论文阅读笔记十三:The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation(FC-DenseNets)(CVPR2016)

论文链接:https://arxiv.org/pdf/1611.09326.pdf
tensorflow代码:https://github.com/HasnainRaz/FC-DenseNet-TensorFlow
实验代码:https://github.com/fourmi1995/IronSegExperiment-FC-DenseNet.git
摘要
经典的分割结构大致由以下部分构成:(1)用于提取粗略特征的下采样过程。(2)可训练的上采样通道,用于将模型的输出至输入图片大小的分辨率。(3)可选择的加上一个后处理过程,来增强分割边缘,像CRF等。
一种新型的CNN结构DenseNet,其主要思想是在网络的前向传播过程中,每一层网络与其他各层都直接相连,大大提高了网络的准确率,同时,使网络也更易训练。本文,对DenseNet进行改进用于分割任务,此改进网络并没有后处理模型,同时,由于DenseNet结构的优点,改进后的网络现有的模型也具有更少的参数。
介绍
网络很深的CNN在一些标准benchmarks上表现出惊人的效果,但网络由于连续的卷积池化操作大大减少了图像的输入分辨率。FCNs在标准的CNN上增加上采样,来实现模型输出的分辨率恢复(输入分辨率的大小)。因此,FCNs可以处理任意尺寸大小的图片。FCNs通过在下采样与上采样之间引入跳跃结构来恢复分辨率上的损失。
ResNet通过增加一个残差块(将输入的非线性变换与输入相加)来优化深层网络的训练过程。改进ResNet通过引入shortcut paths变为FCN,提高了分割的准确率,同时也加速了模型的收敛。
DenseNet可以看作是ResNet的改进,由dense block和池化操作组成。dense block 由上几层网络的feature maps进行拼接而成。 改进后,DenseNet有如下几个效果:(1)更加有效的利用模型的参数。(2)简介的深层监督,通过引入short paths来实现深层监督。(3)feature resue:通过跳跃结构引入前几层网络的feature map及不同尺寸的信息。
该文将DenseNet引入上采样通道,来恢复输入feature map的分辨率,而这样做的一个缺点是在softmax层前引入大量难以处理的高分辨率feature map,而且,会有大量的filters与feature map进行卷积操作,大大增加了计算量和参数。因此,该文只对dense block后的feature map进行upsampling ,从而在上采样的过程中,每种分辨率的feature map上在不依赖池化层数量的基础上允许有大量的dense block。上采样中的dense block组合相同分辨率下的另一个dense block的特征信息。更高分辨率的信息通过上下采样通道之间的跳跃结构进行连接。网络结构如下,该文贡献:
