Mac部署spark2.4.4
环境信息
- 操作系统:macOS Mojave 10.14.6
- JDK:1.8.0_211 (安装位置:/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jdk/Contents/Home)
前提条件
请参考《Mac部署hadoop3(伪分布式)》一文,在Mac上事先部署好hadoop3
部署步骤
- 安装scala:
brew install scala
- 配置scala的环境变量,打开文件~/.bash_profile,增加以下配置内容:
export SCALA_HOME=/usr/local/Cellar/scala/2.13.0
export PATH=$PATH:$SCALA_HOME/bin
- 执行命令source ~/.bash_profile,再验证scala:
base) zhaoqindeMBP:~ zhaoqin$ scala -version
Scala code runner version 2.13.0 -- Copyright 2002-2019, LAMP/EPFL and Lightbend, Inc.
- 下载spark,地址是:http://spark.apache.org/downloads.html ,如下图红框:
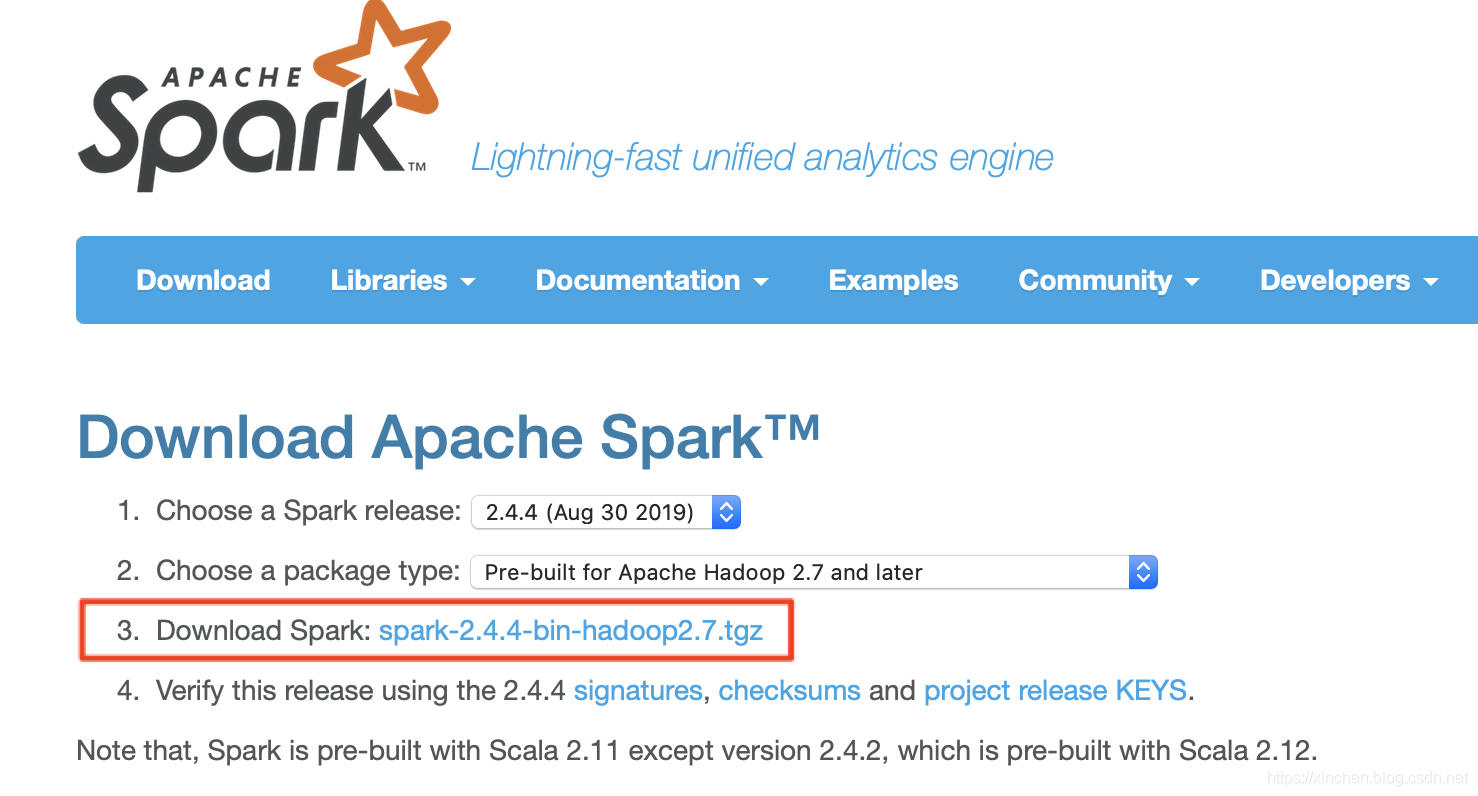
- 将下载的文件在/usr/local/目录下解压,并将文件夹名字从spark-2.4.4-bin-hadoop2.7改为spark
- 配置spark的环境变量,打开文件~/.bash_profile,增加以下配置内容:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
- 执行命令source ~/.bash_profile使配置生效;
- 打开文件spark/conf/spark-env.sh,在尾部增加以下三行:
export SCALA_HOME=/usr/local/Cellar/scala/2.13.0
export SPARK_MASTER_IP=localhost
export SPARK_WORKER_MEMORY=2G
- 确保hdfs和yarn已经启动,然后执行命令spark-shell,即可启动spark服务:
To update your account to use zsh, please run `chsh -s /bin/zsh`.
For more details, please visit https://support.apple.com/kb/HT208050.
