Java使用Redisson分布式锁实现原理
本篇文章摘自:https://www.jb51.net/article/149353.htm
由于时间有限,暂未验证 仅先做记录。有大家注意下哈(会尽快抽时间进行验证)
1. 基本用法
添加依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.8.2</version>
</dependency>
Config config = new Config();
config.useClusterServers()
.setScanInterval(2000) // cluster state scan interval in milliseconds
.addNodeAddress("redis://127.0.0.1:7000", "redis://127.0.0.1:7001")
.addNodeAddress("redis://127.0.0.1:7002"); RedissonClient redisson = Redisson.create(config); RLock lock = redisson.getLock("anyLock"); lock.lock(); try {
...
} finally {
lock.unlock();
}
针对上面这段代码,重点看一下Redisson是如何基于Redis实现分布式锁的
Redisson中提供的加锁的方法有很多,但大致类似,此处只看lock()方法
更多请参见https://github.com/redisson/redisson/wiki/8.-distributed-locks-and-synchronizers
2. 加锁


可以看到,调用getLock()方法后实际返回一个RedissonLock对象,在RedissonLock对象的lock()方法主要调用tryAcquire()方法
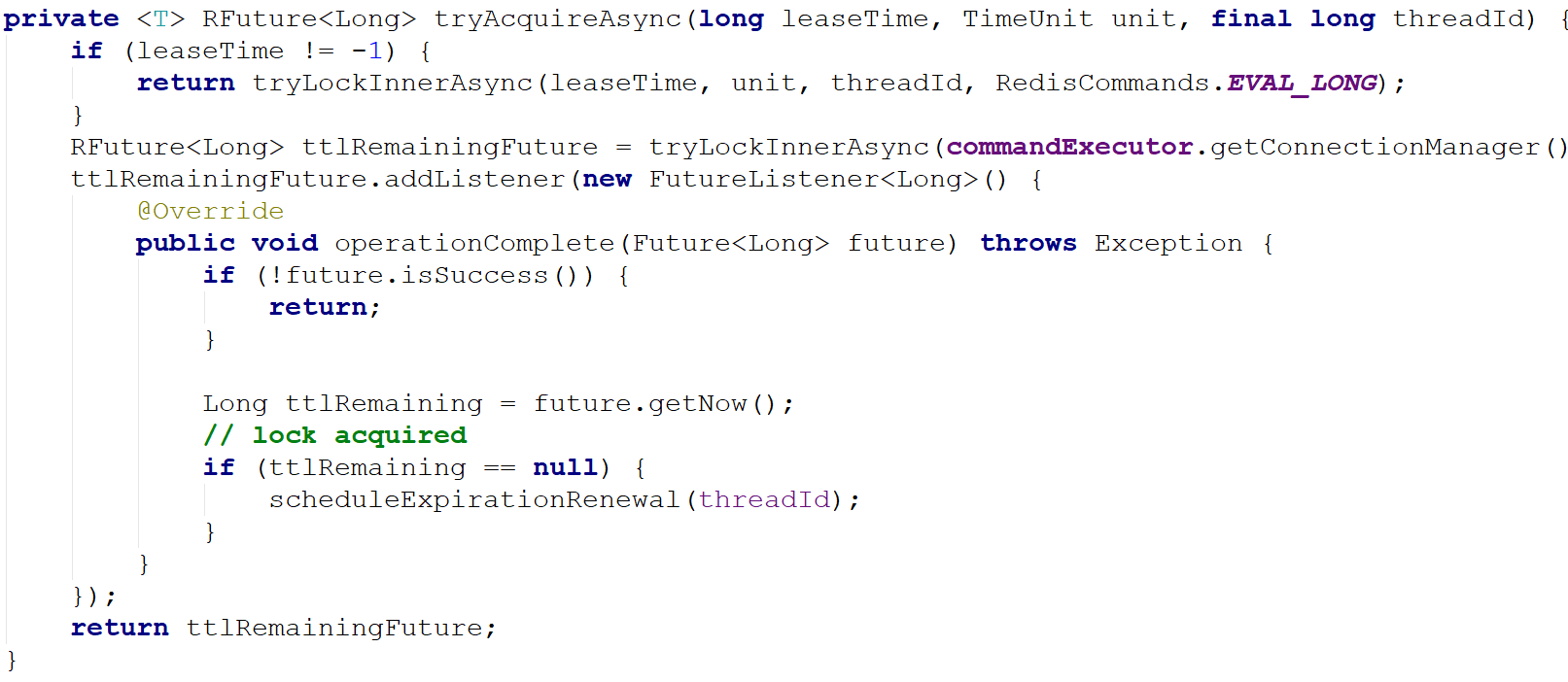
由于leaseTime == -1,于是走tryLockInnerAsync()方法,这个方法才是关键
首先,看一下evalWriteAsync方法的定义
由于leaseTime == -1,于是走tryLockInnerAsync()方法,这个方法才是关键 首先,看一下evalWriteAsync方法的定义
最后两个参数分别是keys和params
实际调用是这样的:

单独将调用的那一段摘出来看
commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
结合上面的参数声明,我们可以知道,这里KEYS[1]就是getName(),ARGV[2]是getLockName(threadId)
假设前面获取锁时传的name是“abc”,假设调用的线程ID是Thread-1,假设成员变量UUID类型的id是6f0829ed-bfd3-4e6f-bba3-6f3d66cd176c
那么KEYS[1]=abc,ARGV[2]=6f0829ed-bfd3-4e6f-bba3-6f3d66cd176c:Thread-1
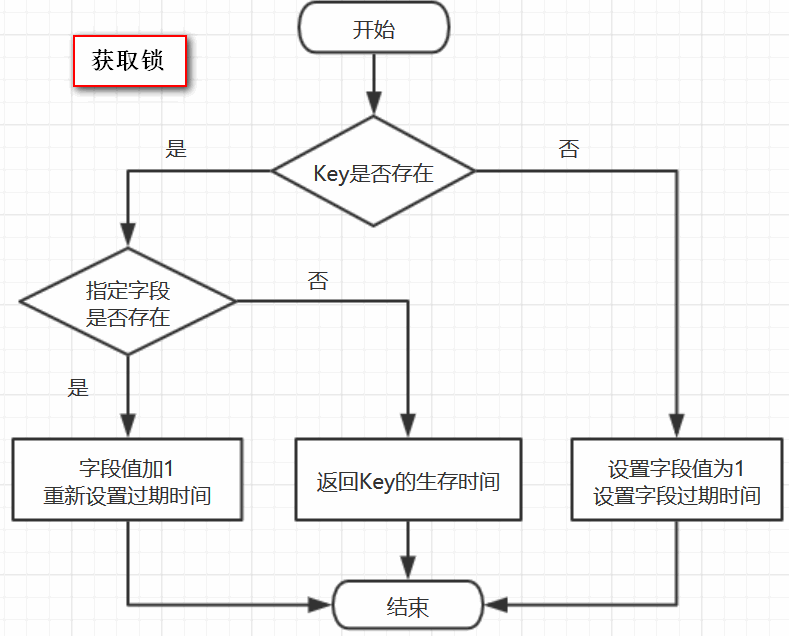
