spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)
问题
datafrme提供了强大的JOIN操作,但是在操作的时候,经常发现会碰到重复列的问题。在你不注意的时候,去用相关列做其他操作的时候,就会出现问题!
假如这两个字段同时存在,那么就会报错,如下:org.apache.spark.sql.AnalysisException: Reference 'key2' is ambiguous
实例
1.创建两个df演示实例
val df = sc.parallelize(Array(
("yuwen", "zhangsan", 80), ("yuwen", "lisi", 90), ("shuxue", "zhangsan", 90), ("shuxue", "lisi", 95)
)).toDF("course", "name", "score")
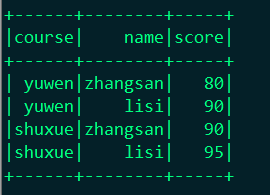
显示:df.show()
val df2 = sc.parallelize(Array(
("yuwen", "zhangsan", 90), ("shuxue", "zhangsan", 100)
)).toDF("course", "name", "score")
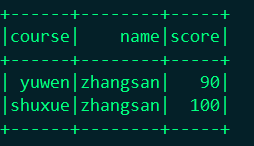
显示:df2.show
关联查询:
val joined = df.join(df2, df("cource") === df2("cource") && df("name") === df2("name"), "left_outer")
结果展示:

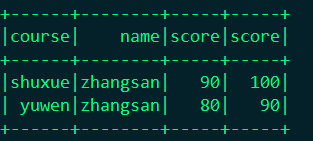
这时候问题出现了这个地方出现了三个两两相同的字段,当你在次操作这个字段的时候就出问题了。

解决问题
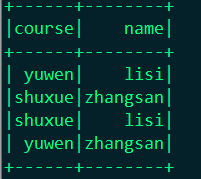
1.你可以使用的时候指定你要用哪个df里面的字段
joined.select(df("course"),df("name")).show
结果:
2.你可以删除多余的列,在实际情况中你不可能将两张完全一样的表进行关联,一般就几个字段的名字相同,这样你可以删除你不需要的字段
joined.drop(df2("name"))
结果:

3.就是通过修改JOIN的表达式,完全可以避免这个问题。主要是通过Seq这个对象来实现
df.join(df2, Seq("course", "name")).show()
结果:
spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)的更多相关文章
- spark org.apache.spark.ml.linalg.DenseVector cannot be cast to org.apache.spark.ml.linalg.SparseVector
在使用 import org.apache.spark.ml.feature.VectorAssembler 转换特征后,想要放入 import org.apache.spark.mllib.clas ...
- 【原创】大数据基础之Spark(8)Spark中Join实现原理
spark中join有两种,一种是RDD的join,一种是sql中的join,分别来看: 1 RDD join org.apache.spark.rdd.PairRDDFunctions /** * ...
- Spark之join、leftOuterJoin、rightOuterJoin及fullOuterJoin
Spark的join与mysql的join类似,mysql的join是将表与表之间连接查询,spark中join是将RDD数据集进行连接,Spark主要有join.leftOuterJoin.righ ...
- Apache Spark 2.2.0 中文文档
Apache Spark 2.2.0 中文文档 - 快速入门 | ApacheCN Geekhoo 关注 2017.09.20 13:55* 字数 2062 阅读 13评论 0喜欢 1 快速入门 使用 ...
- Apache Spark 2.2.0 中文文档 - Spark 编程指南 | ApacheCN
Spark 编程指南 概述 Spark 依赖 初始化 Spark 使用 Shell 弹性分布式数据集 (RDDs) 并行集合 外部 Datasets(数据集) RDD 操作 基础 传递 Functio ...
- 新手福利:Apache Spark入门攻略
[编者按]时至今日,Spark已成为大数据领域最火的一个开源项目,具备高性能.易于使用等特性.然而作为一个年轻的开源项目,其使用上存在的挑战亦不可为不大,这里为大家分享SciSpike软件架构师Ash ...
- Apache Spark 2.0三种API的传说:RDD、DataFrame和Dataset
Apache Spark吸引广大社区开发者的一个重要原因是:Apache Spark提供极其简单.易用的APIs,支持跨多种语言(比如:Scala.Java.Python和R)来操作大数据. 本文主要 ...
- [错误]Caused by: org.apache.spark.memory.SparkOutOfMemoryError: Unable to acquire 65536 bytes of memory, got 0
今天,在运行Spark SQL代码的时候,遇到了以下错误: Caused by: org.apache.spark.SparkException: Job aborted due to stage f ...
- Apache Spark大数据分析入门(一)
摘要:Apache Spark的出现让普通人也具备了大数据及实时数据分析能力.鉴于此,本文通过动手实战操作演示带领大家快速地入门学习Spark.本文是Apache Spark入门系列教程(共四部分)的 ...
随机推荐
- MySQL [Err]1449 : The user specified as a definer ('root'@'%') does not exist
权限问题:授权 给 root 所有sql 权限 mysql> grant all privileges on *.* to root@"%" identified by &q ...
- gradlew assembleRelease打包之前的配置
http://blog.csdn.net/qq_15527709/article/details/70146061
- 从头认识java-18.2 主要的线程机制(2)-Executors的使用
在前面的章节我们都是直接对Thread进行管理,我们这里解释一下还有一个管理Thread的类Executors. 1.样例: package com.ray.ch17; import java.uti ...
- Proxool线程池的简单实现demo
使用的jar包:ojdbc14.jar proxool-0.9.0.jar commons-logging-1.1.3.jar 代码分为两部分: ProxoolTest.java和proxo ...
- java框架---->RxJava的使用(一)
RxJava是响应式程序设计的一种实现.在响应式程序设计中,当数据到达的时候,消费者做出响应.响应式编程可以将事件传递给注册了的observer.今天我们就来学习一下rxJava,并分析一下它源码感受 ...
- tomcat自动加载class
转载 tomcat自动加载改变的class文件(无需重启tomcat) http://blog.csdn.net/miraclestar/article/details/6434164 不重启Tom ...
- python3 + selenium + (chrome and firefox)使用
目录 瞎扯一句 简介 最后放模板 瞎扯一句 最近在做一个关于 selenium 相关的项目,在选择浏览器方面,一般有3种方案: chrome phantomJs firefox(推荐) 网上有很多教程 ...
- 160516、redis安装(linux+windows)
1.windows中redis安装使用 第一步:下载windows版本的redis这里redis_win.zip并解压,加压后目录中有下面的文件 redis-server.exe redis服务端 ...
- ThreadLocal分析总结:
1.ThreadLocal 是什么 它是一个数据结构,像 HashMap,可保存 "key : value" 键值对:ThreadLocal 有一个内部类ThreadLocalMa ...
- Java switch 详解
switch 语句由一个控制表达式和多个case标签组成. switch 控制表达式支持的类型有byte.short.char.int.enum(Java 5).String(Java 7). swi ...