druid
实时分析型数据库
Druid | Interactive Analytics at Scale http://druid.io/
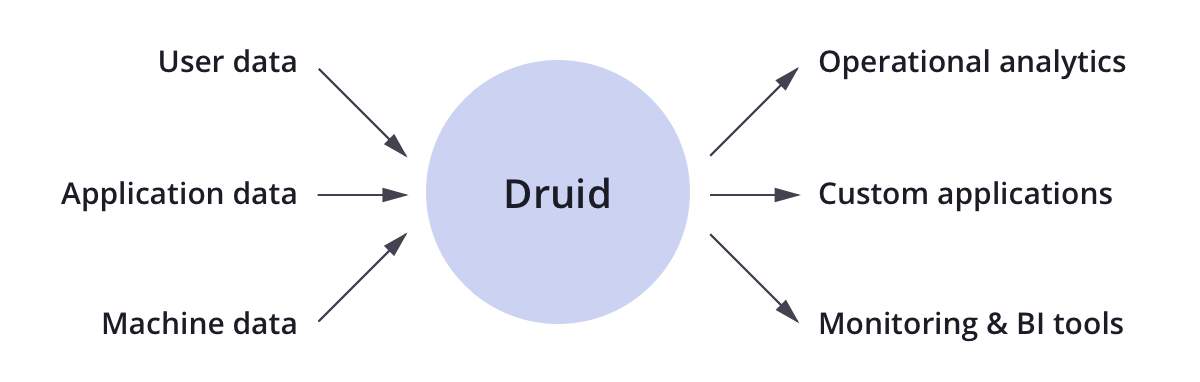
Druid is primarily used to store, query, and analyze large event streams. Examples of event streams include user generated data such as clickstreams, application generated data such as performance metrics, and machine generated data such as network flows and server metrics. Druid is optimized for sub-second queries to slice-and-dice, drill down, search, filter, and aggregate this data. Druid is commonly used to power interactive applications where performance, concurrency, and uptime are important.
Druid was initially created to power a scalable, visual, multi-tenant application where users could not only rapidly slice and dice data to create ad-hoc reports, but also interactively explore data to quickly determine the root cause of patterns and anomalies. Druid is designed from the ground up for sub-second queries, which are critical in interactive applications as usability studies have shown that humans get distracted and lose their train of thought if responses take longer than a second.
Design
Druid’s core design combines ideas from OLAP/analytic databases, timeseries databases, and search systems to create a unified system for operational analytics. Core design ideas include:
Column-oriented storage
Druid stores and compresses each column individually, and only needs to read the ones needed for a particular query, which supports fast scans, rankings, and groupBys.
Native search indexes
Druid creates inverted indexes for string values for fast search and filter.
Streaming and batch ingest
Out-of-the-box connectors for Apache Kafka, HDFS, AWS S3, stream processors, and more.
Flexible schemas
Druid gracefully handles evolving schemas and nested data.
Time-optimized partitioning
Druid intelligently partitions data based on time and time-based queries are significantly faster than traditional databases.
SQL support
In addition to its native JSON based language, Druid speaks SQL over either HTTP or JDBC.
Horizontally scalable
Druid has been used in production to ingest millions of events/sec, retain years of data, and provide sub-second queries.
Easy to operate
Scale up or down by just adding or removing servers, and Druid automatically rebalances. Fault-tolerant architecture routes around server failures.
To learn more, read our Technology page.
Use cases
Druid is proven in production at the world’s leading companies, with the largest installations having more than a thousand servers, ingesting over 10 million events per second, and supporting thousands of concurrent queries per second. Druid is used to:
Analyze performance
Create interactive dashboards with full drill down capabilities. Analyze performance of digital products, track mobile app usage, or monitor site reliability.
Diagnose problems
Find the root cause of issues. Troubleshoot netflow bottlenecks, analyze security threats, or diagnose software crashes.
Find commonalities
Find common attributes among events. Identify shared components in defective products, or determine patterns in top performing products.
Increase efficiency
Improve product engagement. Optimize ad-spend in digital marketing campaigns or increase user engagement in online products.
To learn more, read our Use Cases page.
druid的更多相关文章
- Spring + SpringMVC + Druid + MyBatis 给你一个灵活的后端解决方案
生命不息,折腾不止. 折腾能遇到很多坑,填坑我理解为成长. 两个月前自己倒腾了一套用开源框架构建的 JavaWeb 后端解决方案. Spring + SpringMVC + Druid + JPA(H ...
- Spring + SpringMVC + Druid + JPA(Hibernate impl) 给你一个稳妥的后端解决方案
最近手头的工作不太繁重,自己试着倒腾了一套用开源框架组建的 JavaWeb 后端解决方案. 感觉还不错的样子,但实践和项目实战还是有很大的落差,这里只做抛砖引玉之用. 项目 git 地址:https: ...
