pythonl学习笔记——爬虫的基本常识
1 robots协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
如:
淘宝网:https://www.taobao.com/robots.txt
User-agent: Baiduspider Allow: /article Allow: /oshtml Disallow: /product/ Disallow: / User-Agent: Googlebot Allow: /article Allow: /oshtml Allow: /product Allow: /spu Allow: /dianpu Allow: /oversea Allow: /list Disallow: /...
腾讯网:http://www.qq.com/robots.txt
User-agent: * Disallow: Sitemap: http://www.qq.com/sitemap_index.xml
豆瓣网:https://www.douban.com/robots.txt
马蜂窝:http://www.mafengwo.cn/robots.txt
搜索引擎和DNS解析服务商(DNSPod)合作,新网站域名将被迅速抓取。但搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件内容,如标注为nofollow的链接,或者是Robots协议;另一种则是通过网站的站长主动对搜索引擎提交的网址,搜索引擎则会在接下来派出“蜘蛛”,对该网站进行爬取。
2 网站地图sitemap
网站地图sitemap是网站所有链接的容器;是依据网站的结构、框架、内容生长的导航页面文件,一般存放在根目录下并命名为sitemap。
很多网站的链接层次较深,蜘蛛很难抓取到,网站地图可方便搜索引擎蜘蛛抓取网站页面,增加网站重要内容页面的收录,以便清晰了解网站的架构
网站地图sitemap有两种形式
2.1 HTML
HTML版本的网站地图,也即网站上所有页面的链接,但对于规模较大的网站来说,一种办法是网站地图只列出网站最主要的链接,如一级分类、二级分类;第二种办法是将网站地图分成几个文件,主网站地图列出次级网站的链接,次级网站列出部分页面链接
2.2 XML
XML版本网站地图是由Google首先提出的,其是由XML标签组成的,文件本身必须是utf-8编码,网站地图文件实际上就是列出网站需要被收录页面的URL,最简单的网站地图可以是一个纯文本,文件只要列出页面的URL,一行列一个URL,搜索引擎就能抓取并理解文件内容
也可以使用第三方工具生成某网站的sitemap ,例如小爬虫sitemap网站地图生成工具
3 估算网站的大小
可以使用搜索引擎来估算网站大小,如搜索时添加site。
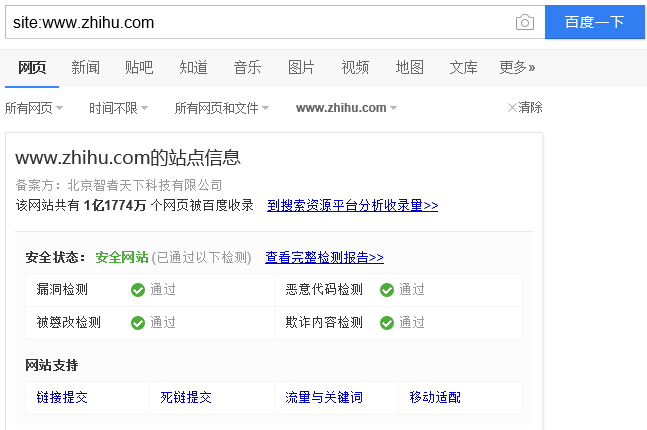
该方法仅是通过百度搜索引擎大致估算网站大小,因有些网站对爬虫的限制,以及搜索引擎本身爬取数据技术的局限性,所以该数据仅是估算值,是估算网站体量量级的经验值。
注:百度只能做一级页面的统计,Google可以做到二级页面的统计
4 识别网站中用了何种技术
为了更好地了解网站,抓取该网站的信息,我们可先了解一下该网站大致所使用的技术架构
builtwith
安装:(windows)pip install bulitwith; (Linux)sudo pip install builtith
使用:在python交互环境下,输入:
import builtwith
builtwith.parse("http://www.sina.com.cn")
5 确定网站的所有着
有时候需要追寻网站的所有者是谁,可以通过python-whois软件查看
whois
安装:(windows)pip install python-whois
使用:在python交互环境下输入:
import whois
whois.whois("http://www.sina.com.cn")
pythonl学习笔记——爬虫的基本常识的更多相关文章
- pythonl练习笔记——爬虫的初级、中级、高级所匹配的知识
1 初级爬虫 (1)Web前端的知识:HTML, CSS, JavaScript, DOM, DHTML, Ajax, jQuery,json等: (2)正则表达式,能提取正常一般网页中想要的信息,比 ...
