二叉树及其遍历方法---python实现
github:代码实现
本文算法均使用python3实现
1. 二叉树
1.1 二叉树的定义
二叉树是一种特殊的树,它具有以下特点:
(1)树中每个节点最多只能有两棵树,即每个节点的度最多为2。
(2)二叉树的子树有左右之分,即左子树与右子树,次序不能颠倒。
(3)二叉树即使只有一个子树时,也要区分是左子树还是右子树。
1.2 满二叉树
满二叉树作为一种特殊的二叉树,它是指:所有的分支节点都存在左子树与右子树,并且所有的叶子节点都在同一层上。其特点有:
(1)叶子节点只能出现在最下面一层
(2)非叶子节点度一定是2
(3)在同样深度的二叉树中,满二叉树的节点个数最多,节点个数为: $ 2^h -1 $ ,其中 $ h $ 为树的深度。
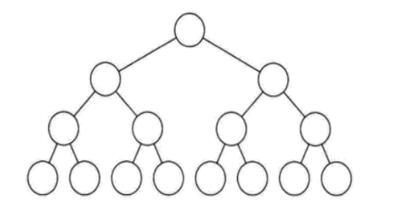
1.3 完全二叉树
若设二叉树的深度为 $ h $ ,除第 $ h $ 层外,其它各层 $ (1~h-1) $ 的结点数都达到最大个数,第 $ h $ 层所有的结点都连续集中在最左边,这就是完全二叉树。其具有以下特点:
(1)叶子节点可以出现在最后一层或倒数第二层。
(2)最后一层的叶子节点一定集中在左部连续位置。
(3)完全二叉树严格按层序编号。(可利用数组或列表进行实现,满二叉树同)
(4)若一个节点为叶子节点,那么编号比其大的节点均为叶子节点。
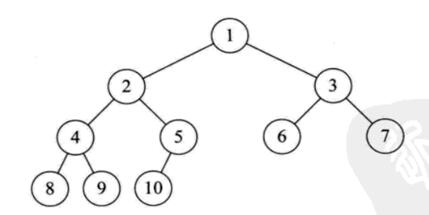
2. 二叉树的相关性质
2.1 二叉树性质
(1)在非空二叉树的 $ i $ 层上,至多有 $ 2^{i-1} $ 个节点 $ (i \geq 1) $ 。
(2)在深度为 $ h $ 的二叉树上最多有 $ 2^h -1 $ 个节点 $(k \geq 1) $ 。
(3)对于任何一棵非空的二叉树,如果叶节点个数为 $ n_0 $ ,度数为 $ 2 $ 的节点个数为 $ n_2 $ ,则有: $ n_0 = n_2 + 1 $ 。
2.1 完全二叉树性质
(1)具有 $ n $ 个的结点的完全二叉树的深度为 $ \log_2{n+1} $ 。.
(2)如果有一颗有 $ n $ 个节点的完全二叉树的节点按层次序编号,对任一层的节点 $ i ,(1 \geq i \geq n)$ 有:
(2.1)如果 $ i=1 $ ,则节点是二叉树的根,无双亲,如果 $ i>1 $ ,则其双亲节点为 $ \lfloor i/2 \rfloor $ 。
(2.2)如果 $ 2i>n $ 那么节点i没有左孩子,否则其左孩子为 $ 2i $ 。
(2.3)如果 $ 2i+1>n $ 那么节点没有右孩子,否则右孩子为 $ 2i+1 $ 。
3. 二叉树的遍历
以下遍历以该二叉树为例:
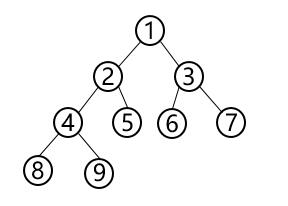
3.1 前序遍历
思想:先访问根节点,再先序遍历左子树,然后再先序遍历右子树。总的来说是根—左—右
上图先序遍历结果为为:$ 1,2,4,8,9,5,3,6,7 $
代码如下:
def PreOrder(self, root):
'''打印二叉树(先序)'''
if root == None:
return
print(root.val, end=' ')
self.PreOrder(root.left)
self.PreOrder(root.right)
3.2 中序遍历
思想:先中序访问左子树,然后访问根,最后中序访问右子树。总的来说是左—根—右
上图中序遍历结果为为:$ 8,4,9,2,5,1,6,3,7 $
代码如下:
def InOrder(self, root):
'''中序打印'''
if root == None:
return
self.InOrder(root.left)
print(root.val, end=' ')
self.InOrder(root.right)
3.3 后序遍历
思想:先后序访问左子树,然后后序访问右子树,最后访问根。总的来说是左—右—根
上图后序遍历结果为为:$ 8,9,4,5,2,6,7,3,1 $
代码如下:
def BacOrder(self, root):
'''后序打印'''
