jvm优化案例
案例1 survivor区太小,每次Minor GC存活的对象进入老年代,导致老年代可用空间不足,经常发生FULL GC,导致系统变慢
案例问题描述
有一个数据计算系统,从mysql和其他数据源提取数据到jvm进行计算
该系统每分钟大约执行
500次提取数据和计算该系统是分布式的,生产环境部署了多台机器,每台机器大约每分钟执行
100次数据的提取和计算,每次会提取1万条数据到内存进行计算每台机器配置是4核8G,JVM内存给了
4G,新生代和老年代分别是1.5G内存空间每条数据大约
20个字段,一条数据就是1KB大小,计算一万条数据就是10M大小jvm新生代按照
8:1:1分配空间,Eden区是1.2G,每个survivor区是100M每执行一次任务,Eden区就会分配
10M左右的对象,每分钟执行100次,那么一分钟左右,Eden区就会装满对象Eden区占满,会触发Minor GC;Minor GC之前会检查老年代可用空间大小,此时老年代大小
1.5G,大于1.2G,就算Eden区的对象全部存活,老年代也放得下,所以直接进行Minor GC每个jvm每分钟要跑
100次任务,每次任务一万条数据,每条数据1KB,那么每次任务数据就是10M大小;一分钟结尾的时候,Eden区被占满,要进行Minor GC,此时80个任务已经跑完,20个任务还在跑,此时200M对象是存活的,不能被回收,有1GB对象是可以被回收的
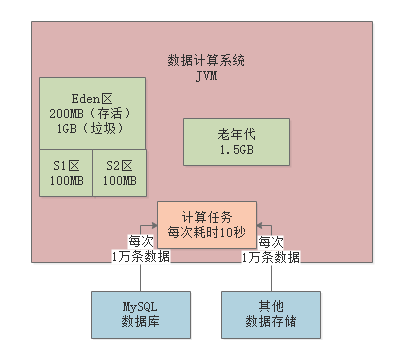
存活对象
200M,survivor区大小是100M,放不下,存活对象直接放入老年代,Eden区清空
每隔一分钟进行一次Minor GC垃圾回收,放入老年代对象有
200M,两分钟以后,老年代放入400M,剩余1.1G,再发生Minor GC时,年轻代对象总大小1.2G大于老年代可用空间1.1G,此时需要进行参数-XX:-HandlePromotionFailure判断,如果设置了该参数,看老年代可用空间是否大于历次Minor GC过后进入老年代的对象的平均大小;1.1G大于200M,直接进行Minor GC,又有200M对象进入老年代七分钟过后,老年代对象变成了
1.4G,可用空间还剩100M第八分钟运行结束时,新生代又满了,执行Minor GC之前检查,发现老年代可用空间
100M,小于存活对象200M大小,直接进行一次FULL GC,回收全部可以回收的1.4G对象总的来说,没7-8分钟就要进行一次FULL GC,频率很高,导致系统很慢
解决方案
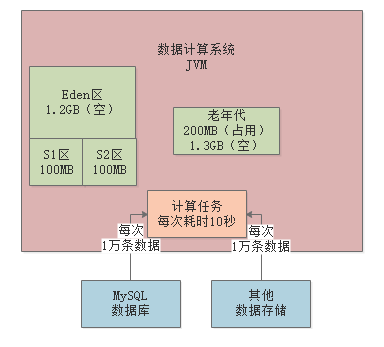
- 增大survivor区大小,使survivor区大于每次Minor GC后存活对象,那么存活对象会放入survivor区,不会进入老年代,避免FULL GC
- 堆内存一共
3G,新生代分配2GB,老年代分配1GB - 这样,每个survivor区是200M左右,放得下Minor GC后存活的对象
- 另外,如果为了防止动态年龄判断,把一些对象直接放入老年代,可修改
-XX:SurvivorRatio=8参数,调整Eden区和Survior区的比例,增大survivor区
案例2 电商大促jvm参数设置调优
- 案例问题描述及其解决方案
- 10分钟50万订单,每秒1000个下单请求(1000QPS),3台机器来负担这些请求,每台机器负责300个请求/秒;每台机器处理100-300请求/秒是正常的
- 每个订单按1KB算,300个订单是300KB;算上其他连带对象,一般对单个对象开销扩大10-20倍
- 除了创建订单,还有其他连带操作,还需再扩大10倍
- 每秒钟有 300KB*20*10 = 60M 的内存开销;但是一秒过后,可以认为这60mb的对象就是垃圾了,因为300个订单处理完了,所有相关对象都失去了引用,可以回收的状态
