(数据科学学习手札97)掌握pandas中的transform
本文示例文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
开门见山,在pandas中,transform是一类非常实用的方法,通过它我们可以很方便地将某个或某些函数处理过程(非聚合)作用在传入数据的每一列上,从而返回与输入数据形状一致的运算结果。
本文就将带大家掌握pandas中关于transform的一些常用使用方式。
 图1
图1
2 pandas中的transform
在pandas中transform根据作用对象和场景的不同,主要可分为以下几种:
2.1 transform作用于Series
当transform作用于单列Series时较为简单,以前段时间非常流行的企鹅数据集为例:
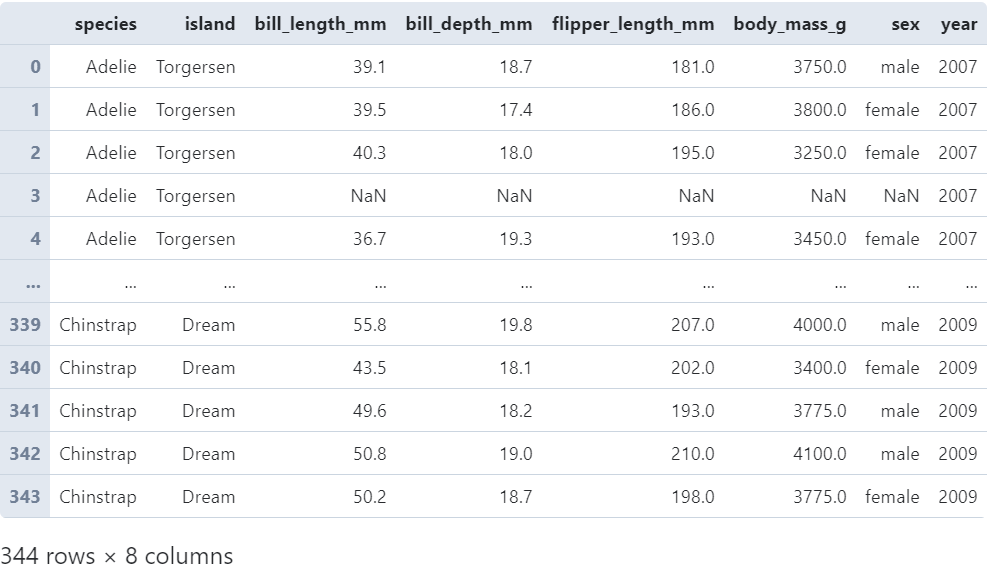 图2
图2
我们在读入数据后,对bill_length_mm列进行transform变换:
- 单个变换函数
我们可以传入任意的非聚合类函数,譬如对数化:
# 对数化
penguins['bill_length_mm'].transform(np.log)
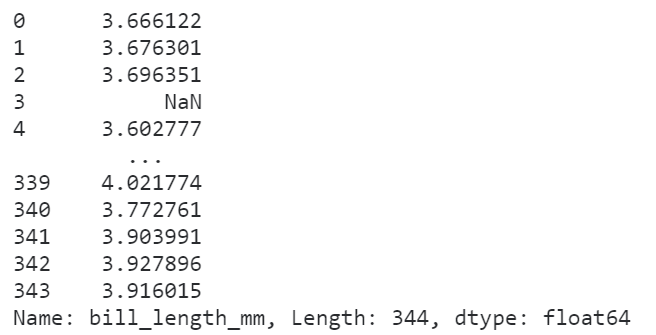 图3
图3
或者传入lambda函数:
# lambda函数
penguins['bill_length_mm'].transform(lambda s: s+1)
 图4
图4
- 多个变换函数
也可以传入包含多个变换函数的列表来一口气计算出多列结果:
penguins['bill_length_mm'].transform([np.log,
lambda s: s+1,
np.sqrt])
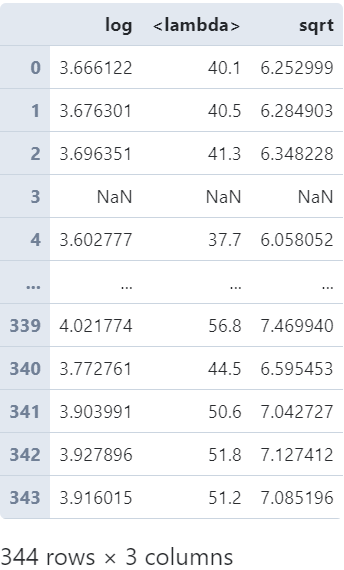 图5
图5
