ruby 爬虫爬取拉钩网职位信息,产生词云报告
思路:1.获取拉勾网搜索到职位的页数
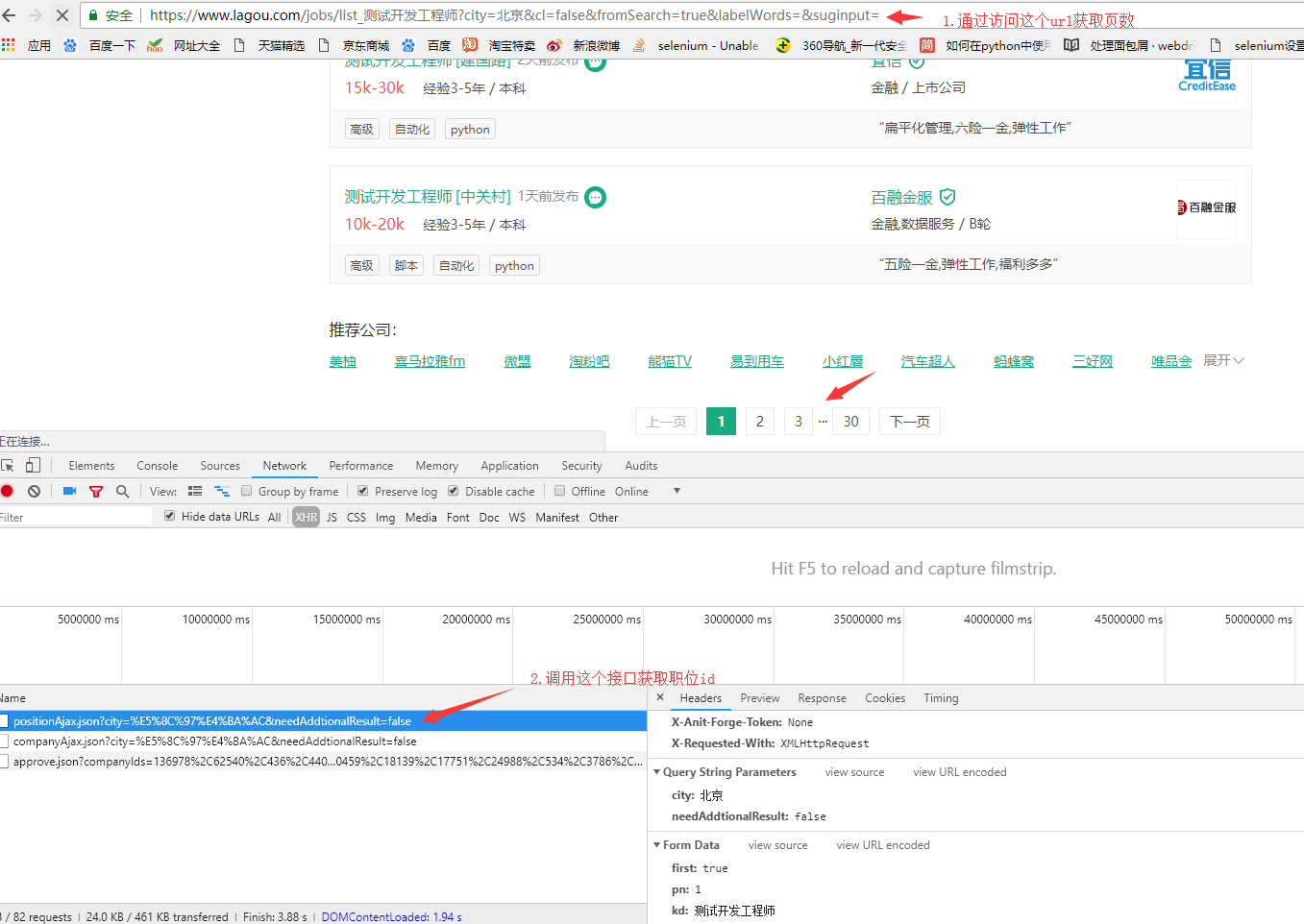
2.调用接口获取职位id
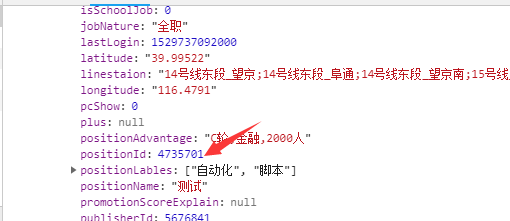
3.根据职位id访问页面,匹配出关键字
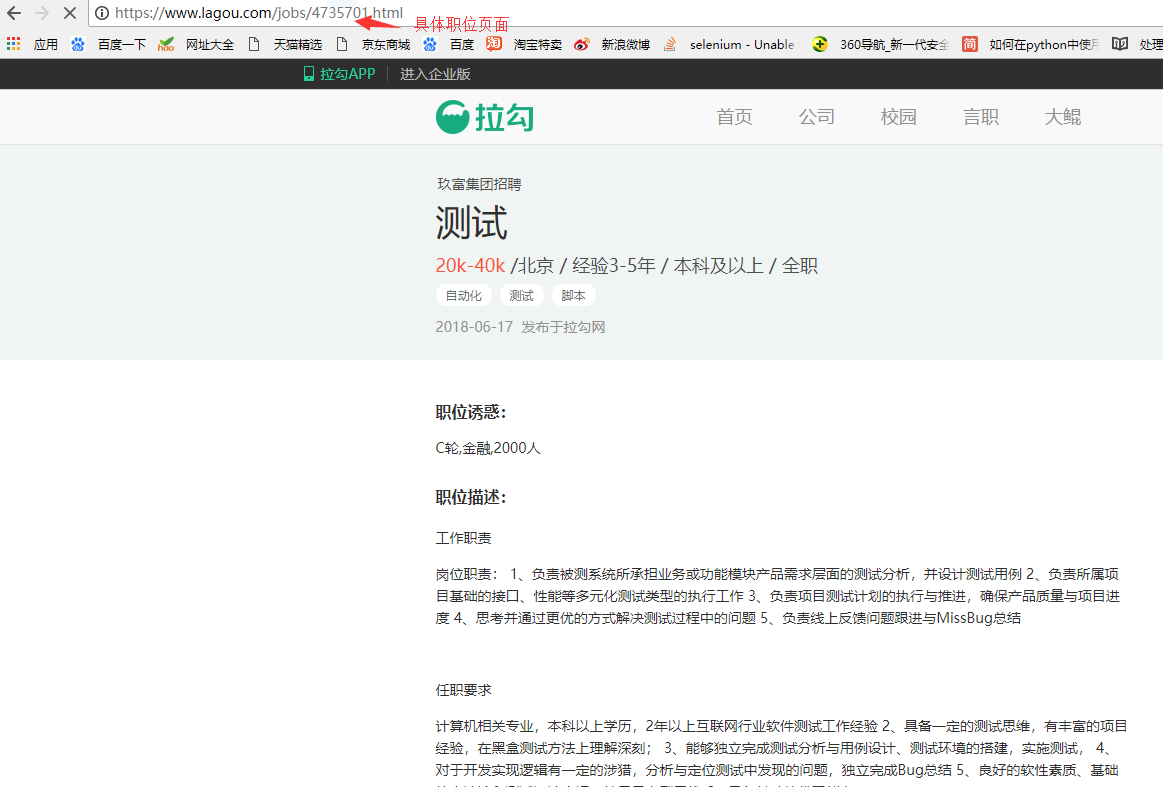
url访问采用unirest,由于拉钩反爬虫,短时间内频繁访问会被限制访问,所以没有采用多线程,而且每个页面访问时间间隔设定为10s,通过nokogiri解析页面,正则匹配只获取技能要求中的英文单词,可能存在数据不准确的情况
数据持久化到excel中,采用ruby erb生成word_cloud报告
爬虫代码:
require 'unirest'
require 'uri'
require 'nokogiri'
require 'json'
require 'win32ole' @position = '测试开发工程师'
@city = '杭州' # 页面访问
def query_url(method, url, headers:{}, parameters:nil)
case method
when :get
Unirest.get(url, headers:headers).body
when :post
Unirest.post(url, headers:headers, parameters:parameters).body
end
end # 获取页数
def get_page_num(url)
html = query_url(:get, url).force_encoding('utf-8')
html.scan(/<span class="span totalNum">(\d+)<\/span>/).first.first
end # 获取每页显示的所有职位的id
def get_positionsId(url, headers:{}, parameters:nil)
response = query_url(:post, url, headers:headers, parameters:parameters)
positions_id = Array.new
response['content']['positionResult']['result'].each{|i| positions_id << i['positionId']}