- Scrapy爬虫学习笔记 - 爬虫基础知识
一.正则表达式 二.深度和广度优先 三.爬虫去重策略
- JS学习笔记1_基础与常识
1.六种数据类型 5种基础的:Undefined,Null,Boolean,Number,String(其中Undefined派生自Null) 1种复杂的:Object(本质是一组无序键值对) 2.字 ...
- python学习笔记——爬虫学习中的重要库urllib
1 urllib概述 1.1 urllib库中的模块类型 urllib是python内置的http请求库 其提供了如下功能: (1)error 异常处理模块 (2)parse url解析模块 (3)r ...
- python学习笔记——爬虫中提取网页中的信息
1 数据类型 网页中的数据类型可分为结构化数据.半结构化数据.非结构化数据三种 1.1 结构化数据 常见的是MySQL,表现为二维形式的数据 1.2 半结构化数据 是结构化数据的一种形式,并不符合关系 ...
- python学习笔记——爬虫的抓取策略
1 深度优先算法 2 广度/宽度优先策略 3 完全二叉树遍历结果 深度优先遍历的结果:[1, 3, 5, 7, 9, 4, 12, 11, 2, 6, 14, 13, 8, 10] 广度优先遍历的结果 ...
- JavaScript学习笔记1_基础与常识
1.六种数据类型 5种基础的:Undefined,Null,Boolean,Number,String(其中Undefined派生自Null) 1种复杂的:Object(本质是一组无序键值对) 2.字 ...
- python库学习笔记——爬虫常用的BeautifulSoup的介绍
1. 开启Beautiful Soup 之旅 在这里先分享官方文档链接,不过内容是有些多,也不够条理,在此本文章做一下整理方便大家参考. 官方文档 2. 创建 Beautiful Soup 对象 首先 ...
- 《Unix&Linux大学教程》学习笔记三:Shell常识
1:全局变量与局部变量 全局:可以从父进程传递给子进程的变量,如:环境变量. 局部:只能在特定的子Shell中使用的变量. 局部变量变全局:使用 “export 局部” 指令将创建的局部变量导出到环境 ...
随机推荐
- WhyEngine游戏引擎作品合集
从9月份开始写三个月内总共实现了13个游戏,5个屏保程序,5个DEMO程序.如果运行时,报有木马病毒什么的,请相信我,这绝对是杀毒软件的误报,自己写的程序由于没有得到杀毒软件的认证,被报有危险是正常的 ...
- Informatica 常用组件Source Qualifier之八 会话前和会话后 SQL
可以在源限定符转换的"属性"选项卡中添加会话前和会话后 SQL 命令.您可能要使用会话前 SQL 以在会话开始时将时间标识行写入源表. PowerCenter 在读取源之前对源 ...
- 【SDN】SDN相关资料--了解一下电信领域的SDN
SDN相关资料 数据中心架构下ospf bgp如何选择及优缺点? - 数据中心 - 知乎 组播扩展OSPF_百度百科 carrier.huawei.com/cn/products/fixed-netw ...
- 关于COM的Unicode string的精彩论述
I need to make a detour for a few moments, and discuss how to handle strings in COM code. If you are ...
- Java从零开始学十七(简单工厂)
简单工厂的实现 实现一个计算器:要求输入2个数,和运算符,得到结果 Operation类 package com.pb.demo1; public class Operation { private ...
- Showing a tooltip
We can provide a balloon help for any of our widgets. #!/usr/bin/python # -*- coding: utf-8 -*- &quo ...
- Linux内核结构体--kfifo 环状缓冲区
转载链接:http://blog.csdn.net/yusiguyuan/article/details/41985907 1.前言 最近项目中用到一个环形缓冲区(ring buffer),代码是由L ...
- 启动mysql出现1067错误
0. 打开mysql\bin\my.ini,查找[mysqld],在[mysqld]下面添加一行文字,skip-grant-tables 即组成 [mysqld] skip-grant-tables[ ...
- taro 在components文件夹中 新建组件时,组件支持自定义命名,但是不能大写开头
在components文件夹中 新建组件时,组件支持自定义命名,但是不能大写开头.否则会报错 错误写法: // 真实路径 import MinaMask from '../../components/ ...
- Python 图形界面(GUI)设计
不要问我为什么要用 Python 来做这种事,我回到“高兴咋地”也不是不可以,总之好奇有没有好的解决方案.逛了一圈下来,总体上来说,Python 图形界面有以下几个可行度比较高的解决方案. 1. py ...