机器学习:KNN-近邻算法
一、理论知识
1、K近邻(k-Nearest Neighbor,简称KNN)学习是一种常用的监督学习。
工作机制:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个的信息来进行预测。且通常使用“投票法”。
2、以电影类型举例,现在已知部分电影的属性和分类,想要预测未知电影的分类。

我们可以计算未知电影和其它电影的属性距离,这里直接采用几何距离(Euclidean Distance),即把每个属性化为不同维度的坐标,再利用距离公式

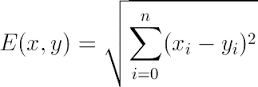
计算结束后,递增排序,可以找到k个最近的样本。因为要采用“投票法”,即满足少数服从多数原则,所以K的取值一般为奇数。这里假设k=3,则最靠近的3个都为爱情电影,所以判断未知电影为爱情电影。

3、KNN算法伪码描述:
(1) 计算已知类别数据集中的点与当前点之间的距离;
(2) 按照距离递增次序排序;
(3) 选取与当前点距离最小的k个点;
(4) 确定前k个点所在类别的出现频率;
(5) 返回前k个点出现频率最高的类别作为当前点的预测分类
4、优点:简单;易于理解;通过对K的选择可具备丢噪音数据的健壮性
缺点:(1)需要大量空间储存所有已知实例
(2)算法执行效率低(需要比较所有已知实例与要分类的实例)
(3)当其样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例并未接近目标样本。
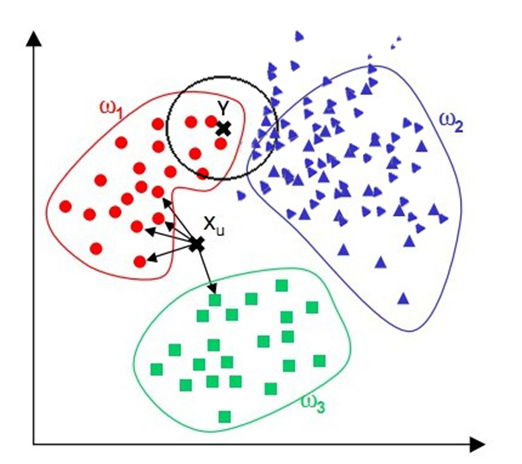
缺点(3)的意思是,如图中的Y点,黑圈代表其k的取值,即黑圈内的点都是要进行投票的数据点。通过观察会发现Y显然与红点更近,然而因为紫色点在这个圈里数目更多,Y点就会被认为是紫色。对于这个缺点,通常我们用权重的方法改善,根据距离d改变权重,例如1/d,这样就能让离目标点近的数据点的权重更大一点,优化算法。
二、代码实现
调用sklearn库中KNN算法分析著名的iris数据
from sklearn import neighbors
from sklearn import datasets knn = neighbors.KNeighborsClassifier()
iris = datasets.load_iris() knn.fit(iris.data, iris.target) # 建立KNN模型,输入特征值和分类结果
predictedLabel = knn.predict([[6.3, 1.2, 5.2, 1.6]]) print("predictedLabel is :"+ str(predictedLabel))
predictedLabel is :[1]
有现成的库调用起来很方便,当然也可以自己写对应的算法,下面是KNN的算法。
def classify0(inX, dataSet, labels, k): # KNN算法
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet #计算两个点的空间距离
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k): #选择距离最小的k个点
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) # 按照第二个元素进行从小到大排序,最后返回发生频率最高的标签
return sortedClassCount[0][0]
三、参考资料
《机器学习》—— 周志华
《机器学习实战》—— Peter Harrington
ps:本人初学者,有错误欢迎指出。感谢。
机器学习:KNN-近邻算法的更多相关文章
- 机器学习之利用KNN近邻算法预测数据
前半部分是简介, 后半部分是案例 KNN近邻算法: 简单说就是采用测量不同特征值之间的距离方法进行分类(k-Nearest Neighbor,KNN) 优点: 精度高.对异常值不敏感.无数据输入假定 ...
- KNN近邻算法
K近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表.kNN算法的核 ...
- 机器学习入门KNN近邻算法(一)
1 机器学习处理流程: 2 机器学习分类: 有监督学习 主要用于决策支持,它利用有标识的历史数据进行训练,以实现对新数据的表示的预测 1 分类 分类计数预测的数据对象是离散的.如短信是否为垃圾短信,用 ...
- 机器学习之近邻算法模型(KNN)