因此,这段脚本的意思是
1、判断有没有一个叫“abc”的key
2、如果没有,则在其下设置一个字段为“6f0829ed-bfd3-4e6f-bba3-6f3d66cd176c:Thread-1”,值为“1”的键值对 ,并设置它的过期时间
3、如果存在,则进一步判断“6f0829ed-bfd3-4e6f-bba3-6f3d66cd176c:Thread-1”是否存在,若存在,则其值加1,并重新设置过期时间
4、返回“abc”的生存时间(毫秒)
这里用的数据结构是hash,hash的结构是: key 字段1 值1 字段2 值2 。。。
用在锁这个场景下,key就表示锁的名称,也可以理解为临界资源,字段就表示当前获得锁的线程
所有竞争这把锁的线程都要判断在这个key下有没有自己线程的字段,如果没有则不能获得锁,如果有,则相当于重入,字段值加1(次数)
3. 解锁
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end;" +
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; "+
"end; " +
"return nil;",
Arrays.<Object>asList(getName(), getChannelName()), LockPubSub.unlockMessage, internalLockLeaseTime, getLockName(threadId));
}
我们还是假设name=abc,假设线程ID是Thread-1
同理,我们可以知道
KEYS[1]是getName(),即KEYS[1]=abc
KEYS[2]是getChannelName(),即KEYS[2]=redisson_lock__channel:{abc}
ARGV[1]是LockPubSub.unlockMessage,即ARGV[1]=0
ARGV[2]是生存时间
ARGV[3]是getLockName(threadId),即ARGV[3]=6f0829ed-bfd3-4e6f-bba3-6f3d66cd176c:Thread-1
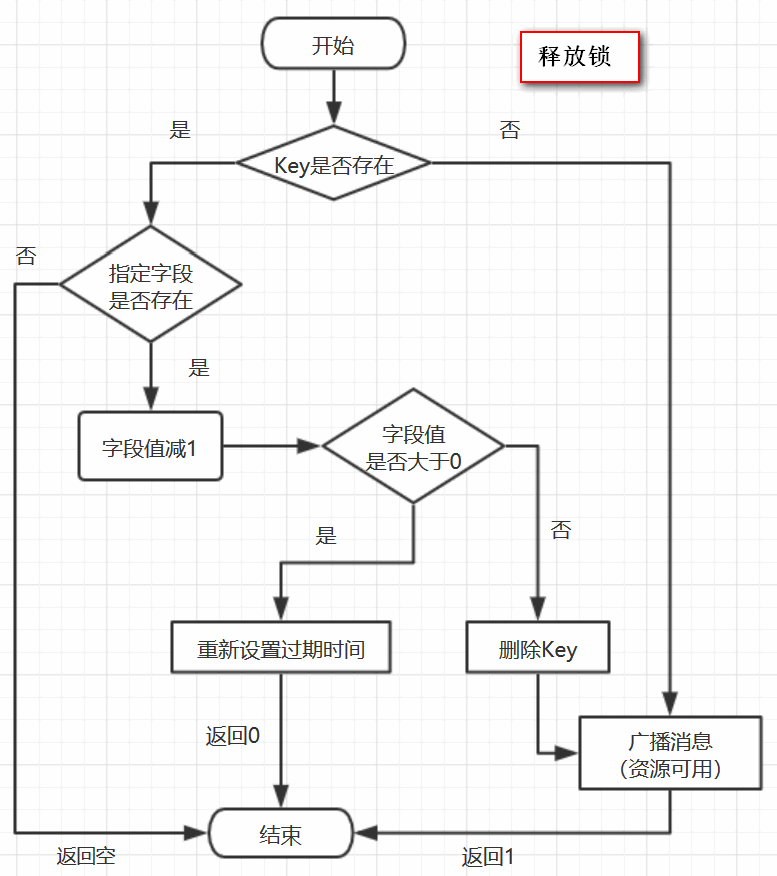
因此,上面脚本的意思是:
1、判断是否存在一个叫“abc”的key
2、如果不存在,向Channel中广播一条消息,广播的内容是0,并返回1
3、如果存在,进一步判断字段6f0829ed-bfd3-4e6f-bba3-6f3d66cd176c:Thread-1是否存在
4、若字段不存在,返回空,若字段存在,则字段值减1
5、若减完以后,字段值仍大于0,则返回0
6、减完后,若字段值小于或等于0,则广播一条消息,广播内容是0,并返回1;
可以猜测,广播0表示资源可用,即通知那些等待获取锁的线程现在可以获得锁了
4. 等待
以上是正常情况下获取到锁的情况,那么当无法立即获取到锁的时候怎么办呢?
再回到前面获取锁的位置
@Override
public void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException {
