Hbase系统架构简述
由于最近要开始深入的学习一下hbase,所以,先大概了解了hbase的基本架构,在此简单的记录一下。
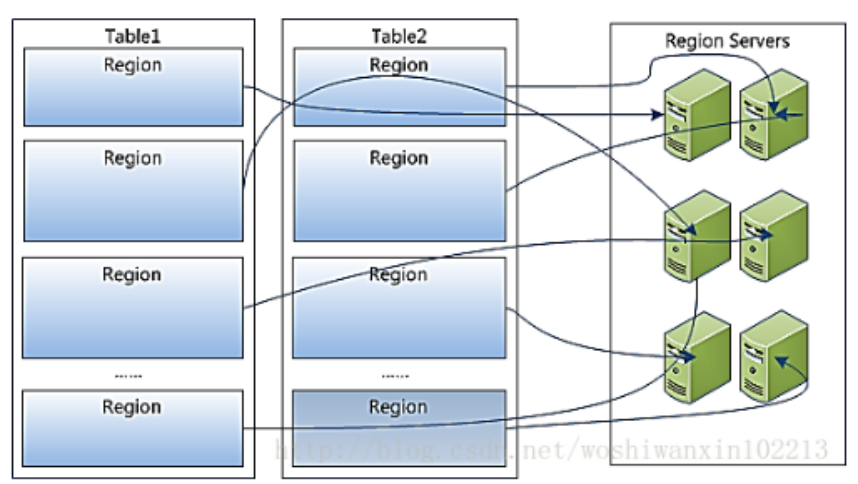
Hbase的逻辑视图

Hbase的物理存储
HRegion
- Table中所有行都按照row key的字典序排列。
- Table在行的方向上分割为多个HRegion。
- HRegion按大小分割的,每个表开始只有一个HRegion,随着数据增多,HRegion不断增大,当增大到一个阀值的时候,HRegion就会等分会两个新的HRegion,之后会有越来越多的Region。
- HRegion是Hbase中分布式存储和负载均衡的最小单元,不同HRegion分布到不同HRegionServer上。
Store
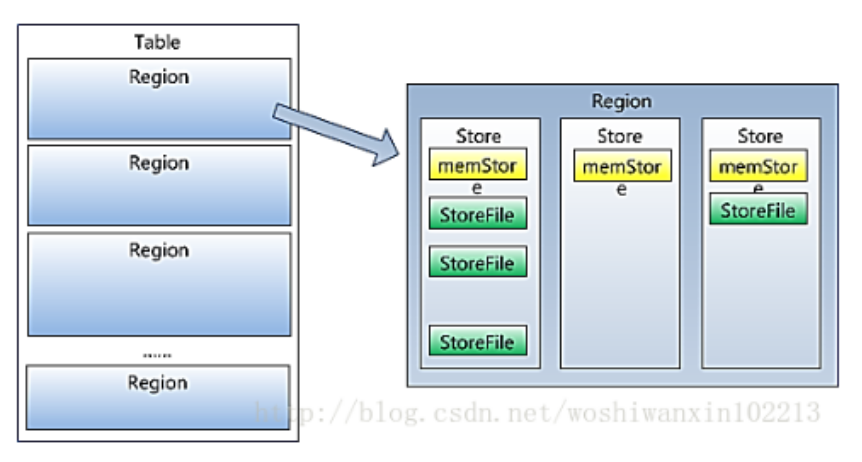
- HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元。
- HRegion由一个或者多个Store组成,每个Store保存一个columns family。 所以,每个column family存储在HDFS上的一个单独文件中,空值不会被保存。
- 每个HRtrore又由一个MemStore和0至多个StoreFile组成,StoreFile包含HFile。
- MemStore存储在内存中,StoreFile存储在HDFS上。
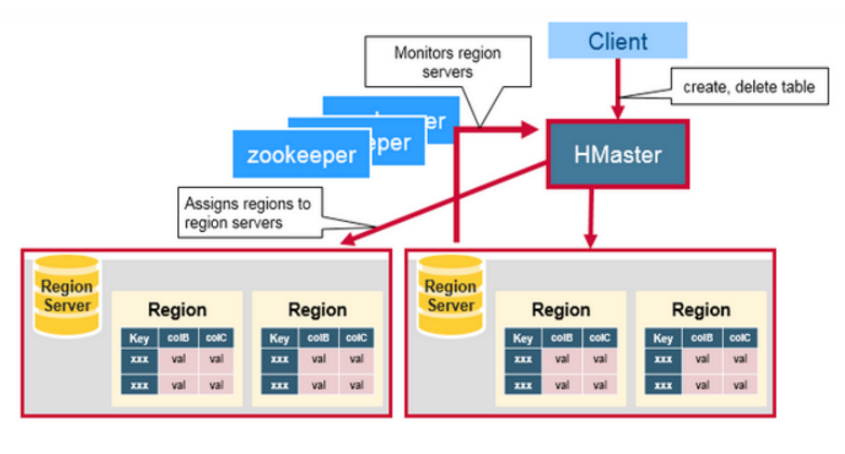
Hbase基本组件
Client
- 包含访问HBase的接口,并维护cache来加快对HBase的访问,比如HRegion的位置信息。
Master
- 为HRegionServer分配HRegion:比如在HRegion split时分配新的HRegion;在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上
- 负责HRegionServer的负载均衡
- 发现失效的HRegionServer并重新分配其上的HRegion
- 管理用户对table的增删改查操作
- 管理namespace和table的元数据
- 权限控制(ACL)
