Analytics Zoo Cluster Serving自动扩展分布式推理
作者: Jiaming Song, Dongjie Shi, Gong, Qiyuan, Lei Xia, Wei Du, Jason Dai
随着深度学习项目从实验到生产的发展,越来越多的应用需要对深度学习模型进行大规模和实时的分布式推理服务。虽然已经有一些工具可用于相关任务(如模型优化、服务、集群调度、工作流管理等等),但对于许多深度学习的工程师和科学家来说,开发和部署能够透明地扩展到大型集群的分布式推理工作流仍然是一个具有挑战性的过程。

为了应对这一挑战,我们在Analytics Zoo 0.7.0版本中发布了Cluster Serving的支持。Analytics Zoo Cluster Serving是一个轻量级、分布式、实时的模型服务解决方案,支持多种深度学习模型(例如TensorFlow*、PyTorch*、Caffe*、BigDL和OpenVINO™的模型)。它提供了一个简单的pub/sub API(发布/订阅),用户可以轻松地将他们的推理请求发送到输入队列(使用一个简单的Python API)。然后,Cluster Serving将使用分布式流框架(如Apache Spark* Streaming、Apache Flink*等等)在大型集群中进行实时模型推理和自动扩展规模。Analytics Zoo Cluster Serving的总体架构如图1所示。
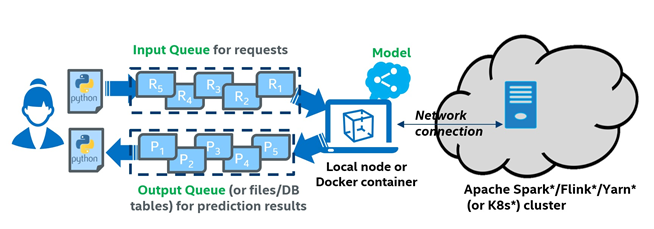
图1 Analytics Zoo Cluster Serving 解决方案总体框架
Cluster Serving的工作原理
你可以按照下面的三个简单步骤使用Cluster Serving解决方案(如图2所示)。
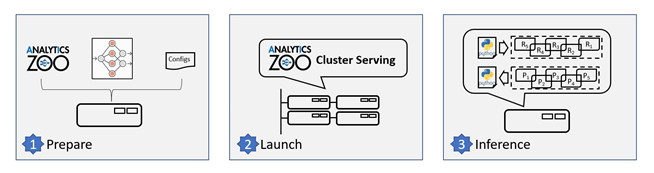
图2 使用Analytics Zoo Cluster Serving解决方案的步骤
1、 在本地节点安装和准备Cluster Serving环境
- 将已经完成训练的模型复制到本地节点。当前支持的模型包括TensorFlow、PyTorch、Caffe、BigDL和OpenVINO的模型。
- 在本地节点上安装Analytics Zoo(例如使用单个pip Install命令即可完成)
- 在本地节点上配置集群服务器,包括模型的文件路径和集群地址(如Apache Hadoop*YARN集群、Spark集群、Kubernetes*集群等)
请注意这一点,Cluster Serving解决方案只需要部署在本地节点上,集群(YARN或者Kubernetes)并不需要做任何改动。
2、 启动Cluster Serving服务
通过在本地节点上运行startup script脚本启动Cluster Serving服务,例如:
start-cluster-serving.sh
在后台,Cluster Serving将自动部署训练好的模型,并以分布式的方式跨集群服务于模型推理请求。您可以使用TensorBoard*监测其运行时状态(例如推理吞吐量)。
3、 分布式实时(流式)推理
Cluster Serving提供了一个简单的pub/sub API(发布/订阅),你可以使用这个简单的Python API将推理请求轻松地发送到输入队列(当前使用的是Redis* Streams),例如:
input = InputQueue()
input.enqueue_image(id, image)
然后,Cluster Serving将从Redis* Streams读取请求,使用Spark Streaming或Flink跨集群运行分布式实时推理,并通过Redis返回结果。最后,您可以再次使用这个简单的Python API获得推理结果,例如:
output = OutputQueue()
results = output.dequeue()
快速入门示例
你也可以通过运行Analytics Zoo 0.7.0版本中提供的快速入门示例来尝试使用Cluster Serving。快速入门示例包含了使用Cluster Serving运行分布式推理流程所需的所有组件,首次使用它的用户能够在几分钟内启动并运行。快速入门示例包含:
- 一个Analytics Zoo Cluster Serving的Docker Image (已安装所有依赖)
- 一个示例配置文件
- 一个训练好的TensorFlow模型,以及推理样本数据
- 一个示例Python客户端程序
按照下面的步骤运行快速入门示例。有关详细说明,请参阅Analytics Zoo Cluster Serving编程指南。
1、 启动 Analytics Zoo docker
#docker run -itd --name cluster-serving --net=host intelanalytics/zoo-cluster-serving:0.7. bash
2、 登录container并转到我们准备好的工作目录
#docker exec -it cluster-serving bash
#cd cluster-serving
3、 在container内启动Cluster Serving
#cluster-serving-start
4、 运行Python客户端程序,开始推理
#python quick_start.py
以下推理结果应该出现在你本地终端显示上:
image: fish1.jpeg, classification-result: class: 's prob: 0.9974158