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return;
}
// 订阅
RFuture<RedissonLockEntry> future = subscribe(threadId);
commandExecutor.syncSubscription(future);
try {
while (true) {
ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
break;
}
// waiting for message
if (ttl >= 0) {
getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
getEntry(threadId).getLatch().acquire();
}
}
} finally {
unsubscribe(future, threadId);
}
// get(lockAsync(leaseTime, unit));
}
protected static final LockPubSub PUBSUB = new LockPubSub();
protected RFuture<RedissonLockEntry> subscribe(long threadId) {
return PUBSUB.subscribe(getEntryName(), getChannelName(), commandExecutor.getConnectionManager().getSubscribeService());
}
protected void unsubscribe(RFuture<RedissonLockEntry> future, long threadId) {
PUBSUB.unsubscribe(future.getNow(), getEntryName(), getChannelName(), commandExecutor.getConnectionManager().getSubscribeService());
}
这里会订阅Channel,当资源可用时可以及时知道,并抢占,防止无效的轮询而浪费资源
当资源可用用的时候,循环去尝试获取锁,由于多个线程同时去竞争资源,所以这里用了信号量,对于同一个资源只允许一个线程获得锁,其它的线程阻塞
5. 小结
6. 其它相关
@感谢原文作者的分享:https://www.jb51.net/article/149353.htm
Java使用Redisson分布式锁实现原理的更多相关文章
- 又长又细,万字长文带你解读Redisson分布式锁的源码
前言 上一篇文章写了Redis分布式锁的原理和缺陷,觉得有些不过瘾,只是简单的介绍了下Redisson这个框架,具体的原理什么的还没说过呢.趁年前项目忙的差不多了,反正闲着也是闲着,不如把Rediss ...
- Redisson实现分布式锁(1)---原理
Redisson实现分布式锁(1)---原理 有关Redisson作为实现分布式锁,总的分3大模块来讲. 1.Redisson实现分布式锁原理 2.Redisson实现分布式锁的源码解析 3.Redi ...