positions_id
end # 匹配职位英文关键字
def get_skills(url)
puts "loading url: #{url}"
html = query_url(:get, url).force_encoding('utf-8')
doc = Nokogiri::HTML(html)
data = doc.css('dd.job_bt')
data.text.scan(/[a-zA-Z]+/)
end # 计算词频
def word_count(arr)
arr.map!(&:downcase)
arr.select!{|i| i.length>1}
counter = Hash.new(0)
arr.each { |k| counter[k]+=1 }
# 过滤num=1的数据
counter.select!{|_,v| v > 1}
counter2 = counter.sort_by{|_,v| -v}.to_h
counter2
end # 转换
def parse(hash)
data = Array.new
hash.each do |k,v|
word = Hash.new
word['name'] = k
word['value'] = v
data << word
end
JSON data
end # 持久化数据
def save_excel(hash)
excel = WIN32OLE.new('Excel.Application')
excel.visible = false
workbook = excel.Workbooks.Add()
worksheet = workbook.Worksheets(1)
# puts hash.size
(1..hash.size+1).each do |i|
if i == 1
# puts "A#{i}:B#{i}"
worksheet.Range("A#{i}:B#{i}").value = ['关键词', '频次']
else
# puts i
# puts hash.keys[i-2], hash.values[i-2]
worksheet.Range("A#{i}:B#{i}").value = [hash.keys[i-2], hash.values[i-2]]
end
end
excel.DisplayAlerts = false
workbook.saveas(File.dirname(__FILE__)+'\lagouspider.xls')