image: cat1.jpeg, classification-result: class: 287's prob: 0.52377725
image: dog1.jpeg, classification-result: class: 's prob: 0.9226527
如果你希望构建和部署定制的Cluster Serving流程,可以从修改快速入门示例中提供的示例配置文件和示例Python程序开始。下面是这些文件的大致结构,仅供参考。有关更多详细信息,请参阅 Cluster Serving编程指南。
配置文件(config.yaml)如下所示:
## Analytics Zoo Cluster Serving Config Example
model:
# model path must be set
path: /opt/work/model
data:
# default, localhost:
src:
# default, ,,
image_shape:
params:
# default,
batch_size:
# default,
top_n:
spark:
# default, local[*], change this to spark://, yarn, k8s:// etc if you want to run on cluster
master: local[*]
# default, 4g
driver_memory:
# default, 1g
executor_memory:
# default,
num_executors:
# default,
executor_cores:
# default,
total_executor_cores:
Python程序(quick_start.py)如下所示:
from zoo.serving.client import InputQueue, OutputQueue
import os
import cv2
import json
import time if __name__ == "__main__":
input_api = InputQueue()
base_path = "../../test/zoo/resources/serving_quick_start"
if not base_path:
raise EOFError("You have to set your image path")
output_api = OutputQueue()
output_api.dequeue()
path = os.listdir(base_path)
for p in path:
if not p.endswith("jpeg"):
continue
img = cv2.imread(os.path.join(base_path, p))
img = cv2.resize(img, (224, 224))
input_api.enqueue_image(p, img)
time.sleep(5)
# get all results and dequeue
result = output_api.dequeue()
for k in result.keys():
output = "image: " + k + ", classification-result:"
tmp_dict = json.loads(result[k])
for class_idx in tmp_dict.keys():
output += "class: " + class_idx + "'s prob: " + tmp_dict[class_idx]
print(output)
结论
我们很高兴与您分享Analytics Zoo 0.7.0版本中提供的这种新的群集模型服务支持,并希望此解决方案有助于简化您的分布式推理工作流并提高您的工作效率。我们很乐意在GitHub和邮件列表上听到您的问题和反馈。我们将持续对Analytics Zoo进行开发工作,构建统一数据分析和人工智能平台,敬请期待更多关于Analytics Zoo的信息。
Analytics Zoo Cluster Serving自动扩展分布式推理的更多相关文章
- 基于Spark自动扩展scikit-learn (spark-sklearn)(转载)
转载自:https://blog.csdn.net/sunbow0/article/details/50848719 1.基于Spark自动扩展scikit-learn(spark-sklearn)1 ...
- OpenStack 企业私有云的若干需求(2):自动扩展(Auto-scaling) 支持
本系列会介绍OpenStack 企业私有云的几个需求: 自动扩展(Auto-scaling)支持 多租户和租户隔离 (multi-tenancy and tenancy isolation) 混合云( ...
- 在ScrollView下加入的组件,不能自动扩展到屏幕高度
ScrollView中的组件设置android:layout_height="fill_parent"不起作用的解决办法 在ScrollView中添加一个android:fillV ...
- 采用Asp.Net的Forms身份验证时,持久Cookie的过期时间会自动扩展
原文:http://www.cnblogs.com/sanshi/archive/2012/06/22/2558476.html 若是持久Cookie,Cookie的有效期Expiration属性有当 ...