HRegionServer
- HRegionServer维护HRegion,处理对这些HRegion的IO请求
- 存放和管理本地Hregion
- 读写HDFS,管理Table中的数据 HRegionserver负责切分在运行过程中变得过大的Hregion
- Client直接通过HRegionServer读写数据(从HMaster中获取元数据,找到RowKey所在的HRegion/HRegionServer后)
Zookeeper
- 通过选举,保证任何时候,集群中只有一个master,Master与RegionServers 启动时会向ZooKeeper注册
- 存贮所有Region的寻址入口
- 实时监控Region server的上线和下线信息。并实时通知给Master
- 存储HBase的schema和table元数据
Zookeeper的引入使得Master不再是单点故障

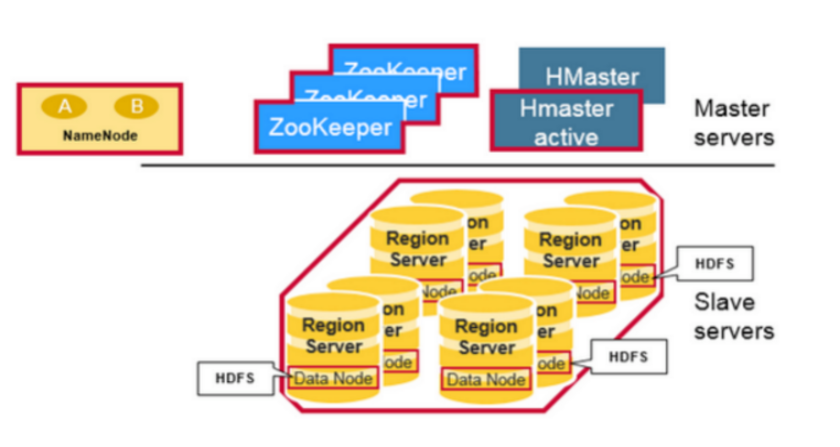
上图清晰的表达了HMaster和NameNode都支持多个热备份,使用ZooKeeper来做协调。
- ZooKeeper一般由三台机器组成一个集群,内部使用PAXOS算法支持三台Server中的一台宕机,也有使用五台机器的,此时则可以支持同时两台宕机,既少于半数的宕机。
- 然而随着机器的增加,它的性能也会下降。
- RegionServer和DataNode一般会放在相同的Server上实现数据的本地化。
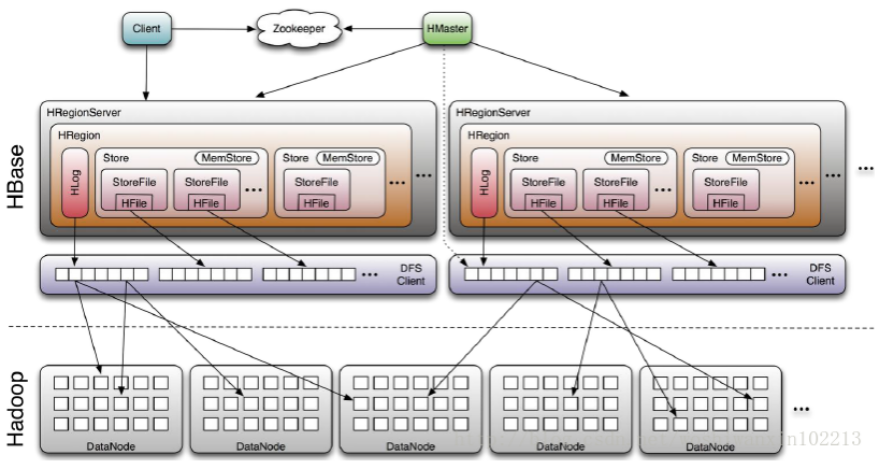
协同工作
- HBase Client通过RPC方式和HMaster、HRegionServer通信。
- 一个HRegionServer可以存放1000个HRegion。
- 底层Table数据存储于HDFS中,而HRegion所处理的数据尽量和数据所在的DataNode在一起,实现数据的本地化。
- 数据本地化并不是总能实现,比如在HRegion移动(如因Split)时,需要等下一次Compact才能继续回到本地化。
Hbase的数据恢复
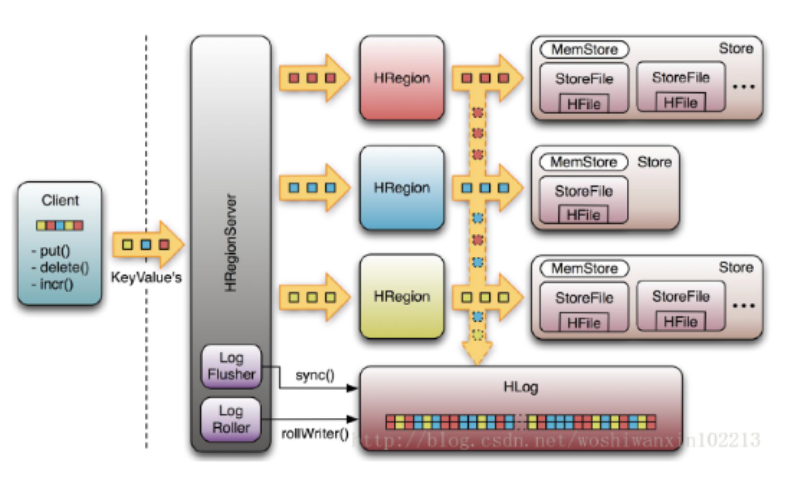
HLog
- 每个HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead Log的类。
