Python之 爬虫(十二)关于深度优先和广度优先
- 网站的树结构
- 深度优先算法和实现
- 广度优先算法和实现
网站的树结构
通过伯乐在线网站为例子:
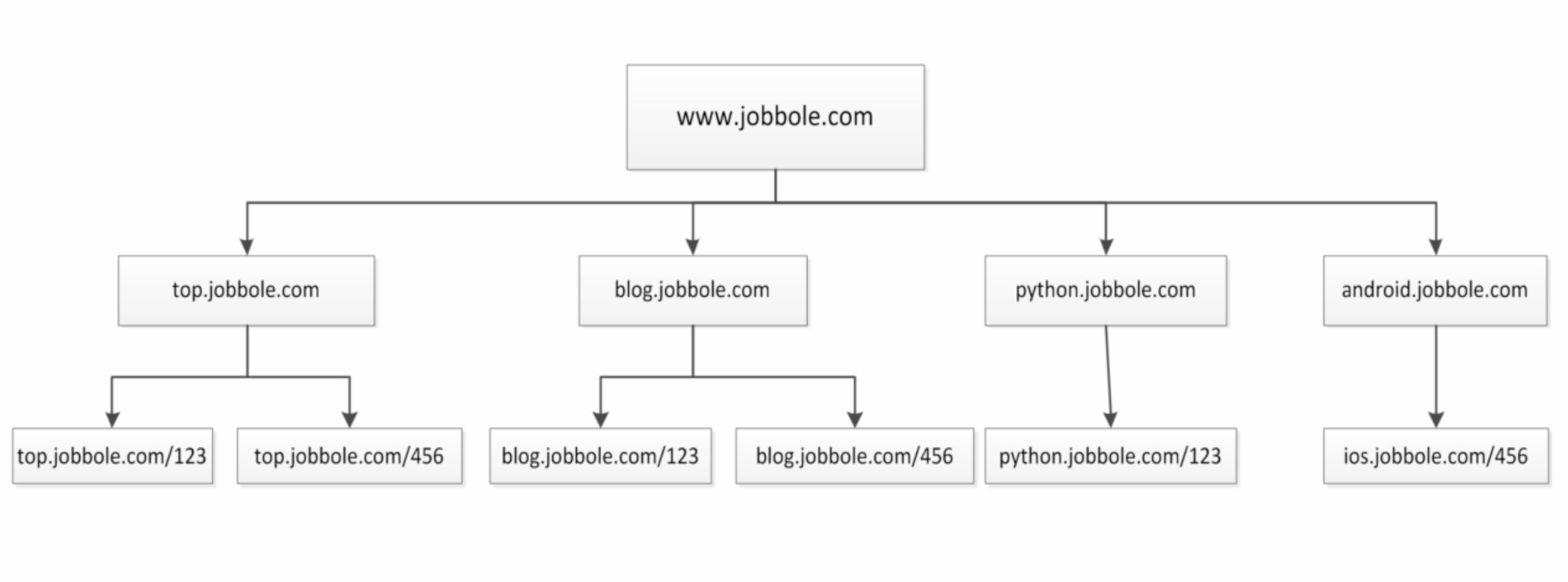
并且我们通过访问伯乐在线也是可以发现,我们从任何一个子页面其实都是可以返回到首页,所以当我们爬取页面的数据的时候就会涉及到去重的问题,我们需要将爬过的url记录下来,我们将上图进行更改

在爬虫系统中,待抓取URL队列是很重要的一部分,待抓取URL队列中的URL以什么样的顺序排队列也是一个很重要的问题,因为这涉及到先抓取哪个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面是常用的两种策略:深度优先、广度优先
深度优先
深度优先是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续追踪链接,通过下图进行理解:
注:scrapy默认采用的是深度优先算法
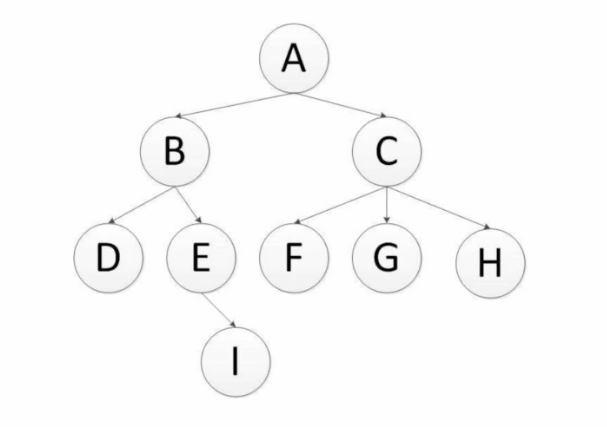
这里是深度优先,所以这里的爬取的顺序式:
A-B-D-E-I-C-F-G-H (递归实现)
深度优先算法的实现(伪代码):

