MySQL之高级操作
新增数据:
基本语法:
insert into 表名 [(字段列表)] values(列表值)
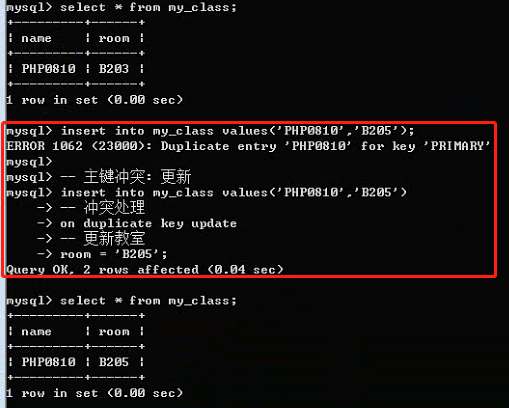
在数据插入的时候,假设主键对应的值已经存在,插入一定会失败
主键冲突:
当主键存在冲突的时候(Duplicate key),可以选择性的进行处理:更新和替换
主键冲突:更新操作
Insert into 表名 [(字段列表:包含主键)] values(值列表) on duplicate key update 字段 = 新值;
主键冲突:替换
Replace into 表名 [(字段列表:包含主键)] values(值列表);

蠕虫复制:
从已有的数据中去获取数据,然后将数据又进行新增操作:数据成倍的增加。
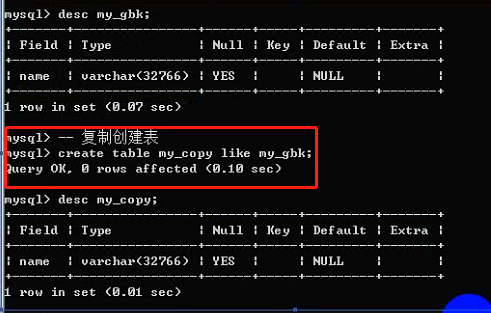
表创建高级操作:从已有表创建新表(复制表结构)。
Create table 表名 like 数据库.表名;
只复制结构:
蠕虫复制:先查询出数据,然后将查出的数据新增一遍
Insert into 表名 [(字段列表)] select 字段列表/* from 数据表名;
蠕虫复制的意义:
1、从已有表拷贝数据到新表中。
2、可以迅速的让表中的数据膨胀到一定的数量级:测试表的压力以及效率。
更新数据:
基本语法:
Update 表名 set 字段 = 值 [where 条件];
高级新增语法:
Update 表名 set 字段 = 值 [where 条件] [limit 更新数据];

删除数据:
DELETE语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行进行回滚操作。
TRUNCATE TABLE 则一次性地从表中删除所有的数据并不把单独的删除操作记录记入日志保存,删除行是不能恢复的。并且在删除的过程中不会激活与表有关的删除触发器。执行速度快。
与更新数据相似,可以通过limit来限制数量
Delete from 表名 [where 条件] [limit 数量];

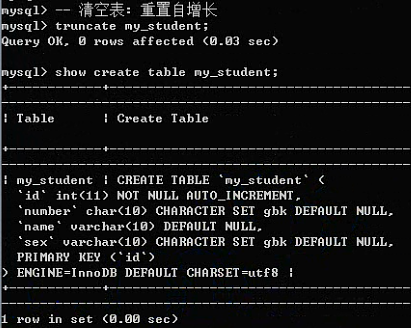
注意:如果表中存在主键自增长,那么当删除之后,自增长不会还原。
Truncate 表名;
查询数据:
基本语法:
Select 字段列表/*from 表名 [where 条件];
完整语法:

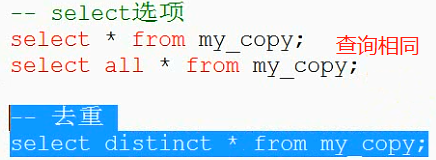
select选项:
select对查出来的结果的处理方式:
All:默认的,保留所有的查询结果;
Distinct:去重,查出来的结果,将重复给去除(所有字段都相同);
字段别名:
当数据进行查询出来的时候,有时候名字并不一定满足需求(多表查询的时候,会有同名字段)。需要对字段名进行重新命名:称为别名。
语法:
select 字段名 [as] 别名;

