hdfs学习(一)
一、hdfs概述
介绍:
在现代的企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理分布在
集群上的文件系统称为分布式文件系统 。
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常
适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存
储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统.
应用场景:
适合的应用场景:
- 存储非常大的文件:这里非常大指的是几百M、G、或者TB级别,需要高吞吐量,对延时没有要求。
- 采用流式的数据访问方式: 即一次写入、多次读取,数据集经常从数据源生成或者拷贝一次,然后在其上做很多分析工作 。运行于商业硬件上: Hadoop不需要特别贵的机器,可运行于普通廉价机器,可以处节约成本
- 需要高容错性
- 为数据存储提供所需的扩展能力
不适合的场景:
1) 低延时的数据访问 对延时要求在毫秒级别的应用,不适合采用HDFS。HDFS是为高吞吐数
据传输设计的,因此可能牺牲延时
2)大量小文件 文件的元数据保存在NameNode的内存中, 整个文件系统的文件数量会受限
于NameNode的内存大小。 经验而言,一个文件/目录/文件块一般占有150字节的元数据内存
空间。如果有100万个文件,每个文件占用1个文件块,则需要大约300M的内存。因此十亿级
别的文件数量在现有商用机器上难以支持。
3)多方读写,需要任意的文件修改 HDFS采用追加(append-only)的方式写入数据。不支持
文件任意o?set的修改。不支持多个写入器(writer)
HDFS架构
HDFS是一个 主/从(Mater/Slave)体系结构 ,
HDFS由四部分组成,HDFS Client、NameNod e、DataNode和Secondary NameNode。
1、Client:就是客户端。
文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存
储。
与 NameNode 交互,获取文件的位置信息。
与 DataNode 交互,读取或者写入数据。
Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
2、NameNode:就是 master,它是一个主管、管理者。
管理 HDFS 的名称空间
管理数据块(Block)映射信息
配置副本策略
处理客户端读写请求。
3、DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
存储实际的数据块。
执行数据块的读/写操作。
4、Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不
能马上替换 NameNode 并提供服务。
辅助 NameNode,分担其工作量。
定期合并 fsimage和fsedits,并推送给NameNode。
在紧急情况下,可辅助恢复 NameNode。
NameNode和DataNode
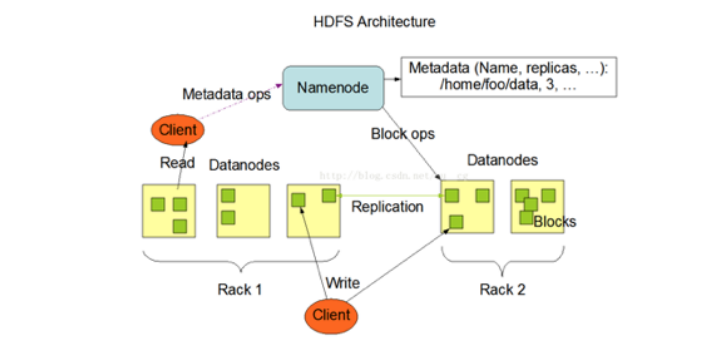
①NameNode在内存中保存着整个文件系统的名称 空间和文件数据块的地址映射
整个HDFS可存储的文件数受限于NameNode的内存大小
1、NameNode元数据信息 文件名,文件目录结构,文件属性(生成时间,副本数,权限)每个
文件的块列表。 以及列表中的块与块所在的DataNode之间的地址映射关系 在内存中加载文件
系统中每个文件和每个数据块的引用关系(文件、block、datanode之间的映射信息) 数据会定
期保存到本地磁盘(fsImage文件和edits文件)
2、NameNode文件操作 NameNode负责文件元数据的操作 DataNode负责处理文件内容的读写
请求,数据流不经过NameNode,会询问它跟那个DataNode联系
3、NameNode副本 文件数据块到底存放到哪些DataNode上,是由NameNode决定的,NN根
据全局情况做出放置副本的决定
4、NameNode心跳机制 全权管理数据块的复制,周期性的接受心跳和块的状态报告信息(包
含该DataNode上所有数据块的列表) 若接受到心跳信息,NameNode认为DataNode工作正
常,如果在10分钟后还接受到不到DN的心跳,那么NameNode认为DataNode已经宕机 ,这时候
NN准备要把DN上的数据块进行重新的复制。 块的状态报告包含了一个DN上所有数据块的列
表,blocks report 每个1小时发送一次.
②DataNode作用
提供真实文件数据的存储服务。
1、Data Node以数据块的形式存储HDFS文件
2、Data Node 响应HDFS 客户端读写请求
3、Data Node 周期性向NameNode汇报心跳信息
4、Data Node 周期性向NameNode汇报数据块信息
5、Data Node 周期性向NameNode汇报缓存数据块信息
二、HDFS命令行使用
①ls
格式: hdfs dfs -ls URI
作用:类似于Linux的ls命令,显示文件列表

