pythonl学习笔记——爬虫的基本常识
1 robots协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
如:
淘宝网:https://www.taobao.com/robots.txt
User-agent: Baiduspider Allow: /article Allow: /oshtml Disallow: /product/ Disallow: / User-Agent: Googlebot Allow: /article Allow: /oshtml Allow: /product Allow: /spu Allow: /dianpu Allow: /oversea Allow: /list Disallow: /...
腾讯网:http://www.qq.com/robots.txt
User-agent: * Disallow: Sitemap: http://www.qq.com/sitemap_index.xml
豆瓣网:https://www.douban.com/robots.txt
马蜂窝:http://www.mafengwo.cn/robots.txt
搜索引擎和DNS解析服务商(DNSPod)合作,新网站域名将被迅速抓取。但搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件内容,如标注为nofollow的链接,或者是Robots协议;另一种则是通过网站的站长主动对搜索引擎提交的网址,搜索引擎则会在接下来派出“蜘蛛”,对该网站进行爬取。
2 网站地图sitemap
网站地图sitemap是网站所有链接的容器;是依据网站的结构、框架、内容生长的导航页面文件,一般存放在根目录下并命名为sitemap。
很多网站的链接层次较深,蜘蛛很难抓取到,网站地图可方便搜索引擎蜘蛛抓取网站页面,增加网站重要内容页面的收录,以便清晰了解网站的架构
网站地图sitemap有两种形式
2.1 HTML
HTML版本的网站地图,也即网站上所有页面的链接,但对于规模较大的网站来说,一种办法是网站地图只列出网站最主要的链接,如一级分类、二级分类;第二种办法是将网站地图分成几个文件,主网站地图列出次级网站的链接,次级网站列出部分页面链接
2.2 XML
XML版本网站地图是由Google首先提出的,其是由XML标签组成的,文件本身必须是utf-8编码,网站地图文件实际上就是列出网站需要被收录页面的URL,最简单的网站地图可以是一个纯文本,文件只要列出页面的URL,一行列一个URL,搜索引擎就能抓取并理解文件内容
也可以使用第三方工具生成某网站的sitemap ,例如小爬虫sitemap网站地图生成工具
3 估算网站的大小
可以使用搜索引擎来估算网站大小,如搜索时添加site。
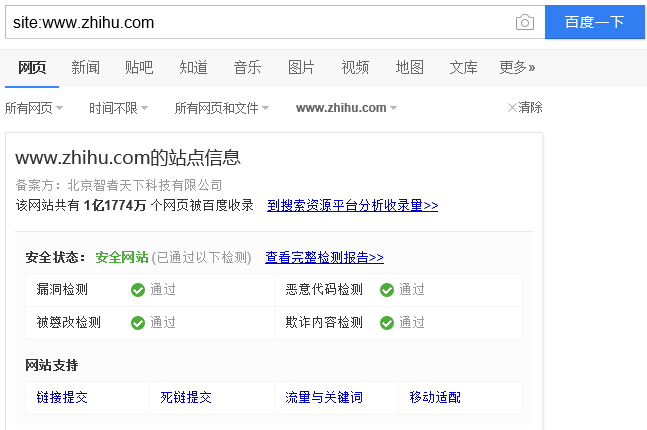
该方法仅是通过百度搜索引擎大致估算网站大小,因有些网站对爬虫的限制,以及搜索引擎本身爬取数据技术的局限性,所以该数据仅是估算值,是估算网站体量量级的经验值。
注:百度只能做一级页面的统计,Google可以做到二级页面的统计
4 识别网站中用了何种技术
为了更好地了解网站,抓取该网站的信息,我们可先了解一下该网站大致所使用的技术架构
builtwith
安装:(windows)pip install bulitwith; (Linux)sudo pip install builtith
使用:在python交互环境下,输入:
import builtwith
builtwith.parse("http://www.sina.com.cn")
5 确定网站的所有着
有时候需要追寻网站的所有者是谁,可以通过python-whois软件查看
whois
安装:(windows)pip install python-whois
使用:在python交互环境下输入:
import whois
whois.whois("http://www.sina.com.cn")
pythonl学习笔记——爬虫的基本常识的更多相关文章
- pythonl练习笔记——爬虫的初级、中级、高级所匹配的知识
1 初级爬虫 (1)Web前端的知识:HTML, CSS, JavaScript, DOM, DHTML, Ajax, jQuery,json等: (2)正则表达式,能提取正常一般网页中想要的信息,比 ...