数据源:
数据的来源,关系型数据库的来源都是数据表,本质上只要保证数据类似二维表,最终都可以作为数据源。
数据源分为多种:单表数据源、多表数据源、查询语句。
单表数据源:select * from 表名;
多表数据源:select * from 表名1,表名2,表名3……;
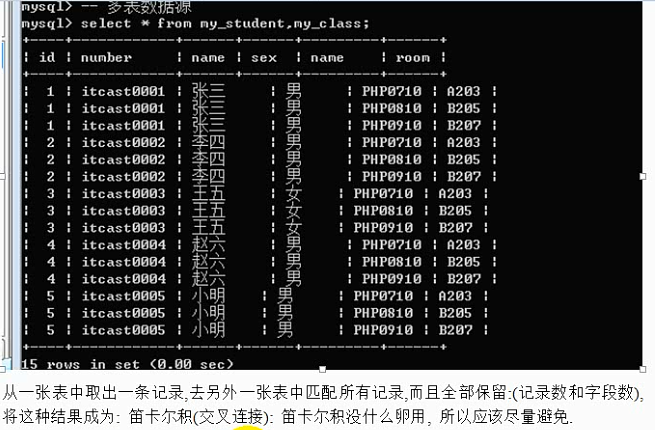
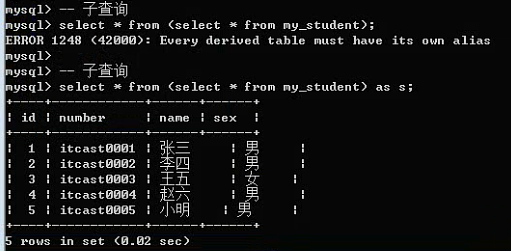
子查询:数据的来源是一条查询语句(查询语句的结果是二维表);
基本语法:
select * from (select 语句) as 表名;
Where子句:


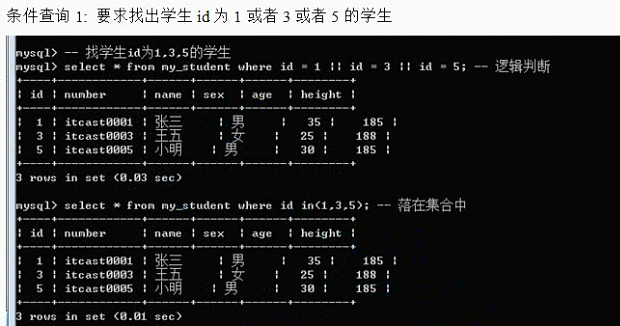
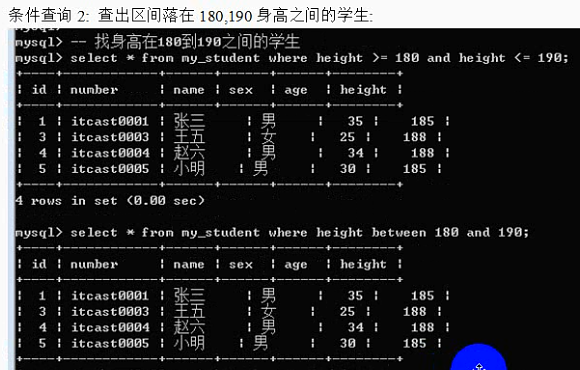
Between本身是闭区间;between左边的值必须小于或者等于右边的值;