(1)改进DenseNet结构为FCN用于分割,同时缓解了feature map数量的激增。
(2)根据dense block提出的上采样结构,比普通的上采样方式效果好很多。
(3)该模型不需要预训练模型和后处理过程。

相关工作
分割网络结构上的改进有:(1)改进上采样过程,同时增加全卷积网络内的连接。(2)增加可以获得上下文信息的模型。(3)让FCN具有结构化输出的能力。
(1)不同的方法用于分辨率的恢复,从双线性插值,上采样,到转置卷积,下采样与上采样之间的跳跃结构也可以获得一个更好的恢复效果。
(2)分割网络中利用更多的上下文信息,一种非监督的全局图像描述因子经计算后添加到每个像素的feature map中。RNN从水平和垂直两个方向上进行旋转过的图片中重新提取语义信息。在CNN后端的池化层用空洞卷积进行替换,从而在不减少图像尺寸的条件下捕捉更多的语义信息。
(3)条件随机场CRF在增强分割网络输出的结构连续性上有着较大的影响,同时,近年来,也引入了RNN来近似CRF的优化效果,同时,允许FCN与RNN进行端到端的联合训练。
(4)目前的分割网络仍依赖于预训练的模型(VGG or ResNet)进行训练。
方法
全卷积DenseNets:FCNs主要由上采样,下采样及跳跃结构构成。该文主要针对DenseNet进行改进,并在网络的上采样过程中进行了处理避免feature map 数量激增。该文首先回顾了DenseNets,提出了上采样通道并介绍了他的优点。
DenseNets: x_l 为第l层网络的输出,将上一层网络的输出进行H非线性处理(ReLU或者dropout),得到最终的输出结果。
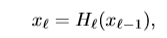
训练较深的网络会产生梯度弥散的情况,ResNet因此引入了残差块,可以将输入与非线性处理后的feature map进行相加处理,进而可以重新利用前面网络的feature map,同时保证前几层网络的梯度可以直接进行传播。注意这里的H代表的意义是,ResNet中重复2到3个由BN,ReLU,和卷积层组成的dense block形式的非线性操作。
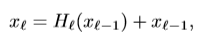
DenseNets的连接模式更加密集,将网络前向过程中的每一个feature map都进行拼接,从而可以使每一层都可以直接接受训练信息,最终,第l层的输出如下,H代表BN,RelU,卷积,DropOut等非线性操作。第l层网络输出由k个feature map,这里,k代表一个参数,所以,DenseNets深度的增加,feature maps的数量也是呈线性的上升。通过一个1x1的卷积与一个大小为2x2的pooling操作组合进而减少feature map空间上的数量。

Dense block 的功能使输入feature map,然后输出新的feature map,结构如下,将通道数m的图片输入第一层网络后,得到通道数为k的featur map ,记为x1,然后与通道数为m的输入x0,进行拼接为[x0,x1],送入到下一层网络中。也得到通道数为k的feature map。这一个dense block中重复n次操作,最终,一个dense block得到n*k个feature map。