- Scrapy爬虫学习笔记 - 爬虫基础知识
一.正则表达式 二.深度和广度优先 三.爬虫去重策略
- JS学习笔记1_基础与常识
1.六种数据类型 5种基础的:Undefined,Null,Boolean,Number,String(其中Undefined派生自Null) 1种复杂的:Object(本质是一组无序键值对) 2.字 ...
- python学习笔记——爬虫学习中的重要库urllib
1 urllib概述 1.1 urllib库中的模块类型 urllib是python内置的http请求库 其提供了如下功能: (1)error 异常处理模块 (2)parse url解析模块 (3)r ...
- python学习笔记——爬虫中提取网页中的信息
1 数据类型 网页中的数据类型可分为结构化数据.半结构化数据.非结构化数据三种 1.1 结构化数据 常见的是MySQL,表现为二维形式的数据 1.2 半结构化数据 是结构化数据的一种形式,并不符合关系 ...
- python学习笔记——爬虫的抓取策略
1 深度优先算法 2 广度/宽度优先策略 3 完全二叉树遍历结果 深度优先遍历的结果:[1, 3, 5, 7, 9, 4, 12, 11, 2, 6, 14, 13, 8, 10] 广度优先遍历的结果 ...
- JavaScript学习笔记1_基础与常识
1.六种数据类型 5种基础的:Undefined,Null,Boolean,Number,String(其中Undefined派生自Null) 1种复杂的:Object(本质是一组无序键值对) 2.字 ...
- python库学习笔记——爬虫常用的BeautifulSoup的介绍
1. 开启Beautiful Soup 之旅 在这里先分享官方文档链接,不过内容是有些多,也不够条理,在此本文章做一下整理方便大家参考. 官方文档 2. 创建 Beautiful Soup 对象 首先 ...
- 《Unix&Linux大学教程》学习笔记三:Shell常识
1:全局变量与局部变量 全局:可以从父进程传递给子进程的变量,如:环境变量. 局部:只能在特定的子Shell中使用的变量. 局部变量变全局:使用 “export 局部” 指令将创建的局部变量导出到环境 ...
随机推荐
- java中需要用equals来判断两个字符串值是否相等
在C++中,两个字符串比较的代码可以为: (string1==string2) 但在java中,这个代码即使在两个字符串完全相同的情况下也会返回false Java中必须使用string1.equal ...
- 【Todo】React & Nodejs学习 &事件驱动,非阻塞IO & JS知识栈:Node为主,JQuery为辅,Bootstrap & React为辅辅,其他如Angular了解用途即可
JS知识栈:Node为主,JQuery为辅,Bootstrap & React为辅辅,其他如Angular了解用途即可 今天在学习ReactJS和NodeJS,看到关于ReactJS的这篇文章 ...
- 80端口占用异常解决方法java.net.BindException: Address already in use: JVM_Bind:80(或8080)
1:Tomcat(或其他Web容器)启动时控制台报错如下示: 2007-8-2 15:20:43 org.apache.coyote.http11.Http11Protocol init 严重: Er ...
- 以ScaleIO 1.30为后端存储运行微软服务器软件SQL Server 2014, SharePoint 2013, Exchange 2013的解决方案
EMC新发布了以ScaleIO 1.30为后端存储来运行SQL, SharePoint, Exchange的解决方案白皮书. 下面的页面中有简要的介绍和整篇文档PDF的下载. https://co ...
- Evaluate Reverse Polish Notation leetcode java
题目: Evaluate the value of an arithmetic expression in Reverse Polish Notation. Valid operators are + ...
- 【WCF】HTTP 无法注册 URL 进程,不具有此命名空间的访问权限
背景 如题,在运行WCF宿主主机时,出现了问题. 捕获异常为:HTTP 无法注册 URL http://+:8000/WCF/.进程不具有此命名空间的访问权限(有关详细信息,请参见 http: ...
- 解决在ubuntu 12.10安装vmware-tools实现文件共享问题
解决在ubuntu 12.10安装vmware-tools出现的“The path "" is not a valid path to linux-headers-3.5.0-17 ...
- IE11下javascript报堆栈溢出问题的解决
在IE11浏览器下,使用日期函数里面的toLocaleDateString()会报堆栈溢出 不知道是不是跟我的其他相关代码有关,还是就是这个toLocaleDateString()在IE11确实不太一 ...
- storm0.9.0.1升级安装
来自:http://blog.csdn.net/liuzhoulong/article/details/21112101 1,下载0.9.0.1 http://storm.incubator.apac ...
- Unix 网络编程 读书笔记3
第四章 基本tcp 套接口编程 注意区分AF_XXX 和PF_XXX,AF代表address family, PF代表protocol family. 1 socket 函数 2 connect 函数 ...