②ls -R
格式 : hdfs dfs -ls -R URI
作用 : 在整个目录下递归执行ls, 与UNIX中的ls-R类似

③mkdir
格式 : hdfs dfs [-p] -mkdir <paths>
作用 : 以<paths>中的URI作为参数,创建目录。使用-p参数可以递归创建目录

④put
格式 : hdfs dfs -put <localsrc > ... <dst>
作用 : 将单个的源文件src或者多个源文件srcs从本地文件系统拷贝到目标文件系统中(<dst>对应的路径)。也可以从标准输入中读取输入,写入目标文件系统中
⑤moveFromLocal
格式: hdfs dfs -moveFromLocal <localsrc> <dst>
作用: 和put命令类似,但是源文件localsrc拷贝之后自身被删除。相当于将本地的文件剪切到HDFS里

⑥get
格式 hdfs dfs -get [-ignorecrc ] [-crc] <src> <localdst>
作用:将文件拷贝到本地文件系统。 CRC 校验失败的文件通过-ignorecrc选项拷贝。 文件和CRC
校验和可以通过-CRC选项拷贝

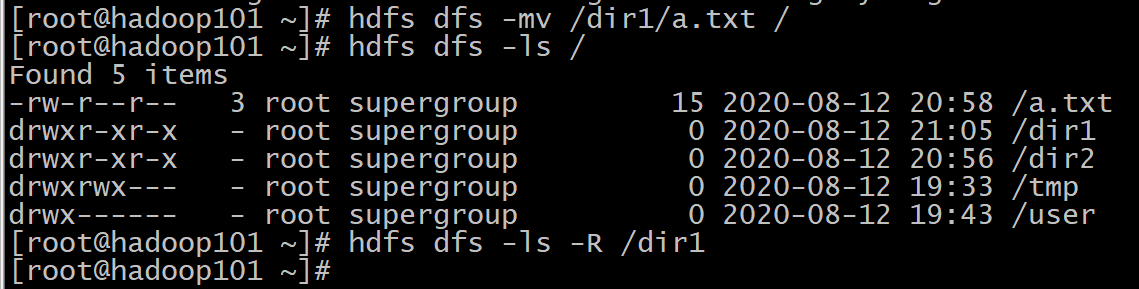
⑦mv
格式 : hdfs dfs -mv URI <dest>
作用: 将hdfs上的文件从原路径移动到目标路径(移动之后文件删除),该命令不能夸文件系统。相当于在HDFS上文件的移动
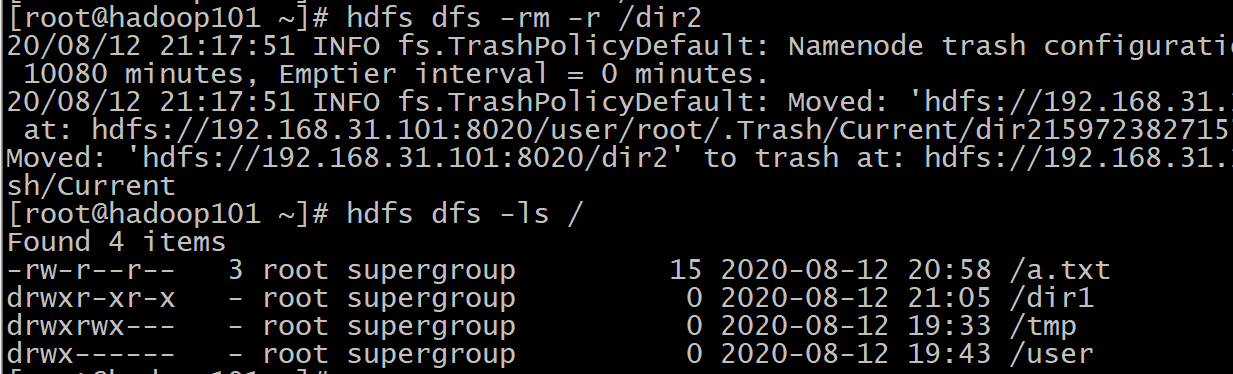
⑧rm
格式: hdfs dfs -rm [-r] 【-skipTrash】 URI 【URI 。。。】
作用: 删除参数指定的文件,参数可以有多个。 此命令只删除文件和非空目录。
如果指定-skipTrash选项,那么在回收站可用的情况下,该选项将跳过回收站而直接删除文件;
否则,在回收站可用时,在HDFS Shell 中执行此命令,会将文件暂时放到回收站中。
⑨cp
格式: hdfs dfs -cp URI [URI ...] <dest>
作用: 将文件拷贝到目标路径中。如果<dest> 为目录的话,可以将多个文件拷贝到该目录
下。
-f
选项将覆盖目标,如果它已经存在。
-p
选项将保留文件属性(时间戳、所有权、许可、ACL、XAttr)。

