聚类——GAKFCM
聚类——GAKFCM
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
参考文献:黄白梅. 基于GA优化的核模糊C均值聚类算法的研究[D]. 武汉科技大学, 2013.
一、遗传算法
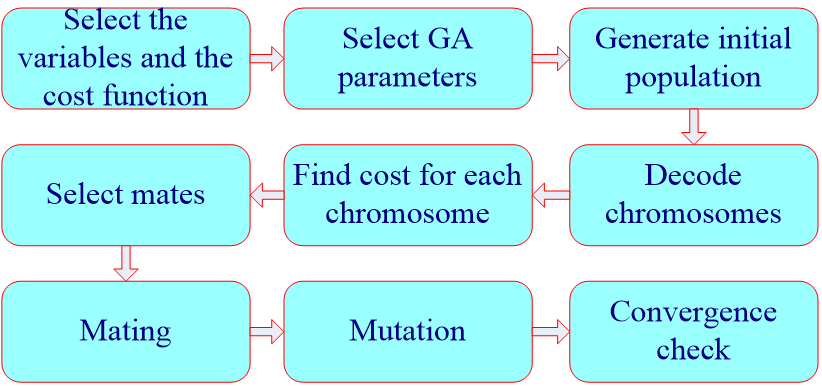
二、算法具体细节
1.Real Coding Mode
Each individual is represented by C×D real numbers, where C is the number of clusters and D is the dimension of the data.
2.Nonlinear Ranking Select Measurement
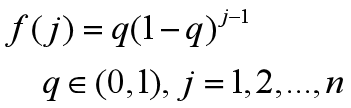
where q is the parameter, j is the sorting number and n is the number of individuals.
3.Adaptive Crossover Strategy
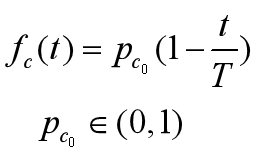
where pc0 is the initial crossover rate, t is the current evolution time of individuals and T is the maximum number of iterations.
4.Adaptive Mutation Strategy
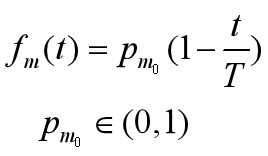
where pm0 is the initial mutation rate, t is the current evolution time of individuals and T is the maximum number of iterations.
5.Fitness Function
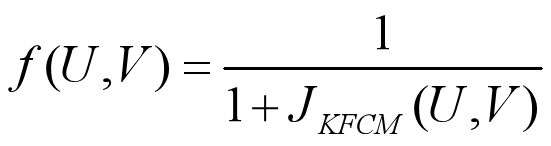
其中JKFCM见聚类——KFCM。
三、算法流程


四、理解
GAKFCM是指用GA进行初始化KFCM的参数(聚类中心)。每个个体的大小与聚类中心的大小一致。
聚类——GAKFCM的更多相关文章
- 聚类——GAKFCM的matlab程序
聚类——GAKFCM的matlab程序 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 在聚类——GAKFCM文章中已介绍了GAKFCM算法的理论知识, ...
- 用scikit-learn学习谱聚类
在谱聚类(spectral clustering)原理总结中,我们对谱聚类的原理做了总结.这里我们就对scikit-learn中谱聚类的使用做一个总结. 1. scikit-learn谱聚类概述 在s ...
- 谱聚类(spectral clustering)原理总结
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
- 用scikit-learn学习DBSCAN聚类
在DBSCAN密度聚类算法中,我们对DBSCAN聚类算法的原理做了总结,本文就对如何用scikit-learn来学习DBSCAN聚类做一个总结,重点讲述参数的意义和需要调参的参数. 1. scikit ...
- DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- 用scikit-learn学习BIRCH聚类
在BIRCH聚类算法原理中,我们对BIRCH聚类算法的原理做了总结,本文就对scikit-learn中BIRCH算法的使用做一个总结. 1. scikit-learn之BIRCH类 在scikit-l ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- 挑子学习笔记:两步聚类算法(TwoStep Cluster Algorithm)——改进的BIRCH算法
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/twostep_cluster_algorithm.html 两步聚类算法是在SPSS Modeler中使用的 ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
随机推荐
- team项目学习01
项目里面有好多单词不理解.先查一下. authorize:授权,批准 controller:控制器 domain:领域,域 form:表格,形式,窗体 interceptor 拦截器,自定义动画渲染器 ...
- HTML学习感悟
HTML是一个超文本语言,原本并不打算做网站的我发现学习信息根本离不开web前端的掌握,因此需要对HTML进行一定程度的学习.对了,它可以说是网页的一个标志,打开任何网页我们看到的都是HTML的文本, ...
- C#文件夹权限操作整理
using System.Security.AccessControl; using System.IO; using System.Security.Principal; 取得目录的访问控制和审核安 ...
- Java马士兵高并发编程视频学习笔记(二)
1.ReentrantLock的简单使用 Reentrant n.再进入 ReentrantLock 一个可重入互斥Lock具有与使用synchronized方法和语句访问的隐式监视锁相同的基本行为和 ...
- kafka指定partition的分区规则
博客地址:https://www.cnblogs.com/gnivor/p/5318319.html
- ES6之Object.assign()详解
译者按: 这篇博客将介绍ES6新增的Object.assign()方法. 原文: ECMAScript 6: merging objects via Object.assign() 译者: Funde ...
- mapper加载的3种方法
<!-- mapper加载有3种方法: 1:通过resource或url加载单个mapper 2:通过mapper接口类名加载单个mapper 3:通过package批量加载多个mapper(推 ...
- markdown 语法指南
说明:左边是markdown的语法 右边是预览.(我这里用了黑色的背景,一般白色较多) 1. 标题 2.列表 3.引用 (1)一层引用 (2)多层引用 4.图片(如果是本地:按照语法写图片路径:如果是 ...
- JavaScript 基础(四) - HTML DOM Event
HTML DOM Event(事件) HTML 4.0 的新特性之一是有能力使 HTML 事件触发浏览器中的动作(action),比如当用户点击某个 HTML 元素时启动一段 JavaScript.下 ...
- 2018-05-09 5分钟入门CTS-尝鲜中文版TypeScript
知乎原链 本文为中文代码示例之5分钟入门TypeScript的CTS版本. CTS作者是@htwx(github). 它实现了关键词和标准库的所有命名汉化. 本文并未使用附带的vscode相关插件(包 ...