where 1 = 1;
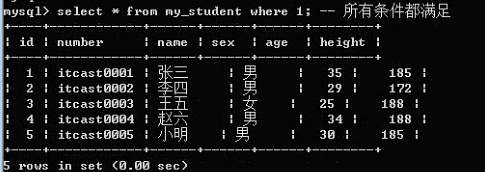
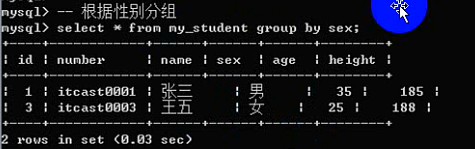
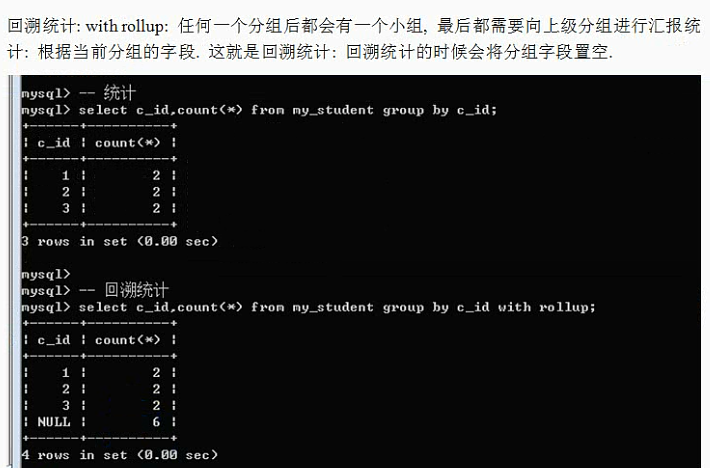
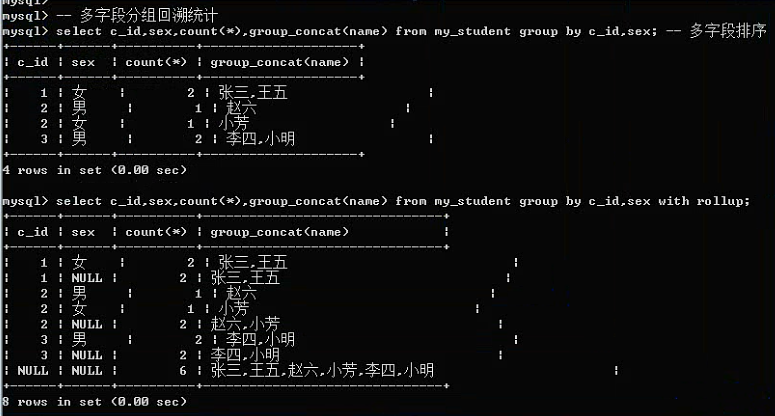
Group by 子句:
分组的意思,根据某个字段进行分组(相同的放一组,不同的分到不同的组)
基本语法:group by 字段名
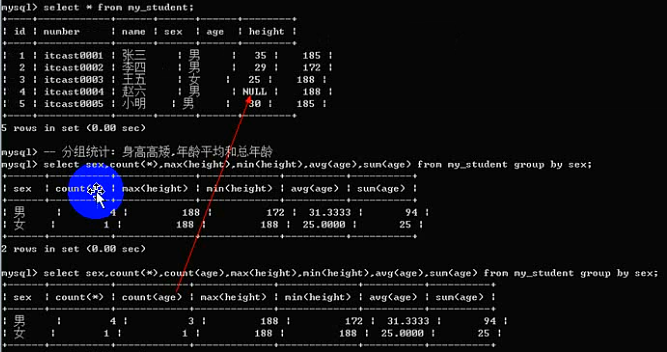
为什么要分组:是为了统计数据(按组统计:按分组字段进行数据统计)
SQL提供了一系列统计函数:


注意:count函数:里面可以使用两种参数:* 代表统计记录;字段名代表统计对应的字段(NULL不统计)


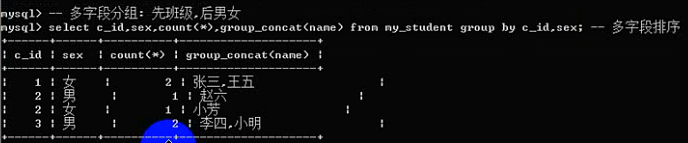
注意:有一个函数可以对分组的结果中的某个字段进行字符串连接(保留该组所有的某个字段):
group_concat(字段);
了解:

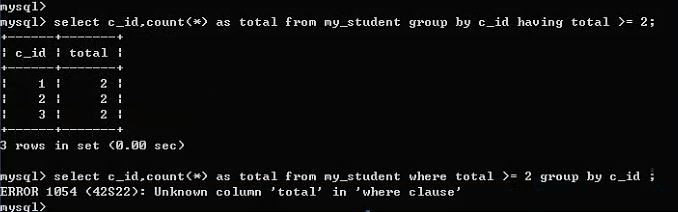
Having子句:
与where子句一样,进行条件判断。
区别:where是针对磁盘数据进行判断,进入到内存之后,会进行分组操作:分组结果就需要having来处理。
Having能做where能做的几乎所有的事情,但是where却不能做Having能做的很多事情。
1、分组统计的结果或者说统计函数都只有having能够使用。

