3、计数排序,电影top100
1、计数排序



# -*- coding: utf-8 -*-
# @Time : 2018/07/31 0031 11:32
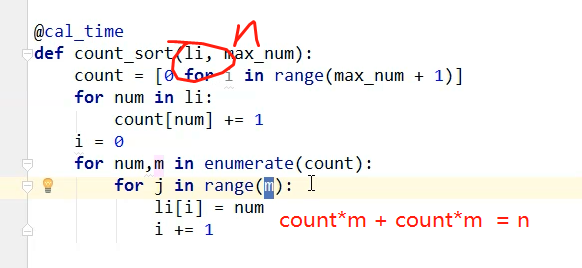
# @Author : Venicid def count_sort(li, max_num):
count = [0 for i in range(max_num + 1)]
for num in li:
count[num] += 1
i = 0
for num, m in enumerate(count):
for j in range(m):
li[i] = num
i += 1 import random
data = []
for i in range(100000):
data.append(random.randint(0,100)) count_sort(data, 100)
print(data)
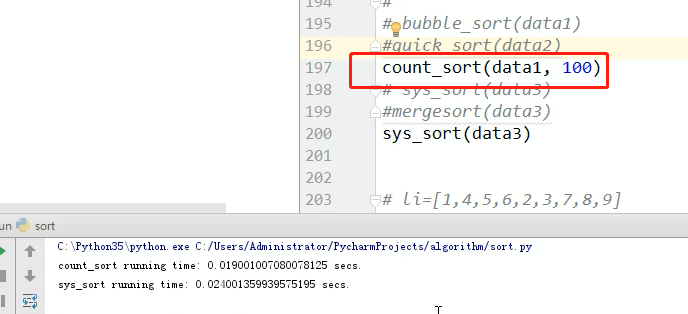
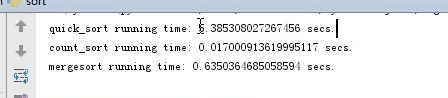
计数排序这么快,为什么不用计数排序呢?因为他是有限制的,你要知道列表中的最大数
如果一下来了一个很大的数,比如10000,那么占的空间就的这么大,
计数排序占用的空间和列表的范围有关系
解决这种问题的方法,可以用桶排序,都放进去可以在进行其他的排序。比如插入排序。
2、TOP10榜单:topk

(1)方式1:思路:插入排序 O(kn)
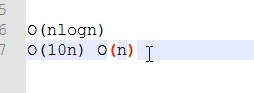







# -*- coding: utf-8 -*-
# @Time : 2018/07/31 0031 11:59
# @Author : Venicid def insert(li, i):
"""一次insert"""
tmp = li[i]
j = i - 1
while j >= 0 and li[j] > tmp:
li[j + 1] = li[j]
j = j - 1
li[j + 1] = tmp def insert_sort(li):
for i in range(1, len(li)): # 从第二个位置,即下标为1的元素开始向前插入
insert(li,i) def topk(li, k):
top = li[0:k + 1] # top10, 多开辟一个存放,新进来的数据
insert_sort(top)
for i in range(k + 1, len(li)):
top[k] = li[i]
insert(top, k)
return top[:-1] # 去掉最后一个 import random
data = list(range(20))
topk_ = random.shuffle(data)
print(data) print(topk(data, 10))