⑩cat
hdfs dfs -cat URI [uri ...]
作用:将参数所指示的文件内容输出到stdout

11、chmod
格式: hdfs dfs -chmod [-R] URI[URI ...]
作用: 改变文件权限。如果使用 -R 选项,则对整个目录有效递归执行。使用这一命令的用户
必须是文件的所属用户,或者超级用户。

递归修改

12、chown
格式: hdfs dfs -chmod [-R] URI[URI ...]
作用: 改变文件的所属用户和用户组。如果使用 -R 选项,则对整个目录有效递归执行。使用
这一命令的用户必须是文件的所属用户,或者超级用户。

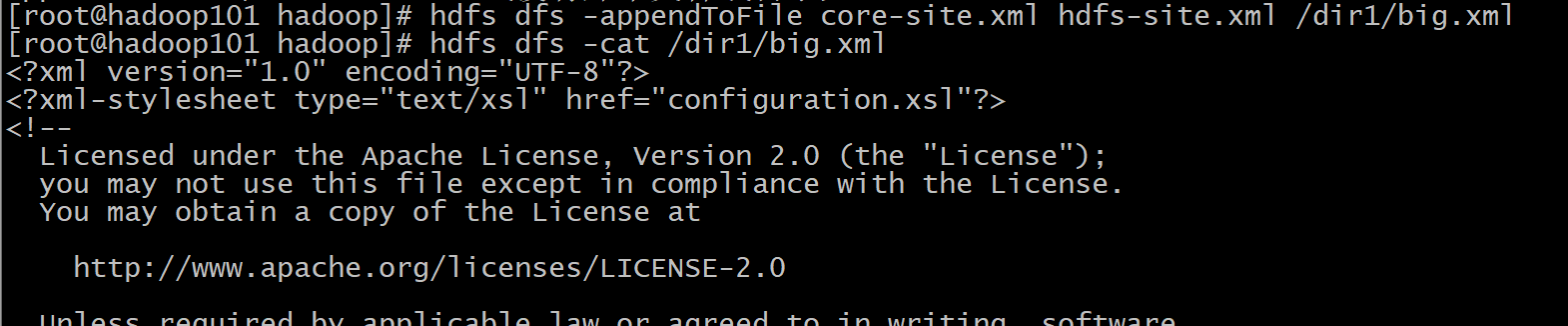
13、appendToFile
格式: hdfs dfs -appendToFile <localsrc> ... <dst>
作用: 追加一个或者多个文件到hdfs指定文件中.也可以从命令行读取输入.
hdfs学习(一)的更多相关文章
- hadoop之HDFS学习笔记(二)
主要内容:hdfs的核心工作原理:namenode元数据管理机制,checkpoint机制:数据上传下载流程 1.hdfs的核心工作原理 1.1.namenode元数据管理要点 1.什么是元数据? h ...
- hadoop之HDFS学习笔记(一)
主要内容:hdfs的整体运行机制,DATANODE存储文件块的观察,hdfs集群的搭建与配置,hdfs命令行客户端常见命令:业务系统中日志生成机制,HDFS的java客户端api基本使用. 1.什么是 ...
- hadoop之hdfs学习
简介 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Go ...
- 二、HDFS学习
Hadoop Distributed File System 简称HDFS 一.HDFS设计目标 1.支持海量的数据,硬件错误是常态,因此需要 ,就是备份 2.一次写多次读 ...
- HDFS学习
HDFS体系结构 HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode)(如图所示).名称节点作为中心服务器, ...
- HDFS学习总结
1.什么是Hadoop 管理网络中跨多台计算机存储的文件系统称为分布式文件系统面临的挑战:使文件系统能容忍节点故障且不丢失任何数据不适合的特点:低时间延迟的数据访问&大量的小文件&多用 ...
- HDFS学习指南
本篇HDFS组件基于CDH5进行安装,安装过程:https://www.cnblogs.com/dmjx/p/10037066.html 角色分布 hdp02.yxdev.wx:HDFS server ...
- HDFS学习笔记(2)hdfs_shell & JavaAPI
FileSystem shell指令 官方文档: HDFS Commands Reference appendToFile cat checksum chgrp chmod chown copyFro ...
- HDFS学习笔记(1)初探HDFS
Hadoop分布式文件系统(Hadoop Distributed File System, HDFS) 分布式文件系统是一种同意文件通过网络在多台主机上分享的文件系统.可让多机器上的多用户分享文件和存 ...