2、Having能够使用字段别名,where不能。where是从磁盘去数据,而名字只能是字段名,别名是在字段名进入内存后才会产生的。
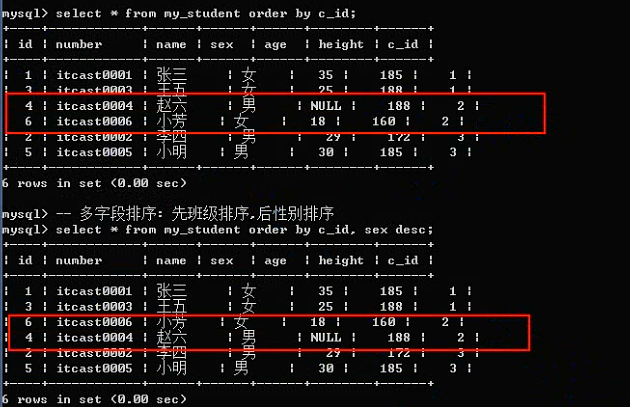
Order by 子句:
Order by:排序,根据某个字段进行升序或者降序排序,依赖校对集。
使用语法:
Order by 字段名 [asc|desc]; --asc是升序(默认的),desc是降序。
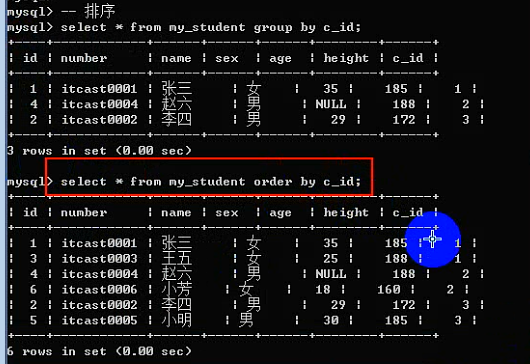
排序可以进行多字段排序:先根据某个字段进行排序,然后排序好的内部,再按照某个数据进行再次排序。
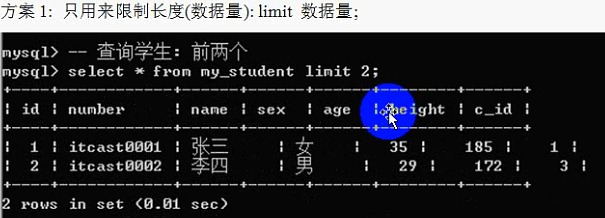
Limit子句:
Limit子句是一种限制结果的语句:限制数量。
Limit有两种使用方式:
方案2:限制起始位置,限制数量:limit起始位置、长度。
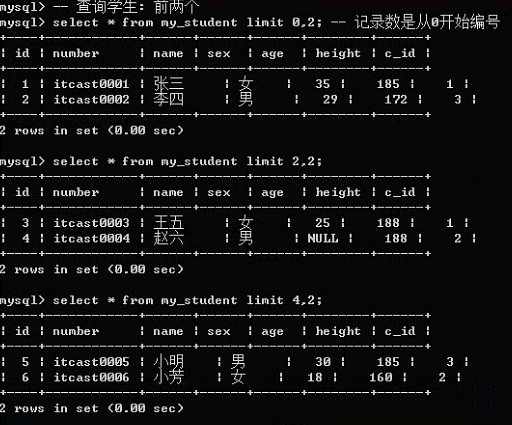
Limit方案2主要是用来实现数据分页,为用户节省时间,提高服务器相应率,减少资源浪费。
对于用户来讲:可以点击分页按钮。
对于服务器来讲:根据用户选择的页数来获取不同的数据:limit offset length;
length:每页显示的数据量,基本不变;
offset:offset = (页码 - 1)* 每页显示量。
MySQL之高级操作的更多相关文章
- MySQL 数据库高级操作 (配图)
MySQL数据库高级操作 1.一键部署mysql 数据库 2.数据表高级操作 3.数据库用户管理 4.数据库用户授权 1.首先一键部署mysql 数据库 : 可以看我之前的博客 https://www ...
- MySQL学习笔记_9_MySQL高级操作(上)
MySQL高级操作(上) 一.MySQL表复制 create table t2 like t1; #复制表结构,t2可以学习到t1所有的表结构 insert into t2 ...
- MySQL学习笔记_10_MySQL高级操作(下)
MySQL高级操作(下) 五.MySQL预处理语句 1.设置预处理stmt,传递一个数据作为where的判断条件 prepare stmt from "select * from table ...
- MySQL<数据库的高级操作>
数据库的高级操作 MySQL提供了一个mysqldump命令,它可以实现数据的备份 数据的备份 1.备份单个数据库 mysqldump -uusername -ppassword dbname [tb ...
- python数据库-MySQL数据库高级查询操作(51)
一.什么是关系? 1.分析:有这么一组数据关于学生的数据 学号.姓名.年龄.住址.成绩.学科.学科(语文.数学.英语) 我们应该怎么去设计储存这些数据呢? 2.先考虑第一范式:列不可在拆分原则 这里面 ...
- Mysql高级操作学习笔记:索引结构、树的区别、索引优缺点、创建索引原则(我们对哪种数据创建索引)、索引分类、Sql性能分析、索引使用、索引失效、索引设计原则
Mysql高级操作 索引概述: 索引是高效获取数据的数据结构 索引结构: B+Tree() Hash(不支持范围查询,精准匹配效率极高) 树的区别: 二叉树:可能产生不平衡,顺序数据可能会出现链表结构 ...
- cassandra高级操作之索引、排序以及分页
本次就给大家讲讲cassandra的高级操作:索引.排序和分页:处于性能的考虑,cassandra对这些支持都比较简单,所以我们不能希望cassandra完全适用于我们的逻辑,而是应该将我们的逻辑设计 ...