if root == None:
return
self.BacOrder(root.left)
self.BacOrder(root.right)
print(root.val, end=' ')
3.4 层次遍历(宽度优先遍历)
思想:利用队列,依次将根,左子树,右子树存入队列,按照队列的先进先出规则来实现层次遍历。
上图后序遍历结果为为:$ 1,2,3,4,5,6,7,8,9 $
代码如下:
def BFS(self, root):
'''广度优先'''
if root == None:
return
# queue队列,保存节点
queue = []
# res保存节点值,作为结果
#vals = []
queue.append(root)
while queue:
# 拿出队首节点
currentNode = queue.pop(0)
#vals.append(currentNode.val)
print(currentNode.val, end=' ')
if currentNode.left:
queue.append(currentNode.left)
if currentNode.right:
queue.append(currentNode.right)
#return vals
3.5 深度优先遍历
思想:利用栈,先将根入栈,再将根出栈,并将根的右子树,左子树存入栈,按照栈的先进后出规则来实现深度优先遍历。
上图后序遍历结果为为:$ 1,2,4,8,9,5,3,6,7 $
代码如下:
def DFS(self, root):
'''深度优先'''
if root == None:
return
# 栈用来保存未访问节点
stack = []
# vals保存节点值,作为结果
#vals = []
stack.append(root)
while stack:
# 拿出栈顶节点
currentNode = stack.pop()
#vals.append(currentNode.val)
print(currentNode.val, end=' ')
if currentNode.right:
stack.append(currentNode.right)
if currentNode.left:
stack.append(currentNode.left)
#return vals
3.6 代码运行结果

引用及参考:
[1]《数据结构》李春葆著
[2] http://www.cnblogs.com/polly333/p/4740355.html
写在最后:本文参考以上资料进行整合与总结,属于原创,文章中可能出现理解不当的地方,若有所见解或异议可在下方评论,谢谢!
若需转载请注明:https://www.cnblogs.com/lliuye/p/9143676.html
二叉树及其遍历方法---python实现的更多相关文章
- 【数据结构】二叉树的遍历(前、中、后序及层次遍历)及leetcode107题python实现
文章目录 二叉树及遍历 二叉树概念 二叉树的遍历及python实现 二叉树的遍历 python实现 leetcode107题python实现 题目描述 python实现 二叉树及遍历 二叉树概念 二叉 ...
- 算法与数据结构(三) 二叉树的遍历及其线索化(Swift版)
前面两篇博客介绍了线性表的顺序存储与链式存储以及对应的操作,并且还聊了栈与队列的相关内容.本篇博客我们就继续聊数据结构的相关东西,并且所涉及的相关Demo依然使用面向对象语言Swift来表示.本篇博客 ...
- python数据结构与算法——二叉树结构与遍历方法
先序遍历,中序遍历,后序遍历 ,区别在于三条核心语句的位置 层序遍历 采用队列的遍历操作第一次访问根,在访问根的左孩子,接着访问根的有孩子,然后下一层 自左向右一一访问同层的结点 # 先序遍历 # ...
- python基本数据类型list,tuple,set,dict用法以及遍历方法
1.list类型 类似于java的list类型,数据集合,可以追加元素与删除元素. 遍历list可以用下标进行遍历,也可以用迭代器遍历list集合 建立list的时候用[]括号 import sys ...