而又因为transform传入的函数,在执行运算时接收的输入参数是对应的整列数据,所以我们可以利用这个特点实现诸如数据标准化、归一化等需要依赖样本整体统计特征的变换过程:
# 利用transform进行数据标准化
penguins['bill_length_mm'].transform(lambda s: (s - s.mean()) / s.std())
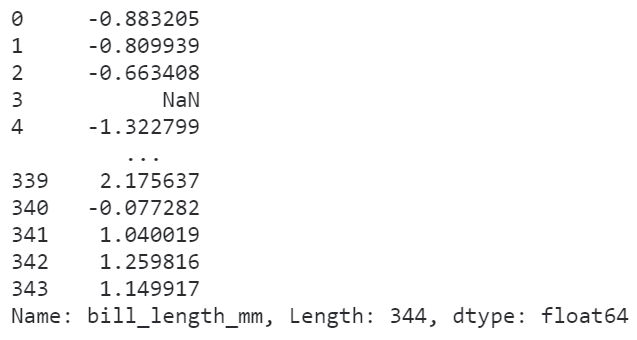 图6
图6
2.2 transform作用于DataFrame
当transform作用于整个DataFrame时,实际上就是将传入的所有变换函数作用到每一列中:
# 分别对每列进行标准化
(
penguins
.loc[:, 'bill_length_mm': 'body_mass_g']
.transform(lambda s: (s - s.mean()) / s.std())
)
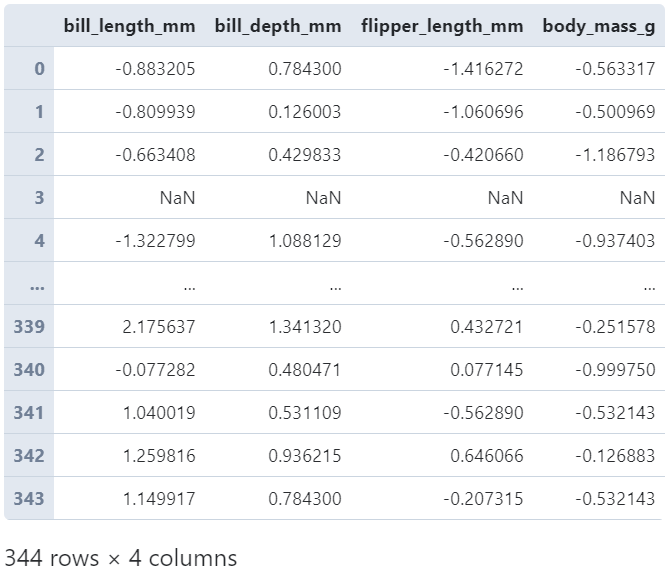 图7
图7
而当传入多个变换函数时,对应的返回结果格式类似agg中的机制,会生成MultiIndex格式的字段名:
(
penguins
.loc[:, 'bill_length_mm': 'body_mass_g']
.transform([np.log, lambda s: s+1])
)
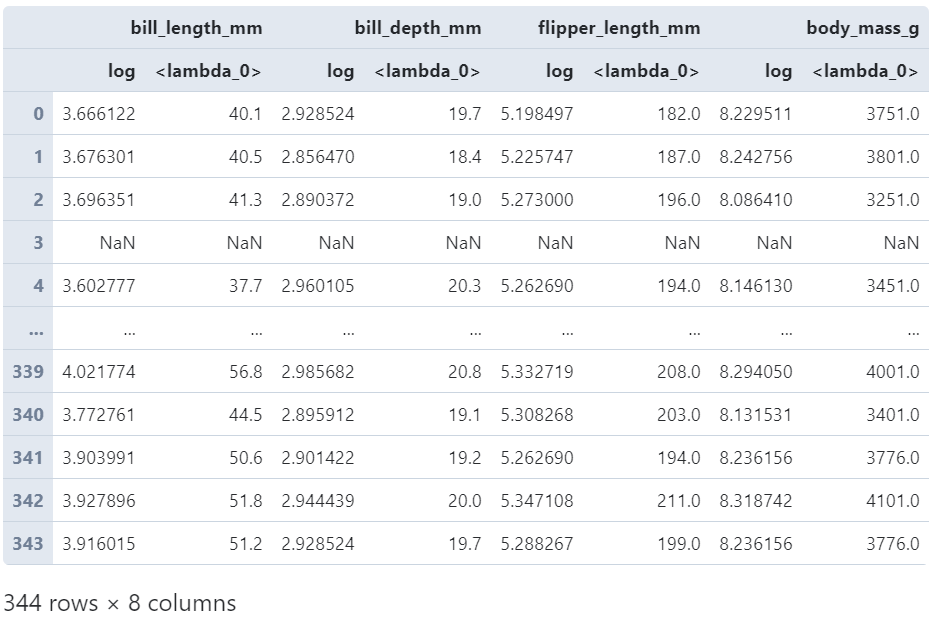 图8
图8
而且由于作用的是DataFrame,还可以利用字典以键值对的形式,一口气为每一列配置单个或多个变换函数:
# 根据字典为不同的列配置不同的变换函数
(
penguins
.loc[:, 'bill_length_mm': 'body_mass_g']
.transform({'bill_length_mm': np.log,
'bill_depth_mm': lambda s: (s - s.mean()) / s.std(),