广度优先
广度优先,有人也叫宽度优先,是指将新下载网页发现的链接直接插入到待抓取URL队列的末尾,也就是指网络爬虫会先抓取起始页中的所有网页,然后在选择其中的一个连接网页,继续抓取在此网页中链接的所有网页,通过下图进行理解:

还是以这个图为例子,广度优先的爬取顺序为:
A-B-C-D-E-F-G-H-I (队列实现)
广度优先代码的实现(伪代码):

Python之 爬虫(十二)关于深度优先和广度优先的更多相关文章
- 进击的Python【第十二章】:mysql介绍与简单操作,sqlachemy介绍与简单应用
进击的Python[第十二章]:mysql介绍与简单操作,sqlachemy介绍与简单应用 一.数据库介绍 什么是数据库? 数据库(Database)是按照数据结构来组织.存储和管理数据的仓库,每个数 ...
- python 教程 第二十二章、 其它应用
第二十二章. 其它应用 1) Web服务 ##代码 s 000063.SZ ##开盘 o 26.60 ##最高 h 27.05 ##最低 g 26.52 ##最新 l1 26.66 ##涨跌 c ...
- python 教程 第十二章、 标准库
第十二章. 标准库 See Python Manuals ? The Python Standard Library ? 1) sys模块 import sys if len(sys.argv) ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- python 网络爬虫(二) BFS不断抓URL并放到文件中
上一篇的python 网络爬虫(一) 简单demo 还不能叫爬虫,只能说基础吧,因为它没有自动化抓链接的功能. 本篇追加如下功能: [1]广度优先搜索不断抓URL,直到队列为空 [2]把所有的URL写 ...
- python 网络爬虫(二)
一.编写第一个网络爬虫 为了抓取网站,我们需要下载含有感兴趣的网页,该过程一般被称为爬取(crawling).爬取一个网站有多种方法,而选择哪种方法更加合适,则取决于目标网站的结构. 首先探讨如何安全 ...
- Python爬虫(十二)_XPath与lxml类库
Python学习指南 有同学说,我正则用的不好,处理HTML文档很累,有没有其他的方法? 有!那就是XPath,我们可以用先将HTML文档转换成XML文档,然后用XPath查找HTML节点或元素. 什 ...
- Python之爬虫(二十六) Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎 在通过scra ...
- Python之爬虫(二十五) Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware 通过scrapy官网最新的架构图来理解: 这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可 ...
- Python之爬虫(二十四) 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
随机推荐
- 关键时刻,让你的iphone拒绝掉的所有来电
夜间被骚扰电话吵醒是会非常烦躁的,以下就是iphone的勿扰模式,配合刚出的夜间深夜模式非常的nice. 可以自定义设置时间段,每天智能切换. 也可以开启个人收藏的白名单,让家人有紧急事情也可以联系到 ...
- webdriver中的等待
强制等待:sleep() 设置固定休眠时间,单位为秒. 由python的time包提供, 导入 time 包后就可以使用. 缺点:不智能,使用太多的sleep会影响脚本运行速度. 隐式等待:impli ...
- Eclipse设置断点无效、无法拦截请求进行Debug调试
场景: 在Eclipse中添加Debug断点,从后台页面中点击修改按钮提交数据,发现打断点的地方并没有拦截到请求,接下来对此情况的进行分析. 分析: * 如果页面是根据业务需求复制别的相似html页面 ...
- strcmp函数的两种实现
strcmp函数的两种实现,gcc测试通过. 一种实现: C代码 #include<stdio.h> int strcmp(const char *str1,const char *s ...
- Task.Result跟 Task.GetAwaiter.GetResult()相同吗?怎么选?
前几天在用线程池执行一些任务时运到一种情形,就是回调方法中使用到了异步方法,但是回调方法貌似不支持async await的写法.这时候我应该如何处理呢?是使用Task.Result来获取返回结果,还是 ...
- Mybatis各语句高级用法(未完待续)
更多的语法请参考官网 http://www.mybatis.org/mybatis-3/dynamic-sql.html# 环境:MySQL5.6,jdk1.8 建议:所有的参数加上@Param re ...
- java之FTP上传下载
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import ...
- android handle详解3 ThreadHandler
在android handle详解2的基础上,我们来学习ThreadHandler ThreadHandler的本质就是对android handle详解2的实现 HandlerThread其实还是一 ...
- JavaWEB实现qq邮箱发送验证码——qq1692700664
// 随机验证码public String achieveCode() { String[] beforeShuffle = new String[] { "2", "3 ...
- python文件处理-根据csv文件内容,将对应图像拷贝到指定文件夹
内容涉及:文件遍历,读取csv指定列,拷贝文件,清理和创建文件 # -*- coding: utf-8 -*- import csv import os import sys import numpy ...