- 大数据之路week07--day01(HDFS学习,Java代码操作HDFS,将HDFS文件内容存入到Mysql)
一.HDFS概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 ...
随机推荐
- Mysql报Too many connections,不要乱用ulimit了,看看如何正确修改进程的最大文件数
背景 今天在学习mysql时,看到一个案例,大体来说,就是客户端报Too many connections.但是,客户端的连接池,限制为了200,两个客户端java进程,那也才400,然后mysql配 ...
- 【Nginx】图片显示过慢,文件下载不完全,竟然是Nginx的锅!!
写在前面 最近,一名读者跟我说他通过浏览器访问自己的服务器时,图片显示的非常慢,以至于在浏览器中都无法完全加载出来,下载文件时,更是恼火,文件根本就无法完全下载下来.而且奇怪的是这位读者所在的网络是没 ...
- 【算法】题目分析:Aggressive Cow (POJ 2456)
题目信息 作者:不详 链接:http://poj.org/problem?id=2456 来源:PKU JudgeOnline Aggressive cows[1] Time Limit: 1000M ...
- Python爆火的原因与未来|内附Python学习书籍大礼包无偿领取|
从12年到20年,python以肉眼可见的趋势超过了java,成为了当今It界人人皆知的编程语言. python为什么这么火? 网络编程语言搜索指数 适合初学者 Python具有语法简单.语句清晰的特 ...
- logging日志基础示例
import logging logger = logging.getLogger() # 获取日志对象 logfile = 'test.log' hdlr = logging.FileHandler ...
- PHP 中的字符串变量
PHP 字符串变量 字符串变量用于存储并处理文本. PHP 中的字符串变量 字符串变量用于包含有字符的值. 在创建字符串之后,我们就可以对它进行操作了.您可以直接在函数中使用字符串,或者把它存储在变量 ...
- Python os.removedirs() 方法
概述 os.removedirs() 方法用于递归删除目录.像rmdir(), 如果子文件夹成功删除, removedirs()才尝试它们的父文件夹,直到抛出一个error(它基本上被忽略,因为它一般 ...
- PHP each() 函数
实例 返回当前元素的键名和键值,并将内部指针向后移动: <?php $people = array("Peter", "Joe", "Glenn ...
- linux集群服务网络状态(netstat),服务端页面(图形字符页面)基本配置
Linux网络基础配置 yum -y install vim 安装vim 关闭的防火墙服务 iptables -F iptables -X iptables -Z systemctl s ...
- 开源后端数据校验插件Validate.Net,类似Validate.js
介绍 Validate.Net将Validate.js移植到.Net平台,可以更方便.更快捷的校验实体内属性值是否合法.内置多种常规数据校验规则(校验必填.校验字符串长度区间.校验最大最小值.校验值区 ...