(2)方式2:堆的应用:nlogk

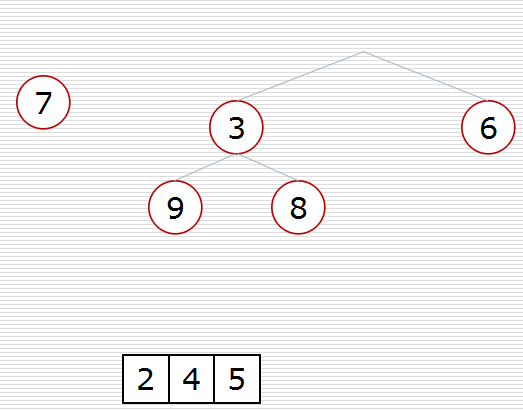
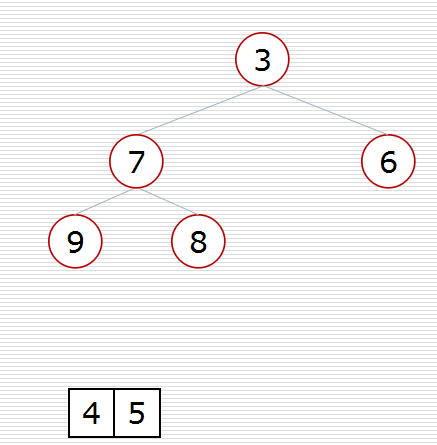
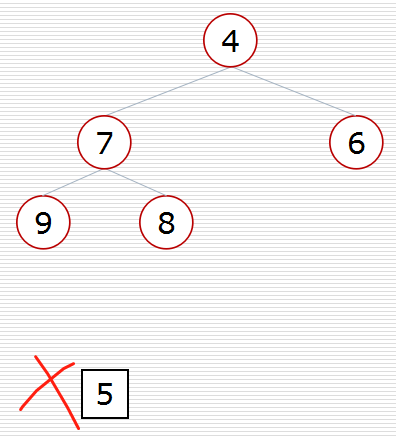
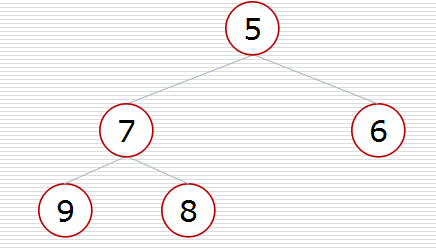
def sift(data, low, high):
"""调整"""
i = low # 父亲的位置
j = 2 * i + 1 # 孩子的位置
tmp = data[i] # 原省长退休
while j <= high: # 孩子在堆里
if j + 1 <= high and data[j] < data[j + 1]: # if右孩子存在且右孩子更大
# if j + 1 <= high and data[j] > data[j + 1]: # if右孩子存在且右孩子更大
j += 1
if data[j] > tmp: # 孩子比最高领导大
# if data[j] < tmp: # 孩子比最高领导大
data[i] = data[j] # 孩子上移一层
i = j # 孩子成为新父亲
j = 2 * i + 1 # 新孩子
else:
break
data[i] = tmp # 省长放到对应的位置上(村民/叶子节点) def topn(li, n):
heap = li[0:n]
# 建堆
for i in range(n // 2 - 1, -1, -1):
sift(heap, i, n - 1) # 遍历
for i in range(n, len(li)):
if li[i] < heap[0]:
# if li[i] > heap[0]:
heap[0] = li[i]
sift(heap, 0, n - 1)
for i in range(n - 1, -1, -1): # i指向堆的最后
heap[0], heap[i] = heap[i], heap[0] # 领导退休,刁民上位
sift(heap, 0, i - 1) # 调整出新领导
return heap import random data = list(range(20))
topk_ = random.shuffle(data)
print(data) print(topn(data, 10))

3、heapq实现堆排序


python官方文档
https://docs.python.org/3/library/index.html



# -*- coding: utf-8 -*-
# @Time : 2018/07/31 0031 15:07
# @Author : Venicid import heapq
import random h = []
data = list(range(10000))
random.shuffle(data)
# heapq.heappush(h,1) # [1] # 生成小栈堆
for num in data:
heapq.heappush(h, num)
print(h) #[0, 1, 2, 4, 3, 5, 7, 8, 6, 17, # 出数
for i in range(len(h)):
print(heapq.heappop(h)) # top最大 top最小的
print(heapq.nsmallest(10, data))
print(heapq.nlargest(10, data))