- redisson之分布式锁实现原理(三)
官网:https://github.com/redisson/redisson/wiki/%E7%9B%AE%E5%BD%95 一.什么是分布式锁 1.1.什么是分布式锁 分布式锁,即分布式系统中的锁 ...
- 从源码层面深度剖析Redisson实现分布式锁的原理(全程干货,注意收藏)
Redis实现分布式锁的原理 前面讲了Redis在实际业务场景中的应用,那么下面再来了解一下Redisson功能性场景的应用,也就是大家经常使用的分布式锁的实现场景. 引入redisson依赖 < ...
- Redisson分布式锁实现
转: Redisson分布式锁实现 2018年09月07日 15:30:32 校长我错了 阅读数:3303 转:分布式锁和Redisson实现 概述 分布式系统有一个著名的理论CAP,指在一个分布 ...
- Redisson 分布式锁实战与 watch dog 机制解读
Redisson 分布式锁实战与 watch dog 机制解读 目录 Redisson 分布式锁实战与 watch dog 机制解读 背景 普通的 Redis 分布式锁的缺陷 Redisson 提供的 ...
- Redisson 分布式锁实现之前置篇 → Redis 的发布/订阅 与 Lua
开心一刻 我找了个女朋友,挺丑的那一种,她也知道自己丑,平常都不好意思和我一块出门 昨晚,我带她逛超市,听到有两个人在我们背后小声嘀咕:"看咱前面,想不到这么丑都有人要." 女朋友 ...
- Redisson 分布式锁实现之源码篇 → 为什么推荐用 Redisson 客户端
开心一刻 一男人站在楼顶准备跳楼,楼下有个劝解员拿个喇叭准备劝解 劝解员:兄弟,别跳 跳楼人:我不想活了 劝解员:你想想你媳妇 跳楼人:媳妇跟人跑了 劝解员:你还有兄弟 跳楼人:就是跟我兄弟跑的 劝解 ...
- Redisson分布式锁的简单使用
一:前言 我在实际环境中遇到了这样一种问题,分布式生成id的问题!因为业务逻辑的问题,我有个生成id的方法,是根据业务标识+id当做唯一的值! 而uuid是递增生成的,从1开始一直递增,那么在同一台机 ...
随机推荐
- C#MVC和cropper.js实现剪裁图片ajax上传的弹出层
首先使用cropper.js插件,能够将剪裁后的图片返回为base64编码,后台根据base64编码解析保存图片. jQuery.cropper: 是一款使用简单且功能强大的图片剪裁jquery插件 ...
- linux ab压力测试工具及ab命令详解
原文链接:https://blog.csdn.net/qq_27517377/article/details/78794409 yum -y install httpd-tools ab -v 查看a ...
- OpenSL的代码编写
#include <jni.h>#include <string>#include <SLES/OpenSLES.h>#include <SLES/OpenS ...
- Python 第三方包上传至 PyPI 服务器
PyPI 服务器主要功能是?PyPI 服务器怎么搭建? PyPI 服务器可以用来管理自己开发的 Python 第三包. Pypi服务器搭建 Python 第三方包在本地打包 # 本地目录执行以下命令应 ...
- CSS3的三大特性
在学习CSS 的时候,我们必须要熟练和理解CSS 的三大特性,那么CSS 的三大特性又是什么呢? CSS 的三大特性:层叠 继承 优先级 ,CSS 三大特性是我们学习CSS 必须掌握的三个特性. 首 ...
- SnapKit 类图
 如图上图所示,居于中心的是ConstraintDescription,它用来生成Constraint,最后再转换成系统的NSLayoutConstraint. ConstraintDescript ...
- 大白dmeo (转的)
<!doctype html><html> <head> <meta charset="utf-8"> <title>B ...
- Java之IO(八)PipedIutputStream和PipedOutputStream
转载请注明源出处:http://www.cnblogs.com/lighten/p/7056278.html 1.前言 本章介绍Java的IO体系中最后一对字节流--管道流.之前在字节数组流的时候就说 ...
- LINUX下 一句话添加用户并设置ROOT权限
来源:linux一条命令添加用户并设置密码 linux一条命令添加一个root级别账户并设置密码 LINUX提权,除非是拿的EXP反弹CMD,才会有回显,这样添加管理员方便了. 通常是在SHELL,菜 ...
- Javac语法糖之TryCatchFinally
https://docs.oracle.com/javase/specs/jls/se7/html/jls-14.html#jls-14.20.3 Optionally replace a try s ...