法语法 2. 查询语法 下面举个例子看看这两种方法的区别 比如现在有一个学生类 public class student { public string user ...