- 在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中。
- HLog文件定期会滚动出新的,并删除旧的文件(已持久化到StoreFile中的数据)。
恢复过程
- 当HRegionServer意外终止后,HMaster会通过Zookeeper感知到。
- HMaster首先会处理遗留的HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下。
- 然后再将失效的region重新分配,领取到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理。
- 因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
- 示意图:
Hbase的容错
HRegionServer
- HRegionServer定时向Zookeeper汇报心跳。
- 如果一旦时间内未出现心跳,HMaster将该RegionServer上的Region重新分配到其他RegionServer上。
- 失效服务器上“预写”日志由主服务器进行分割并派送给新的HRegionServer。
HMaster
- 当现有Hmaster出现灾难无法运转,Zookeeper会重新选择一个新的Master,从而保障Master不再是单点故障。
- 无Master过程中,数据读取仍照常进行。
- 无master过程中,region切分、负载均衡等无法进行。
Zookeeper
- Zookeeper是一个可靠地服务,一般配置3或5个Zookeeper实例。
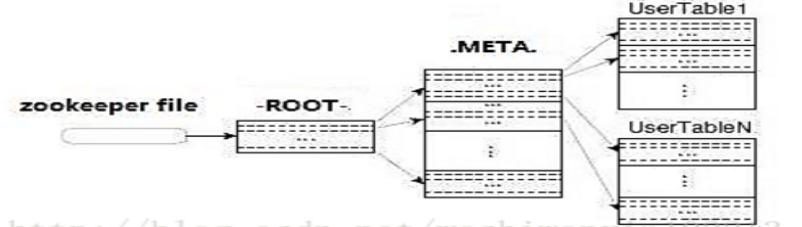
- Region定位流程:ZooKeeper--> -ROOT-(单Region)--> .META.--> 用户表
本文只是简单介绍一下hbase系统架构,后续会详细地补充。
Hbase系统架构简述的更多相关文章
- HBase 系统架构及数据结构
一.基本概念 2.1 Row Key (行键) 2.2 Column Family(列族) 2.3 Column Qualifier (列限定符) 2.4 Column ...