3、计数排序,电影top100的更多相关文章
- requests+正则表达式提取猫眼电影top100
#requests+正则表达式提取猫眼电影top100 import requests import re import json from requests.exceptions import Re ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 计数排序(counting-sort)——算法导论(9)
1. 比较排序算法的下界 (1) 比较排序 到目前为止,我们已经介绍了几种能在O(nlgn)时间内排序n个数的算法:归并排序和堆排序达到了最坏情况下的上界:快速排序在平均情况下达到该上界. ...
- 计数排序和桶排序(Java实现)
目录 比较和非比较的区别 计数排序 计数排序适用数据范围 过程分析 桶排序 网络流传桶排序算法勘误 桶排序适用数据范围 过程分析 比较和非比较的区别 常见的快速排序.归并排序.堆排序.冒泡排序等属于比 ...
- CF 375B Maximum Submatrix 2[预处理 计数排序]
B. Maximum Submatrix 2 time limit per test 2 seconds memory limit per test 512 megabytes input stand ...
- 计数排序-java
今天看了一本书,书里有道题,题目很常见,排序,明了点说: 需求:输入:最多有n个正整数,每个数都小于n, n为107 ,没有重复的整数 输出:按升序排列 思路:假设有一组集合 {1,3,5,6,11, ...
- 计数排序 + 线段树优化 --- Codeforces 558E : A Simple Task
E. A Simple Task Problem's Link: http://codeforces.com/problemset/problem/558/E Mean: 给定一个字符串,有q次操作, ...
- 计数排序算法——时间复杂度O(n+k)
计数排序 计数排序是一个非基于比较的排序算法,该算法于1954年由 Harold H. Seward 提出.它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于 ...
随机推荐
- 【Redis】命令学习笔记——键(key)(20个超全字典版)
安装完redis和redis-desktop-manager后,开始学习命令啦!本篇基于redis 4.0.11版本,从对键(key)开始挖坑! 准备工作,使用db1(默认db0,由于之前练习用db0 ...
- JS获取长度方法总结
目录: 1length 2size() 3length与size()的区别 4获取元素的索引 - index() 5获取对应的索引 - eq() 概述: 在工作中大家经常需要获取对象的长度,或者要获取 ...
- Linux man 命令详细介绍
知道linux帮助文件(man-pages,手册页)一般放在,$MANPATH/man 目录下面,而且按照领域与语言放到不同的目录里面. 看了上一章,要找那个命令使用相关手册,只要我们按照领域区分,到 ...
- .NET Reflector注册机激活方法
.NET Reflector注册机是一款专门针对.NET Reflector(.NET反编译工具软件)而推出的一款破解辅助工具软件.因为官方破解版软件需要118美元才能用,不然只有14天的试用期,为此 ...
- 如何创建一个Quartz.NET的工作,需要注射autofac
问题: 使用 Quartz.Net 做定时任务时,实现IJob对象的服务,Autofac不会自动注入,使用构造函数会直接出现异常,无法执行Execute方法. 解决方式 方法一: 使用 Autofac ...
- print(dir(...)) 打印对象或者类中的方法和函数
- 转 oracle的热备份和冷备份
一.冷备份介绍: 冷备份数据库是将数据库关闭之后备份所有的关键性文件包括数据文件.控制文件.联机REDO LOG文件,将其拷贝到另外的位置.此外冷备份也可以包含对参数文件和口令文件的备份,但是这 ...
- ubuntu 12.04配置mac的Lion主题的风格
1.下载mac壁纸 http://drive.noobslab.com/data/wallpapers/Mac-os-x-Wallpapers%28NoobsLab.com%29.zip 根据自己喜好 ...
- 有料面试题之--Object里面的方法
阿里的面试题里面有个题很奇妙:你知道Object类里面有哪些方法吗? 绝大部分猿类都知道 有hashcode .equals .clone.toString 只有部分人会回答有 wait和notify ...
- 4719: [Noip2016]天天爱跑步
Time Limit: 40 Sec Memory Limit: 512 MB Submit: 1986 Solved: 752 [Submit][Status][Discuss] Descripti ...