- SpringMVC整合Mongodb开发,高级操作
开发环境: 操作系统:windows xpMongodb:2.0.6依 赖 包:Spring3.2.2 + spring-data-mongodb-1.3.0 + Spring-data-1.5 + ...
- 数据库 MySQL 之 表操作、存储引擎
数据库 MySQL 之 表操作.存储引擎 浏览目录 创建(复制) 删除 修改 查询 存储引擎介绍 一.创建(复制) 1.语法: 1 2 3 4 5 CREATE TABLE 表名( 字段名1 ...
随机推荐
- laravel Excel 导入
<?php namespace App\Modules\Live\Http\Controllers; use Illuminate\Http\Request; use Maatwebsite\E ...
- Redis系列(六):数据结构List双向链表LPUSH、LPOP、RPUSH、RPOP、LLEN命令
1.介绍 redis中的list既实现了栈(先进后出)又实现了队列(先进先出) 1.示意图 2.各命令详解 LPUSH/RPUSH LPUSH: 从队列的左边入队一个或多个元素 将所有指定的值插入到存 ...
- day12—列表、元组、字典基本语法
一.list类中提供的方法 **********************灰魔法************************** 1. 原来值最后追加 append() li = [11, 22, ...
- dart快速入门教程 (7.3)
7.4.抽离类为单独文件 新建一个文件,单独存放一个类,例如:Person类抽离到person.dart文件中 class Person { final String name; final num ...
- eclipse 导入下载或拷贝的java Web项目时报错 ,或者是报错Unbound classpath container: 'JRE System Library
在Problems里报错Description Resource Path Location Type Unbound classpath container: 'JRE System Library ...
- Buy a Ticket 【最短路】
题目 Musicians of a popular band "Flayer" have announced that they are going to "make t ...
- C# @string $string $@string
@string 保证换行后也属于同一个字符串 (请特别注意\r\n这样也会直接输入,不在起到换行的效果) string execSql = @" SELECT T1.ProcInstID ...
- 2020年全新web前端学习路线图,学完就业20K!
第一阶段:HTML5+css 配套学习视频: 前端小白零基础入门HTML5+CSS3 第二阶段:移动web网页开发 移动web进阶教程 第三阶段:JavaScript网页编程 前端与移动开发基础入门到 ...
- JVM学习篇-第一篇
JVM学习篇-第一篇 JDK( Java Development Kit): Java程序设计语言.Java虚拟机.Java类库三部分统称为JDK,JDK是用于支持Java程序开发的最小环境** ...
- VMware实现宿主机和虚拟机处于同一网段
打开虚拟网络编辑器 选择VMnet0桥接模式,在VMnet信息中,选择可以选择的网卡,然后保存. 打开虚拟机设置,在“硬件”选项卡的网络适配器中选择桥接模式即可.