'flipper_length_mm': np.log,
'body_mass_g': [np.log, np.sqrt]})
)
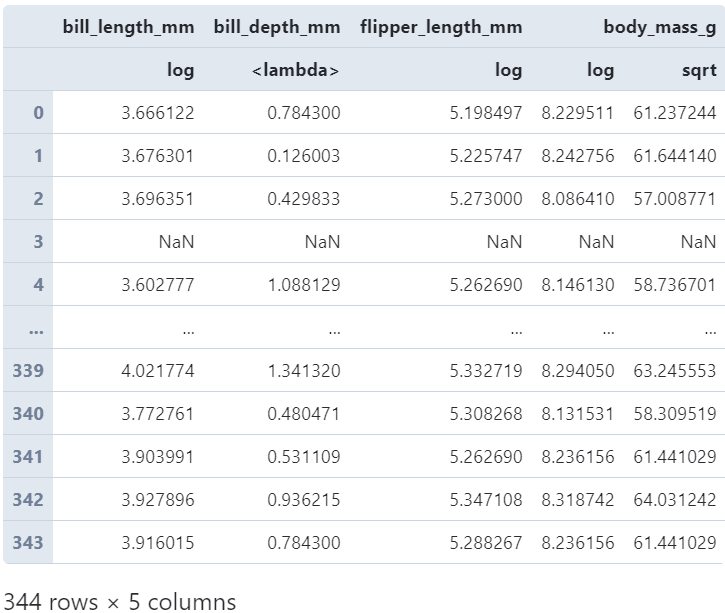 图9
图9
2.3 transform作用于DataFrame的分组过程
在对DataFrame进行分组操作时,配合transform可以完成很多有用的任务,譬如对缺失值进行填充时,根据分组内部的均值进行填充:
# 分组进行缺失值均值填充
(
penguins
.groupby('species')[['bill_length_mm', 'bill_depth_mm',
'flipper_length_mm', 'body_mass_g']]
.transform(lambda s: s.fillna(s.mean().round(2)))
)
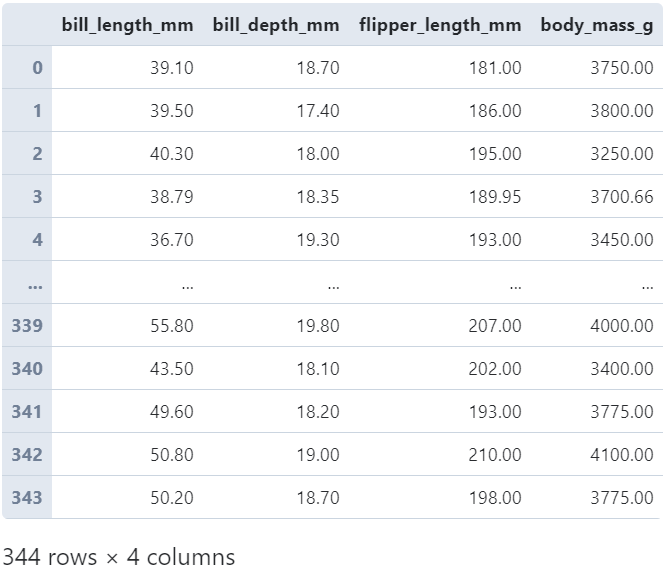 图10
图10
并且在pandas1.1.0版本之后为transform引入了新特性,可以配合Cython或Numba来实现更高性能的数据变换操作,详细的可以阅读( https://github.com/pandas-dev/pandas/pull/32854 )了解更多。
除了以上介绍的内容外,transform还可以配合时间序列类的操作譬如resample等,功能都大差不差,感兴趣的朋友可以自行了解。
以上就是本文的全部内容,欢迎在评论区与我进行讨论
(数据科学学习手札97)掌握pandas中的transform的更多相关文章
- (数据科学学习手札131)pandas中的常用字符串处理方法总结
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在日常开展数据分析的过程中,我们经常需要对 ...