- HBase 学习之路(二)—— HBase系统架构及数据结构
一.基本概念 一个典型的Hbase Table 表如下: 1.1 Row Key (行键) Row Key是用来检索记录的主键.想要访问HBase Table中的数据,只有以下三种方式: 通过指定的R ...
- HBase 系列(二)—— HBase 系统架构及数据结构
一.基本概念 一个典型的 Hbase Table 表如下: 1.1 Row Key (行键) Row Key 是用来检索记录的主键.想要访问 HBase Table 中的数据,只有以下三种方式: 通过 ...
- Hbase系统架构
HBase 系统架构 HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列 ...
- HBase 系统架构
HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列的存储模型.它存储的是 ...
- HBase系统架构及数据结构(转)
原文链接:Hbase系统架构及数据结构 HBase中的表一般有这样的特点: 1 大:一个表可以有上亿行,上百万列 2 面向列:面向列(族)的存储和权限控制,列(族)独立检索. 3 稀疏:对于为空(nu ...
- Hbase 系统架构(zhuan)
一.系统架构 客户端连接hbase依赖于zookeeper,hbase存储依赖于hadoop client: 1.包含访问 hbase 的接口, client 维护着一些 cache(缓存) 来加快对 ...
- 列式存储hbase系统架构学习
一.Hbase简介 HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java.它是Apache软件基金会的Hadoop项目的一部分,运行 ...
- hbase基础-系统架构
HBase 系统架构 HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列 ...
随机推荐
- python3 报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd6 in position 201: invalid continuation byte
代码: # -*- coding:utf-8 -*- from urllib import request resp = request.urlopen('http://www.xxx.com') p ...
- javascript 匿名函数及闭包----转载
网上很多解释,我无法理解,我想知道原理...这篇文章应该可以透彻一点Query片段:view plaincopy to clipboardprint? (function(){ //这里忽略 ...
- webpack之傻瓜式教程及前端自动化入门
原文地址:https://www.cnblogs.com/liqiyuan/p/6246870.html 接触webpack也有挺长一段时间了,公司的项目也是一直用着webpack在打包处理,但前几天 ...
- 【Leetcode】【Medium】Unique Binary Search Trees
Given n, how many structurally unique BST's (binary search trees) that store values 1...n? For examp ...
- QT的动画效果 抖动 下坠 透明 最近在开发QT收藏了好多链接
http://blog.csdn.net/liang19890820/article/details/51888114
- 学习Road map Part 04 自动驾驶、SLAM、ROS、树莓派
学习Road map Part 04 自动驾驶.SLAM.ROS.树莓派
- 如何在 MSBuild Target(Exec)中报告编译错误和编译警告
编译错误和编译警告 MSBuild 的 Exec 自带有错误和警告的标准格式,按照此格式输出,将被识别为编译错误和编译警告. 而格式只是简简单单的 error: 开头或者 warning: 开头.冒号 ...
- git终端操作
1.提交 git add . git commit -m "test" git push origini master 2.分支 创建feature_x分支,并切换到feature ...
- 二十九、利用 IntelliJ IDEA 进行代码对比的方法
我们会有这样的需求,即:想对比出两个不同版本代码的区别.如何实现? 第 1 种:如果我们是从 SVN 检出的项目,并且想比较本地代码与从 SVN 检出时的代码相比都有那些区别,可以按如下步骤操作, 如 ...
- DB2 编目并访问远程数据库
之后将逐步对项目上的DB2相关经验做个总结,梳理一下知识结构. 要远程操作数据库,首先要进行编目,分三个步骤: 1. 在客户端建立服务器端数据库的节点,编目远程节点. 格式如下: 1. CATALOG ...