- 采用Asp.Net的Forms身份验证时,非持久Cookie的过期时间会自动扩展
问题描述 之前没有使用Forms身份验证时,如果在登陆过程中把HttpOnly的Cookie过期时间设为半个小时,总会收到很多用户的抱怨,说登陆一会就过期了. 所以总是会把Cookie过期时间设的长一 ...
- ORA-01653:表空间扩展失败的问题(开启表空间自动扩展)
----查询表空间使用情况---使用DBA权限登陆SELECT UPPER(F.TABLESPACE_NAME) "表空间名",D.TOT_GROOTTE_MB "表空间 ...
- 深入理解Azure自动扩展集VMSS(3)
在实际使用过程当中,使用VMSS有一些最佳实践的建议和限制,便于你在做自动扩展设计的时候进行考虑: 关于VMSS 如果你使用的是系统镜像,一个扩展集中虚拟机数量不能超过100 无论是在ASM还是ARM ...
- 深入理解Azure自动扩展集VMSS(2)
VMSS中Auto Scale基本原理及诊断 在前面的介绍中,我们看到通过定义规则可以实现虚拟机扩展集的auto scale,那么在后台执行上VMSS的扩展依赖于哪些组件,出现问题(比如自动扩展没有发 ...
- 深入理解Azure自动扩展集VMSS(1)
前文中已经详细介绍了如何配置和部署Azure的虚拟机扩展集VMSS进行自动扩展,但在实际使用过程当中,用户会出现更进一步使用的一些问题,VMSS基本扩展原理及怎么简单调试?如何进行手动扩展?怎么使用自 ...
随机推荐
- jqgrid 自定义文本框、选择框等查询
要实现jqgrid的自定义查询可通过表格获取查询的条件,再给jqgrid表格发送postData参数. HTML: <table id="querytable" border ...
- 从零搭建Spring Boot脚手架(6):整合Redis作为缓存
1. 前言 上一文我们整合了Mybatis Plus,今天我们会把缓存也集成进来.缓存是一个系统应用必备的一种功能,除了在减轻数据库的压力之外.还在存储一些短时效的数据场景中发挥着重大作用,比如存储用 ...
- 关于haar特征的理解及使用(java实现)
Haar特征原理综述Haar特征是一种反映图像的灰度变化的,像素分模块求差值的一种特征.它分为三类:边缘特征.线性特征.中心特征和对角线特征.如下所示: Haar-like矩形特征拓展 Lienha ...
- Java之NIO与IO比较分析
Java NIO(New Input/Output)——新的输入/输出API包——是2002年引入到J2SE 1.4里的.Java NIO的目标是提高Java平台上的I/O密集型任务的性能. 简单描述 ...
- Jmeter(二十二) - 从入门到精通 - JMeter断言 - 下篇(详解教程)
1.简介 断言组件用来对服务器的响应数据做验证,常用的断言是响应断言,其支持正则表达式.虽然我们的通过响应断言能够完成绝大多数的结果验证工作,但是JMeter还是为我们提供了适合多个场景的断言元件,辅 ...
- RSA加密算法和SSH远程连接服务器
服务器端与客户端的密钥系统不一样,称为非对称式密钥系统 RSA算法的基础是模运算x mod n,事实上: [(a mod n) + (b mod n)] mod n = (a+b) mod n [(a ...
- 理解传输层中UDP协议首部校验和以及校验和计算方法的Java实现
UDP,全称User Datagram Protocol,用户数据报协议,是TCP/IP四层参考模型中传输层的一种面向报文的.无连接的.不能保证可靠的.无拥塞控制的协议.UDP协议因为传输效率高,常用 ...
- asyncio系列之Lock实现
import types import select import time import socket import functools import collections class Futur ...
- 渲染更换头像 文件转成url地址
需求:在一个后台页面中,插入iform页面,需求为更换头像(layui框架) 一.前提:创建user_buddha.html 页面 在侧边栏对应的 a 标签设置 ...
- 工作不到一年,做出了100k系统,老板给我升职加薪
看了下自己上一次发技术文还是在6月15日,算了算也是两个来月了.别怕,短暂的离开,是为了更好的相遇. 来到新公司以后啊,发现公司的搜索业务是真的太多了,大大小小有几百个搜索业务.来了之后得先梳理.熟悉 ...