- 学记:spring boot使用官网推荐以外的其他数据源druid
虽然spring boot提供了4种数据源的配置,但是如果要使用其他的数据源怎么办?例如,有人就是喜欢druid可以监控的强大功能,有些人项目的需要使用c3p0,那么,我们就没办法了吗?我们就要编程式 ...
- druid连接池获取不到连接的一种情况
数据源一开始配置: jdbc.initialSize=1jdbc.minIdle=1jdbc.maxActive=5 程序运行一段时间后,执行查询抛如下异常: exception=org.mybati ...
- druid配置数据库连接使用密文密码
spring使用druid配置dataSource片段代码 dataSource配置 <!-- 基于Druid数据库链接池的数据源配置 --> <bean id="data ...
- [转]阿里巴巴数据库连接池 druid配置详解
一.背景 java程序很大一部分要操作数据库,为了提高性能操作数据库的时候,又不得不使用数据库连接池.数据库连接池有很多选择,c3p.dhcp.proxool等,druid作为一名后起之秀,凭借其出色 ...
- 技术杂记-改造具有监控功能的数据库连接池阿里Druid,支持simple-jndi,kettle
kettle内置的jndi管理是simple-jndi,功能确实比较简单,我需要监控kettle性能,druid确实是很不错的选择,但没有提供对应的支持,我改进了druid源码,实现了simple-j ...
- sql 连接数不释放 ,Druid异常:wait millis 40000, active 600, maxActive 600
Hibernate + Spring + Druid 数据库mysql 由于配置如下 <bean id="dataSource" class="com.alibab ...
- druid sql黑名单 报异常 sql injection violation, part alway true condition not allow
最近使用druid,发现阿里这个连接池 真的很好用,可以监控到连接池活跃连接数 开辟到多少个连接数 关闭了多少个,对于我在项目中查看错误 问题,很有帮助, 但是最近发现里面 有条sql语句 被拦截了, ...
- 从零开始学 Java - 数据库连接池的选择 Druid
我先说说数据库连接 数据库大家都不陌生,从名字就能看出来它是「存放数据的仓库」,那我们怎么去「仓库」取东西呢?当然需要钥匙啦!这就是我们的数据库用户名.密码了,然后我们就可以打开门去任意的存取东西了. ...
随机推荐
- 测试-一个unity的编译bug,初始化器
.net C#下测试: public class Class1 { public bool toggle1 = true; public bool toggle2; } 一个结构类Class1,对里面 ...
- Atitit。Js调用后台语言 java c# php swing android swt的方法大总结
Atitit.Js调用后台语言 java c# php swing android swt的方法大总结 1. Js调用后台语言有三种方法1 2. Swt BrowserFunction 绑定方法 ...
- Zynq GPIO 中断
/* * Copyright (c) 2009-2012 Xilinx, Inc. All rights reserved. * * Xilinx, Inc. * XILINX IS PROVIDIN ...
- Objective-C中的类型转换
转自:http://blog.csdn.net/lonelyroamer/article/details/7711920 类型转换 表2-3列出了简单数据类型.示例和格式符. 表2-3 简单数据类型. ...
- 使用BleLib的轻松搞定Android低功耗蓝牙Ble 4.0开发具体解释
转载请注明来源: http://blog.csdn.net/kjunchen/article/details/50909410 使用BleLib的轻松搞定Android低功耗蓝牙Ble 4.0开发具体 ...
- ORACLE的显式游标与隐式游标
1)查询返回单行记录时→隐式游标: 2)查询返回多行记录并逐行进行处理时→显式游标 显式游标例子: DECLARE CURSOR CUR_EMP IS SELECT * FROM EMP; ROW_E ...
- sitemesh 2.4 装饰器学习
SiteMesh 是一个网页布局和修饰的框架,利用它可以将网页的内容和页面结构分离,以达到页面结构共享的目的 SiteMesh是OpenSymphony团队开发的JEE框架之一,它是一个非常优秀的页面 ...
- Java监听模式
说明 生活中,监听无处不在.比如说,手机播放音乐功能,也是一种监听:你不点击播放按钮,手机就不放歌,当你点击时,手机就播放音乐.即触发某种行为,便执行相应的动作. 组成 Java监听模式右三个部分组成 ...
- HTML5 的位置
HTML5 的位置 在HTML5COL学院的前面几个章节中我们已经对HTML5 Geolocation API有了一定认识,接下来我们要对位置做些更有意思的处理:看看你与我们HTML5COL学院的办公 ...
- 作为一个Linux/Unix程序员有哪些要求
C程序开发: 熟悉数据库sql语言: 熟练掌握C语言(面向过程的),掌握C++(面向对象的) 工程管理工具:make,会写Makefile 熟悉IBM DB2.Informix.Sysbase.SQL ...