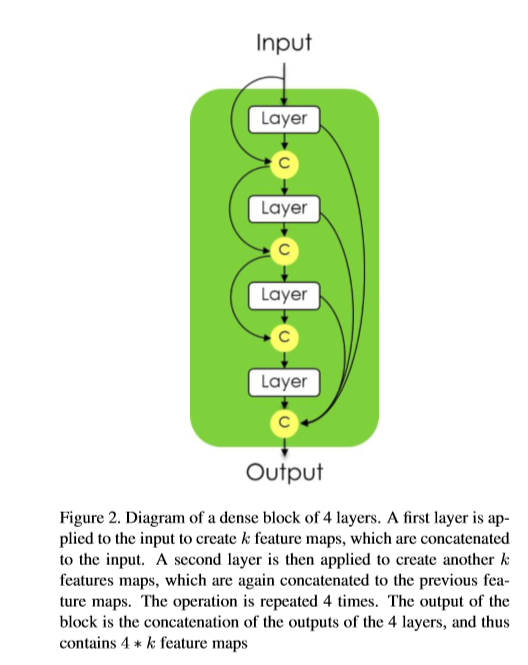
将DesneNets结构组成FC-DenseNet的上采样通道。 下采样过程中,feature map 的数量在增长,但每个feature map经过池化后空间分辨率会有所下降。下采样的最后一层通常是网络的中间部分。
为了恢复输入尺寸的分辨率,FC-DenseNet将卷积操作替换为Desne block和一个上采样操作,其中,这里包含着一个转置卷积用于对以前的feature map上采样。上采样后的feature map与跳跃结构的输出进行级联,然后作为新的dense block的输入。由于上采样过程增加了feature map的空间分辨率,同时,feature map的数量也不少,大大增加了内存的压力,特别是在soltmax前需要输入全部feature map的分辨率。因此,上采样通道的Dense block的输入并不与block输出进行级联,减少空间维度。因此,转置卷积只是在最后一个Dense blokc应用,并没有对所有feature map产生效果。同时,最后一层Desne block结合前几个Dense block相同分辨率信息的feature mapde 信息。在下采样通道中,feature map的信息会有所损失,但通过跳跃结构可以尽可能的利用所有可利用的feature maps。
该文将DenseNet103改进用于分割任务。定义了Desne Block Layer,下变换,上变换,结构组成如下,block layer的输出通道为16

网络的整体结构层数说明:
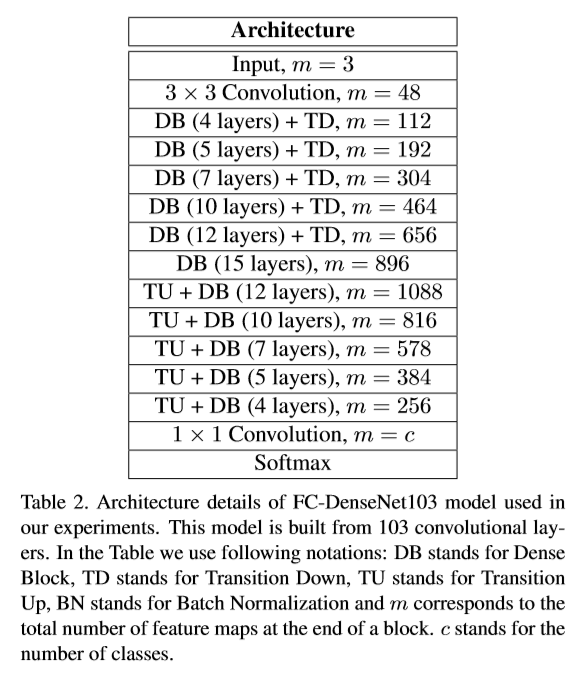
最后经过上采样通道,将feature map的通道数降为256,通过像素级的交叉熵损失进行训练。
实验
在CamVid与Gatech两个数据集上进行实验。
初始化:HeUniform,
优化方法:RMSprop,
learning rate: 1e-3,
exponential decal:0.995,
weight decay:1e-4,
对图片进行随机裁剪与旋转进行数据增强。


Reference
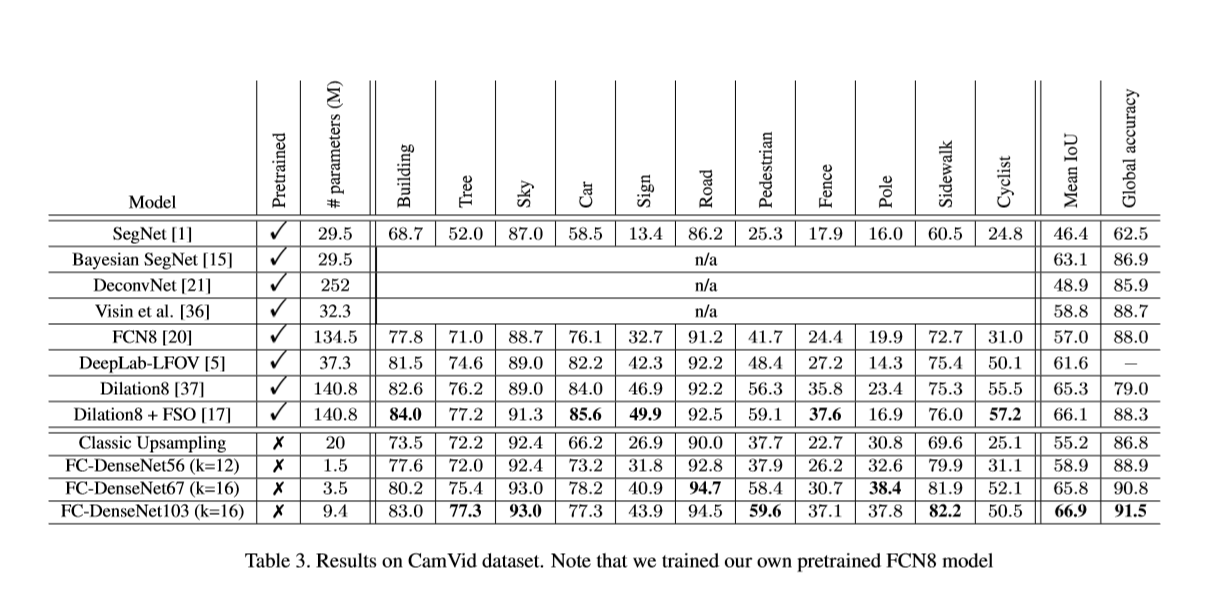
[1] V. Badrinarayanan, A. Kendall, and R. Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. CoRR, abs/1511.00561, 2015.
[2] G. J. Brostow, J. Shotton, J. Fauqueur, and R. Cipolla. Segmentation and recognition using structure from motion point clouds. In European Conference on Computer Vision (ECCV), 2008.