workbook.saved = true
excel.ActiveWorkbook.Close(1)
excel.Quit()
end # 获取页数
url = URI.encode("https://www.lagou.com/jobs/list_#@position?city=#@city&cl=false&fromSearch=true&labelWords=&suginput=")
num = get_page_num(url).to_i
puts "存在 #{num} 个信息分页" skills = Array.new
(1..num).each do |i|
puts "定位在第#{i}页"
# 获取positionsid
url2 = URI.encode("https://www.lagou.com/jobs/positionAjax.json?city=#@city&needAddtionalResult=false")
headers = {Referer:url, 'User-Agent':i%2==1?'Mozilla/5.0':'Chrome/67.0.3396.87'}
parameters = {first:(i==1), pn:i, kd:@position}
positions_id = get_positionsId(url2, headers:headers, parameters:parameters)
positions_id.each do |id|
# 访问具体职位页面,提取英文技能关键字
url3 = "https://www.lagou.com/jobs/#{id}.html"
skills.concat get_skills(url3)
sleep 10
end
end count = word_count(skills)
save_excel(count)
@data = parse(count)
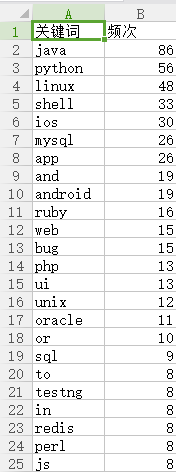
效果展示:

ruby 爬虫爬取拉钩网职位信息,产生词云报告的更多相关文章
- selelinum+PhantomJS 爬取拉钩网职位
使用selenium+PhantomJS爬取拉钩网职位信息,保存在csv文件至本地磁盘 拉钩网的职位页面,点击下一页,职位信息加载,但是浏览器的url的不变,说明数据不是发送get请求得到的. 我们不 ...
