Python网络爬虫四大选择器用法原理总结


- 选择所有标签: *
- 选择<a>标 签: a
- 选择所有class=”link” 的元素: .l in k
- 选择 class=”link” 的<a>标签: a.link
- 选择 id= " home ” 的<a>标签: a Jhome
- 选择父元素为<a>标签的所有< span>子标签: a > span
- 选择<a>标签内部的所有<span>标签: a span
- 选择title属性为” Home ” 的所有<a>标签: a [title=Home]
Python网络爬虫四大选择器用法原理总结的更多相关文章
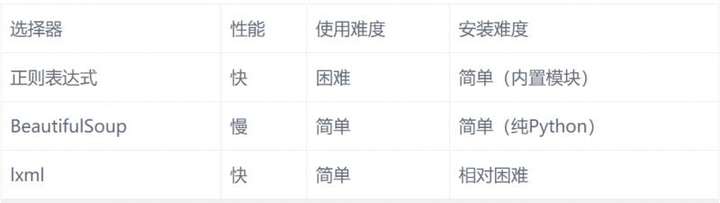
- Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结
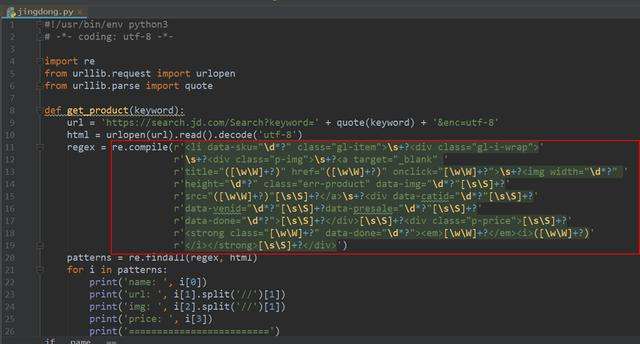
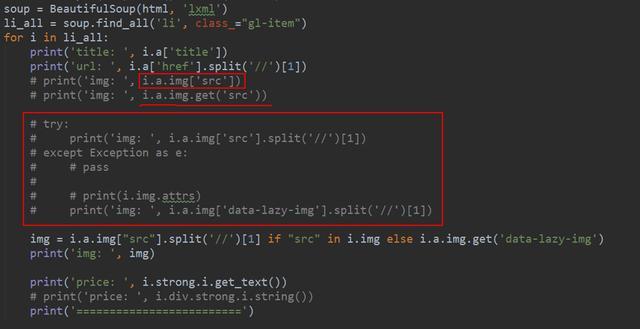
一.正则表达式 正则表达式为我们提供了抓取数据的快捷方式.虽然该正则表达式更容易适应未来变化,但又存在难以构造.可读性差的问题.当在爬京东网的时候,正则表达式如下图所示: 此外 ,我们都知道,网页时常 ...
- python网络爬虫进阶之HTTP原理,爬虫的基本原理,Cookies和代理介绍
目录 一.HTTP基本原理 (一)URI和URL (二)超文本 (三)HTTP和HTTPS (四)HTTP请求过程 (五)请求 1.请求方法 2.请求的网址 3.请求头 4.请求体 (六)响应 1.响 ...
- 利用Python网络爬虫采集天气网的实时信息—BeautifulSoup选择器
相信小伙伴们都知道今冬以来范围最广.持续时间最长.影响最重的一场低温雨雪冰冻天气过程正在进行中.预计,今天安徽.江苏.浙江.湖北.湖南等地有暴雪,局地大暴雪,新增积雪深度4-8厘米,局地可达10-20 ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- Atitit.数据检索与网络爬虫与数据采集的原理概论
Atitit.数据检索与网络爬虫与数据采集的原理概论 1. 信息检索1 1.1. <信息检索导论>((美)曼宁...)[简介_书评_在线阅读] - dangdang.html1 1.2. ...
- Atitit 网络爬虫与数据采集器的原理与实践attilax著 v2
Atitit 网络爬虫与数据采集器的原理与实践attilax著 v2 1. 数据采集1 1.1. http lib1 1.2. HTML Parsers,1 1.3. 第8章 web爬取199 1 2 ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- 《精通python网络爬虫》笔记
<精通python网络爬虫>韦玮 著 目录结构 第一章 什么是网络爬虫 第二章 爬虫技能概览 第三章 爬虫实现原理与实现技术 第四章 Urllib库与URLError异常处理 第五章 正则 ...
- Python网络爬虫学习总结
1.检查robots.txt 让爬虫了解爬取该网站时存在哪些限制. 最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索. 2.检查网站地图(robots.txt文件中发现的Sitemap文件) ...
随机推荐
- Linux上的Systemctl命令
LinuxSystemctl是一个系统管理守护进程.工具和库的集合,用于取代System V.service和chkconfig命令,初始进程主要负责控制systemd系统和服务管理器.通过Syste ...
- JavaWeb网上图书商城完整项目--day02-10.提交注册表单功能之页面实现
1.当从服务器返回的注册错误信息的时候,我们在注册界面需要将错误信息显示出来 我们需要修改regist.jsp页面的代码:其中error是一个haspmap,c标签对map的属性可以直接使用 ${er ...
- activity的四种启动模式详细分析
1.android中通过任务队列来管理activity 采用栈的结构就是后进先出 手机里面如果启动多个应用就会启动多个任务栈来管理对应的activity. 主要解决下面的问题:对应的四种启动模式: 1 ...
- 在树莓派上读取土壤湿度传感器读书-python代码实现及常见问题(全面简单易懂)
本篇文章简单介绍了如何在树莓派上配置土壤湿度传感器以读取土壤湿度(以百分比的形式出现)及代码实现. 主要包含有以下4个模块: 一.土壤湿度传感器常见类型及介绍 二.实验所需设备 三.设备连线方式与代码 ...
- Python3-算法-冒泡排序
冒泡排序 它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来,走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成,这个算法的名字由来是因为越大的元素 ...
- 02【熟悉】springboot和微服务的介绍
1,springboot简介 Spring Boot 是由 Pivotal 团队提供的全新框架,其设计目的是用来简化新 Spring 应用的初始搭建以及开发过程. 该框架使用了特定的方式来进行配置,从 ...
- 数据解析_xpath
重点推荐这种解析方式,xpath是最常用且最便捷高效的一种解析方式,通用性 1.解析原理 1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到改对象中. 2.调用etree对象中的xpa ...
- 硬刚 lodash 源码之路,compact & concat
前置 本篇随笔包含 _.compact 和 _.concat 及其依赖的工具函数. 你可能需要一些 JavaScript 基础知识才能看懂一些没有注释的细节. compact _.compact(ar ...
- 虚拟机 - NAT模式下设置静态 IP 地址
背景 如果不给虚拟机设置静态 IP 地址的话,每次重启机器都会自动分配一个新的 IP 如果有多台虚拟机的话,也会动态获取 IP 动态IP的话,每次 设置静态 IP 的步骤 查看本机 IP 和网关 cm ...
- 面试WEB前端如何才能通过?
从事web前端工作七年时间,因为一直是非常热爱编程的,从小就有兴趣,大学就是学计算机的,技术应该比一般同龄的都要好一些,今天我想给大家讲述一下,目前想要做web前端开发,面试成功应该如何去学习,要具备 ...