- 机器8G内存,4G分给jvm,3G分给堆(新生代和老年代分别1.5G),每个线程的Java虚拟机栈有1M,JVM大约几百线程,也就是几百兆,元空间(方法区)256M。以上总和大约为4G
- 每秒处理300个订单,都会占据新生代60M内存空间,新生代1.5G大约25秒就会被占满
- 刚开始,老年代可用内存空间大于新生代对象大小,所以Minor GC直接运行,除了最近一秒的订单请求还在处理,大部分订单早就处理完了,所以此时可能存活对象就100MB左右
-XX:SurvivorRatio参数默认值是8,Eden区和Survivor区比例是8:1:1,Eden区1.2G,每个Survivor区大约是150M- Eden区1.2G大约20秒就会被对象塞满,就要进行Minor GC;清空Eden区,存活对象100M进入S1区(Survivor区)
- 再运行20s,Eden区再次被占满,回收Eden区和S1区的对象,存活对象放入S2区,JVM参数设置如下
-Xms3072M -Xmx3072M -Xmn1536M -Xss1M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:SurvivorRatio=8 - Survivor区150M,存活对象预估100M,但很可能突破150M,导致Minor GC存活的对象Survivor区放不下,频繁进入老年代
- 即使Minor GC存活的对象小于150M,由于是同一批对象,大于Survivor区的百分之50,动态年龄判断,存活对象也会进入老年代,这个jvm参数设置明显Survivor区空间不足
- 对象尽量留在新生代,老年代没必要设置的太大,把新生代调整为2G,老年代调整为1G,Survivor区变为200M,大大降低了Minor GC存活的对象进入老年代的概率
- 其实对任何系统,首先类似上文的内存使用模型预估以及合理的分配内存,尽量让每次Minor GC后的对象都留在Survivor里,不要进入老年代,这是你首先要进行优化的一个地方
- 还有一个问题,新生代存活对象躲过多少次Minor GC进入老年代?
-XX:MaxTenuringThreshold参数默认是15次。设置这个参数必须结合系统的运行模型来说,如果躲过15次Minor GC都几分钟了,一个对象几分钟不被回收,说明肯定是@Service@Controller核心业务逻辑组件,应该放入老年代,甚至这个参数设置成5次,1分钟不被回收的对象尽快进入老年代,不占用新生代空间 - 多大的大对象直接进入老年代?
-XX:PretenureSizeThreshold=1M
- 总结
- 每秒占用多少内存?
- 多长时间触发一次Minor GC?
- 一般Minor GC后有多少存活对象?
- Survivor能放的下吗?
- 会不会频繁因为Survivor放不下导致对象进入老年代?
- 会不会因动态年龄判断规则进入老年代?
本文参考救火队长jvm专栏

jvm优化案例的更多相关文章
- Spark集群之yarn提交作业优化案例
Spark集群之yarn提交作业优化案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.启动Hadoop集群 1>.自定义批量管理脚本 [yinzhengjie@s101 ...
- 数据库优化案例——————某市中心医院HIS系统
记得在自己学习数据库知识的时候特别喜欢看案例,因为优化的手段是容易掌握的,但是整体的优化思想是很难学会的.这也是为什么自己特别喜欢看案例,今天也开始分享自己做的优化案例. 最近一直很忙,博客产出也少的 ...
- JVM优化
1.堆大小设置 JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制:系统的可用虚拟内存限制:系统的可用物理内存限制.32位系统下,一般限制在1.5G~2G:64 ...