- 21天打造分布式爬虫-Selenium爬取拉钩职位信息(六)
6.1.爬取第一页的职位信息 第一页职位信息 from selenium import webdriver from lxml import etree import re import time c ...
- Python3 Scrapy + Selenium + 阿布云爬取拉钩网学习笔记
1 需求分析 想要一个能爬取拉钩网职位详情页的爬虫,来获取详情页内的公司名称.职位名称.薪资待遇.学历要求.岗位需求等信息.该爬虫能够通过配置搜索职位关键字和搜索城市来爬取不同城市的不同职位详情信息, ...
- 爬取拉钩网上所有的python职位
# 2.爬取拉钩网上的所有python职位. from urllib import request,parse import json,random def user_agent(page): #浏览 ...
- 通俗易懂的分析如何用Python实现一只小爬虫,爬取拉勾网的职位信息
源代码:https://github.com/nnngu/LagouSpider 效果预览 思路 1.首先我们打开拉勾网,并搜索"java",显示出来的职位信息就是我们的目标. 2 ...
- 使用request爬取拉钩网信息
通过cookies信息爬取 分析header和cookies 通过subtext粘贴处理header和cookies信息 处理后,方便粘贴到代码中 爬取拉钩信息代码 import requests c ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- 拉钩网爬取所有python职位信息
最近在找工作,所以爬取了拉钩网的全部python职位,以便给自己提供一个方向.拉钩网的数据还是比较容易爬取的,得到json数据直接解析就行,废话不多说, 直接贴代码: import json impo ...
- python爬虫实战之爬取智联职位信息和博客文章信息
1.python爬取招聘信息 简单爬取智联招聘职位信息 # !/usr/bin/env python # -*-coding:utf-8-*- """ @Author ...
随机推荐
- 在Visualsvn Server上创建svn账号和密码
VisualSVN Server是一个集成的svn服务端工具,是一款svn服务端不可多得的好工具.可以先安装好VisualSVN Server后,运行VisualSVN Server Manger,然 ...
- python接口自动化4-绕过验证码登录(cookie) (转载)
前言 有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接). 获取不到也没关系,可以通过添加cookie的方式绕过验证码. 一.抓登录coo ...
- shell 脚本中后台执行命令 &
最近遇到一个问题, 执行脚本,脚本调用 一个命令,命令(deamon)是一个守护进程,为了调试,取消了守护进程模式.导致命令后边的其他命令(echo "456")都无法执行. de ...
- Hyperledger Fabric 1.0 学习搭建 (一)--- 基础环境搭建
1: 环境构建在本文中用到的宿主机环境是Centos ,版本为Centos.x86_64 7.2, 一定要用7版本以上, 要不然会安装出错. 通过Docker 容器来运行Fabric的节点,版本为v1 ...
- July 17th 2017 Week 29th Monday
A heart is a heavy burden. 心,可是很重的. Follow your heart, but always take your brain with you. Easy to ...
- ZT 初始化 const 成员和引用类型成员(C++)
初始化 const 成员和引用类型成员(C++) 初始化 const 成员和引用类型成员的问题,在 C++ 教材中讲述初始化列表的章节应该都有讲过,但是因为平时用得少,所以可能有不少人没注意到.待到用 ...
- angular里forRoot的作用
模块A是这样定义的 @NgModule({ providers: [AService], declarations: [ TitleComponent ], exports: [ TitleCompo ...
- Vue-Quill-Editor插件插入图片的改进
最近在做一个Vue-Clie小项目,使用到了Vue-Quill-Editor这个基于Vue的富文本编辑器插件.这个插件跟Vue契合良好,使用起来比其他的诸如百度UEditor要方便很多,但是存在一个小 ...
- java中的泛型1
1.泛型概述 泛型,即“参数化类型”.一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参.那么参数化类型怎么理解呢?顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数 ...
- was缓存以致web.xml更改无效
was缓存导致web.xml更改无效 在项目中经常遇见这样的问题:修改应用的配置文件web.xml后,无论重启应用还是重启WebSphere服务器,都不能重新加载web.xml,导致修改的内容无效. ...