(base) zhaoqindeMBP:~ zhaoqin$ spark-shell
19/10/27 13:33:51 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://zhaoqindembp:4040
Spark context available as 'sc' (master = local[*], app id = local-1572154437623).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_211)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
至此,Mac机器上的hadoop和spark都运行起来了,希望本文能给您带来一些参考。
https://github.com/zq2599/blog_demos
Mac部署spark2.4.4的更多相关文章
- mac 部署安装接口自动化持续集成 jmeter+ant+jenkins
由于前段时间刚换的工作,公司用的是mac电脑办公,之前办公都是windows系统.刚开始使用时连基本的操作都要去找度娘,很不习惯,新电脑开始就是安装相关的工作工具 下面就说说遇到的哪些坑. 1. m ...
- Mac部署hadoop3(伪分布式)
环境信息 操作系统:macOS Mojave 10.14.6 JDK:1.8.0_211 (安装位置:/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jd ...
- Hadoop生态圈-通过CDH5.15.1部署spark1.6与spark2.3.0的版本兼容运行
Hadoop生态圈-通过CDH5.15.1部署spark1.6与spark2.3.0的版本兼容运行 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在我的CDH5.15.1集群中,默 ...
- Spark2.0.0源码编译
Hive默认使用MapReduce作为执行引擎,即Hive on mr,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark.由于MapRedu ...
- 1.Python3.6环境部署
标题:Python3.6环境部署文档 作者:刘耀 内容 Linux部署Python3.6环境 Mac部署Python3.6环境 Window10部署Python3.6环境 Pycharm安装 1. L ...
- python3.6环境部署文档
python3.6环境部署文档 内容 Linux部署Python3.6环境 Mac部署Python3.6环境 Window10部署Python3.6环境 Pycharm安装 1. Linux部署P ...
- go项目部署到linxu
环境: 在mac上编译, 编译后上传到linux, 然后运行代码 go项目打包 一.直接部署到linux 1. 在mac上, 进入到项目目录, 执行以下命令, 进行编译: CGO_ENABLED=0 ...
- docker4dotnet #1 – 前世今生 & 世界你好
作为一名.NET Developer,这几年看着docker的流行实在是有些眼馋.可惜的是,Docker是基于Linux环境的,眼瞧着那些 java, python, node.js, go 甚至连p ...
- docker4dotnet
docker4dotnet #1 – 前世今生 & 世界你好 作为一名.NET Developer,这几年看着docker的流行实在是有些眼馋.可惜的是,Docker是基于Linux环境的 ...
随机推荐
- 什么情况下适合用UDP协议,什么情况下适合用TCP协议?
总的来说 TCP协议提供可靠的服务, UDP协议提供高效率的服务. 高可靠性的TCP服务提供面向连接的服务,主要用于一次传输大量报文的情形, 如文件传输,远程登录等: 高效率的UDP协议提供无连接的数 ...
- 简单的股票信息查询系统 1 程序启动后,给用户提供查询接口,允许用户重复查股票行情信息(用到循环) 2 允许用户通过模糊查询股票名,比如输入“啤酒”, 就把所有股票名称中包含“啤酒”的信息打印出来 3 允许按股票价格、涨跌幅、换手率这几列来筛选信息, 比如输入“价格>50”则把价格大于50的股票都打印,输入“市盈率<50“,则把市盈率小于50的股票都打印,不用判断等于。
'''需求:1 程序启动后,给用户提供查询接口,允许用户重复查股票行情信息(用到循环)2 允许用户通过模糊查询股票名,比如输入“啤酒”, 就把所有股票名称中包含“啤酒”的信息打印出来3 允许按股票价格 ...
- windows 下apache开启FastCGI
1.首先去(http://www.apachelounge.com/download/)下载一个合适的mod_fcgid 文件. 2.将解压后的文件改为mod_fcgid.dll 并复制到a ...
- SwitchyOmega 配置
1.google 扩展程序里面的chrome 网上应用店里面安装Proxy SwitchyOmega 2.新建情景模式 3.配置代理 4.自动切换添加新建的情景模式,最后保存
- ubuntu ARM 源配置
cat /etc/apt/sources.list deb http://mirrors.aliyun.com/ubuntu-ports/ xenial main deb-src http://mir ...
- On the Convergence of FedAvg on Non-IID Data
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1907.02189v2 [stat.ML] 8 Oct 2019 Abstract 联邦学习使得大量的边缘计算设备在不共享数 ...
- 通过索引优化sql
sql语句的优化最重要的一点就是要合理使用索引,下面介绍一下使用索引的一些原则: 1.最左前缀匹配原则.mysql会一直向右匹配直到遇到范围查询(>.<.between.like)就停止匹 ...
- C言语--冒泡排序
/* 冒泡排序,从小到大 */ include<stdio.h> int main(void) { int i; int t; int p; int val; int a[6]; for( ...
- 架构设计 | 基于电商交易流程,图解TCC事务分段提交
本文源码:GitHub·点这里 || GitEE·点这里 一.场景案例简介 1.场景描述 分布式事务在业务系统中是十分常见的,最经典的场景就是电商架构中的交易业务,如图: 客户端通过请求订单服务,执行 ...
- NOR Flash 与 NAND Flash 的区别
闪速存储器 闪速(Flash)存储器是一种电可擦除可多次编程的存储器.工艺上主要有两类:或非(NOR)型阵列和与非(NAND)型阵列. 项目 读取速度 写入速度 擦除速度 特性 其他 NOR Flas ...