- Python与数据结构[3] -> 树/Tree[0] -> 二叉树及遍历二叉树的 Python 实现
二叉树 / Binary Tree 二叉树是树结构的一种,但二叉树的每一个节点都最多只能有两个子节点. Binary Tree: 00 |_____ | | 00 00 |__ |__ | | | | ...
- python实现二叉树的遍历以及基本操作
主要内容: 二叉树遍历(先序.中序.后序.宽度优先遍历)的迭代实现和递归实现: 二叉树的深度,二叉树到叶子节点的所有路径: 首先,先定义二叉树类(python3),代码如下: class TreeNo ...
- 二叉搜索树 & 二叉树 & 遍历方法
二叉搜索树 & 二叉树 & 遍历方法 二叉搜索树 BST / binary search tree https://en.wikipedia.org/wiki/Binary_searc ...
- python 中 五种字典(dict)的遍历方法,实验法比较性能。
1 .背景: 想知道5种遍历方法,并且知道从性能角度考虑,使用哪种. 2.结论: 使用这种方式: for key,val in AutoDict.iteritems(): temp = "% ...
- Python算法-二叉树深度优先遍历
二叉树 组成: 1.根节点 BinaryTree:root 2.每一个节点,都有左子节点和右子节点(可以为空) TreeNode:value.left.right 二叉树的遍历: 遍历二叉树:深度 ...
随机推荐
- PHP读取zip包
$filename = $this->upload->data('file_name'); //得到文件夹(此处是CI框架上传文件之后得到文件名称) $file_root = 'can ...
- 关于mysql 8.0.13zip包安装
mysql 8.0.13默认有一个data文件夹,这个文件夹得删了,不然安装服务时候会有日志文件提示报错: Failed to find valid data directory. Data Dict ...
- 立个Flag (20180617-20181231)
入行7年,今年年初正式接触Java,前面6年一直在做C++相关的工作,去年年中跳槽,语言从C++转向了C#,半年之后又转向了Java. 虽说语言有相似性,但每种语言都有自己独有的知识体系,想要游刃有余 ...
- 【commons】字符串工具类——commons-lang3之StringUtils
类似工具见Hutool-StrUtil 一.起步 引入maven依赖 <!-- https://mvnrepository.com/artifact/org.apache.commons/com ...
- 20145226夏艺华《网络对抗》第一次实验拓展:shellcode注入+return-to-libc
20145226夏艺华<网络对抗>第一次实验拓展:shellcode注入+return-to-libc shellcode注入实践 编写shellcode 编写shellcode已经在之前 ...
- Prism for WPF 搭建一个简单的模块化开发框架(一)
原文:Prism for WPF 搭建一个简单的模块化开发框架(一) 最近闲来无事又想搞搞WPF..... 做个框架吧,可能又是半途而废....总是坚持不下来 不废话了, 先看一下工程结构 布局大概是 ...
- SVN的使用——下载、安装
今天我们来学习一下如何使用SVN(Subversion) 既然要使用SVN那么我们就先来认识一下SVN.SVN的全名是Subversion,它是一个自由,开源的版本控制系统.在Subversion管理 ...
- TCP/IP漫游
TCP/IP漫游 TCP/IP是互联网的基础协议栈,它包括大大小小几十个协议.本篇文章主要涉及到就是HTTP.TCP.IP协议.我们经常学的网络模型是七层或者五层,实际上一般认为一共只有四层就可以了. ...
- MySQL高级-查询截取分析
一.如何分析 1.观察.至少跑1天,看看生产的慢SQL情况. 2.开启慢查询日志,设置阙值比如超过5秒钟的就是慢SQL,并将它抓取出来. 3.explain + 慢SQL分析 4.show profi ...
- VIM第七版
ZZ:退出并保存 e!:退回到上次保存时的样子 cw:修改单词(自动进入插入模式) cc:修改一整行的内容 cs:修改一个词(自动进入插入模式) .:可以重复上一个命令 J:将下一行内容合并到本行末尾 ...