1..导引 如何进行电影分类 众所周知,电影可以按照题材分类,然而题材本身是如何定义的?由谁来判定某部电影属于哪 个题材?也就是说同一题材的电影具有哪些公共特征?这些都是在进行电影分类时必须要考虑的问 ...
- [机器学习] k近邻算法
算是机器学习中最简单的算法了,顾名思义是看k个近邻的类别,测试点的类别判断为k近邻里某一类点最多的,少数服从多数,要点摘录: 1. 关键参数:k值 && 距离计算方式 &&am ...
- Python3入门机器学习 - k近邻算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 【udacity】机器学习-knn最近邻算法
Evernote Export 1.基于实例的学习介绍 不同级别的学习,去除所有的数据点(xi,yi),然后放入一个数据库中,下次直接提取数据 但是这样的实现方法将不能进行泛化,这种方式只能简单的 ...
- 机器学习(1)——K近邻算法
KNN的函数写法 import numpy as np from math import sqrt from collections import Counter def KNN_classify(k ...
- 1.K近邻算法
(一)K近邻算法基础 K近邻(KNN)算法优点 思想极度简单 应用数学知识少(近乎为0) 效果好 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 图解K近邻算法 上图是以 ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
随机推荐
- 100baseT、100baseFX、1000base-SX、100/1000base-T
100baseT.100baseFX.1000base-SX.100/1000base-T 100baseT.100baseFX都是100Mbps速率基带传输系统,唯一的不同是100baseT用的是双 ...
- 【BearChild】
\(≧▽≦)/ BearChild is salty. If you want to save him,please call QQ:423339833 to talk♂with him. Have ...
- POJ 3164 Command Network ( 最小树形图 朱刘算法)
题目链接 Description After a long lasting war on words, a war on arms finally breaks out between littlek ...
- 阿里云mysql数据库设置让公网访问客户端访问
第一步 首先使用root登入你的mysql ./mysql -u root -p 你的密码 第二步 备注:也可以添加一个用户名为yuancheng,密码为123456,权限为%(表示任意ip都能连接) ...
- 免費域名申請.me .im .in .co .la .do .ms .kz .tk .ru .mu .pn .tt
免費申請域名 .la .la 域名 – 原先是ICANN分配給老撾的國家頂級域名,不過後來被同時作為了美國洛杉矶市的域名後綴. 免費申請地址: http://www.idv.la http://www ...
- Linux/Unix系统编程手册 第一章:历史和标准
Unix的开发不受控于某一个厂商或者组织,是由诸多商业和非商业团体共同贡献进行演化的.这导致两个结果:一是Unix集多种特性于一身,二是由于参与者众多,随着时间推移,Unix实现方式逐渐趋于分裂. 由 ...
- Android平台介绍
一.Android平台介绍 什么是智能手机 具有独立的操作系统,独立的运行空间,可以由用户自行安装软件.游戏.导航等第三方应用程序,并可以通过移动通讯网络来实现无线网络接入的手机类型总称. 智能手机操 ...
- web项目打包后在代码中获取资源文件
在web项目里面,有时代码里面需要引用一些自定义的配置文件,这些配置文件如果放在类路径下,项目经过打包后使用的相对路径也会发生变化,所以以下给出了三种解决方案. 一.properties下配置 在类路 ...
- Spiral Matrix I & II
Spiral Matrix I Given an integer n, generate a square matrix filled with elements from 1 to n^2 in s ...
- USB descriptor【转】
struct usb_device_descriptor { __u8 bLength;//设备描述符的字节数大小,为0x12 __u8 bDescriptorType;//描述符类型编号,为0x01 ...