- (数据科学学习手札52)pandas中的ExcelWriter和ExcelFile
一.简介 pandas中的ExcelFile()和ExcelWriter(),是pandas中对excel表格文件进行读写相关操作非常方便快捷的类,尤其是在对含有多个sheet的excel文件进行操控 ...
- (数据科学学习手札68)pandas中的categorical类型及应用
一.简介 categorical是pandas中对应分类变量的一种数据类型,与R中的因子型变量比较相似,例如性别.血型等等用于表征类别的变量都可以用其来表示,本文就将针对categorical的相关内 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札124)pandas 1.3版本主要更新内容一览
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 就在几天前,pandas发布了其1.3版本 ...
- (数据科学学习手札25)sklearn中的特征选择相关功能
一.简介 在现实的机器学习任务中,自变量往往数量众多,且类型可能由连续型(continuou)和离散型(discrete)混杂组成,因此出于节约计算成本.精简模型.增强模型的泛化性能等角度考虑,我们常 ...
- (数据科学学习手札19)R中基本统计分析技巧总结
在获取数据,并且完成数据的清洗之后,首要的事就是对整个数据集进行探索性的研究,这个过程中会利用到各种描述性统计量和推断性统计量来初探变量间和变量内部的基本关系,本篇笔者便基于R,对一些常用的数据探索方 ...
- (数据科学学习手札126)Python中JSON结构数据的高效增删改操作
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一期文章中我们一起学习了在Python ...
随机推荐
- C:算术表达式求值
代码: // fgets2.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <stdio.h> #includ ...
- Life is not the amount of breath you take.
It's the moments that take you breath away.
- Java判断一个字符串是否是回文
package com.spring.test; /** * 判断字符串是否为回文 * * @author liuwenlong * @create 2020-08-31 11:33:04 */ @S ...
- 乔悟空-CTF-i春秋-Web-Not Found-🙋🏻♂️
2020.09.08 又是匆匆忙忙的一天- 做题 题目 题目地址 做题 做题??做个屁,啥也不知道,干瞪眼
- [LeetCode]152. 乘积最大子序列(DP)
题目 给定一个整数数组 nums ,找出一个序列中乘积最大的连续子序列(该序列至少包含一个数). 示例 1: 输入: [2,3,-2,4] 输出: 6 解释: 子数组 [2,3] 有最大乘积 6. 示 ...
- [CF664A]Complicated GCD(数论)
题目链接 http://codeforces.com/problemset/problem/664/A 题意 给两个数,找出它们的最大公因子d,使得从a到b之间的数都可以整除d. 题解 结论: 当gc ...
- [程序员代码面试指南]数组和矩阵-求最短通路值(BFS)
题意 给二维矩阵 1.0组成,问从左上角到右下角的最短通路值. 题解 BFS基础.头节点入队:对队内每个节点判断.处理,符合条件的入队:到了终点节点返回. 相关知识 Queue为接口,LinkedLi ...
- 初等函数——指数函数(Exponential Function)
一般地,函数叫做指数函数,其中x是自变量,函数的定义域是R.
- 剑指offer 59-II 队列的最大值
题目描述 请定义一个队列并实现函数 max_value 得到队列里的最大值,要求函数max_value.push_back 和 pop_front 的均摊时间复杂度都是O(1). 若队列为空,pop_ ...
- VUE开发(一)Spring Boot整合Vue并实现前后端贯穿调用
文章更新时间:2020/03/14 一.前言 作为一个后端程序员,前端知识多少还是要了解一些的,vue能很好的实现前后端分离,且更便于我们日常中的调试,还具备了轻量.低侵入性的特点,所以我觉得是很有必 ...