[3] L. Castrejon, Y. Aytar, C. Vondrick, H. Pirsiavash, and A. Torralba. Learning aligned cross-modal representations from weakly aligned data. CoRR, abs/1607.07295, 2016.
个人实验结果
论文阅读笔记十三:The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation(FC-DenseNets)(CVPR2016)的更多相关文章
- 论文阅读笔记十七:RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation(CVPR2017)
论文源址:https://arxiv.org/abs/1611.06612 tensorflow代码:https://github.com/eragonruan/refinenet-image-seg ...
- 论文阅读笔记二十:LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation(CVPR2017)
源文网址:https://arxiv.org/abs/1707.03718 tensorflow代码:https://github.com/luofan18/linknet-tensorflow 基于 ...
- 【Semantic segmentation】Fully Convolutional Networks for Semantic Segmentation 论文解析
目录 0. 论文链接 1. 概述 2. Adapting classifiers for dense prediction 3. upsampling 3.1 Shift-and-stitch 3.2 ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
- 论文阅读笔记六十二:RePr: Improved Training of Convolutional Filters(CVPR2019)
论文原址:https://arxiv.org/abs/1811.07275 摘要 一个训练好的网络模型由于其模型捕捉的特征中存在大量的重叠,可以在不过多的降低其性能的条件下进行压缩剪枝.一些skip/ ...
- 论文笔记(4):Fully Convolutional Networks for Semantic Segmentation
一.FCN中的CNN 首先回顾CNN测试图片类别的过程,如下图: 主要由卷积,pool与全连接构成,这里把卷积与pool都看作图中绿色的convolution,全连接为图中蓝色的fully conne ...
- 论文笔记《Fully Convolutional Networks for Semantic Segmentation》
一.Abstract 提出了一种end-to-end的做semantic segmentation的方法,也就是FCN,是我个人觉得非常厉害的一个方法. 二.亮点 1.提出了全卷积网络的概念,将Ale ...
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
随机推荐
- Akka Quickstart with Java-笔记
官方文档: http://developer.lightbend.com/guides/akka-quickstart-java/?_ga=2.177525157.1012573474.1504767 ...
- 关于Oracle数据库故障诊断基础架构
本节包含有关Oracle数据库故障诊断基础结构的背景信息.它包含以下主题: 故障诊断基础架构概述 关于事件和问题 故障诊断基础设施组件 自动诊断信息库的结构,内容和位置 故障诊断基础架构概述 故障诊断 ...
- UVA1660 电视网络 Cable TV Network
题目地址:UVA1660 电视网络 Cable TV Network 枚举两个不直接连通的点 \(S\) 和 \(T\) ,求在剩余的 \(n-2\) 个节点中最少去掉多少个可以使 \(S\) 和 \ ...
- yum install mariadb安装数据库开启不了
centos7内置的MySQL镜像已经放弃Oracle公司的MySQL,改用MySQL的分支数据库mariaDB,使用以下安装mariadb: yum install mariadb 然后使用命令sy ...
- python中“*”、"*args"、"kwargs"三种用法
参考链接:https://www.cnblogs.com/cwind/p/8996000.html 注意的是: (1)"*"符号的用法很类似C++中的指针,针对列表; (2)&qu ...
- linux下获取微秒级精度的时间【转】
转自:https://blog.csdn.net/u011857683/article/details/81320052 使用C语言在linux环境下获得微秒级时间 1. 数据结构 int getti ...
- Linux 应用层的时间编程【转】
转自:https://blog.csdn.net/chinalj2009/article/details/21223681 浅析 Linux 中的时间编程和实现原理,第 1 部分: Linux 应用层 ...
- Flask请求流程超清大图
补充一下 request是在哪里产生的: class RequestContext(object): # app就是flask对象 self.app = app if request is None: ...
- $Django patch与put,视图组件,路由控制,响应器
1 patch与put(幂等?回顾) PATCH 与 PUT 属性上的一个重要区别还在于:PUT 是幂等的,而 PATCH 不是幂等的.幂等是一个数学和计算机学概念,在计算机范畴内表示一个操作执行任意 ...
- Freemaker:操作集合
<#if (id?index_of('Base') >= 0)> <choose> <when test="rootOrgID !=null and ro ...