- JVM 优化问题
jvm 优化问题 JVM堆内存分为2块:Permanent Space 和 Heap Space. Permanent 即 持久代(Permanent Generation),主要存放的是Java类定 ...
- mysql优化案例
MySQL优化案例 Mysql5.1大表分区效率测试 Mysql5.1大表分区效率测试MySQL | add at 2009-03-27 12:29:31 by PConline | view:60, ...
- SQL 优化案例 1
create or replace procedure SP_GET_NEWEST_CAPTCHA( v_ACCOUNT_ID in VARCHAR2, --接收短信的手机号 v_Tail_num i ...
- 老李案例分享:Weblogic性能优化案例
老李案例分享:Weblogic性能优化案例 POPTEST的测试技术交流qq群:450192312 网站应用首页大小在130K左右,在之前的测试过程中,其百用户并发的平均响应能力在6.5秒,性能优化后 ...
- Hive优化案例
1.Hadoop计算框架的特点 数据量大不是问题,数据倾斜是个问题. jobs数比较多的作业效率相对比较低,比如即使有几百万的表,如果多次关联多次汇总,产生十几个jobs,耗时很长.原因是map re ...
- 数据库优化案例——————某知名零售企业ERP系统
写在前面 记得在自己学习数据库知识的时候特别喜欢看案例,因为优化的手段是容易掌握的,但是整体的优化思想是很难学会的.这也是为什么自己特别喜欢看案例,今天也分享自己做的优化案例. 之前分享过OA系统.H ...
随机推荐
- 经典DP动规 0-1背包问题 二维与一维
先上代码 b站讲解视频 灯神讲背包 #include <iostream> #include <cstring> #include <algorithm> usin ...
- CefSharp如何判断页面是否加载完
问题:CefSharp如何判断页面是否加载完毕. 摘要:相信C#用CefSharp做浏览器来发的应该有很多人都会有遇到这个问题.特别是要执行JavaScript的时候,涉及到跨页面的JavaScrip ...
- Python 逆向抓取 APP 数据
今天继续给大伙分享一下 Python 爬虫的教程,这次主要涉及到的是关于某 APP 的逆向分析并抓取数据,关于 APP 的反爬会麻烦一些,比如 Android 端的代码写完一般会进行打包并混淆加密加固 ...
- Linux文件描述符与重定向
文件描述符可以理解为linux跟踪打开文件,而分配的一个数字,这个数字有点类似c语言操作文件时候的句柄,通过句柄就可以实现文件的读写操作. 当Linux启动的时候会默认打开三个文件描述符,分别是: 标 ...
- Typed Lua
https://the-ravi-programming-language.readthedocs.io/en/latest/ravi-overview.html https://github.com ...
- SpiderMonkey教程
https://technotales.wordpress.com/2009/06/07/spidermonkey-introduction/ https://developer.mozilla.or ...
- Hihocoder 小Hi小Ho扫雷作死一二三
这里贴下不用枚举方格是否为雷的方法 a表示输入标号,初始值为-1代表未探知 b表示当前格子是否有雷,初始化为0,0表示未探知,1表示探知肯定有雷,2表示探知肯定无雷(我也不知道为什么不初始化为-1,作 ...
- 这应该是最适合国内用户的K3s HA方案
前 言 在面向生产环境的实践中,高可用是我们无法避免的问题,K3s本身也历经多个版本的迭代,HA方案也进行了不断优化,形成了目前的比较稳定的HA方案. 目前官方提供两种HA方案: 嵌入式DB的高可用( ...
- 阿里云前端路线 | CSS快速掌握
1.1什么是CSS 翻译为“层叠样式表”或者“级联样式表”, 简称样式表. 1.2CSS的主要作用 它主要是用来给HTML网页来设置外观或者样式 外观或者样式:HTML网页中的文字的大小.颜色.字体, ...
- 360浏览器最小字号12的坑 -彻底搞清rem
之前做响应式网站,使用rem作为单位.因为浏览器的默认字号是16px,设置html {font-size: 62.5%; /*10 ÷ 16 × 100% = 62.5%*/},刚好1rem =10p ...