04_Storm编程上手_WordCount集群模式运行
1. 要解决的问题:代码打包
前一篇的代码,在IDEA中通过maven工程创建,通过IDEA完成代码打包
1)File -> Project Structure
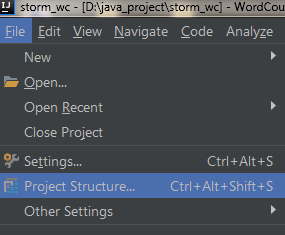
2) 选择Artifacts, 并点击加号进行新建

3)选择JAR,并根据module依赖关系进行
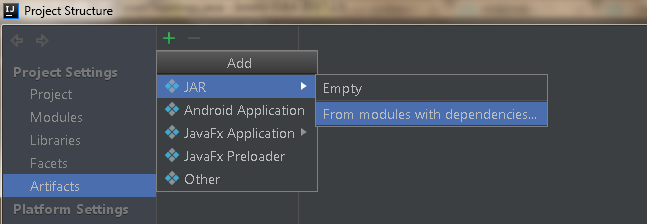
4)选择 主类,并设置Manifest文件创建在target\classes文件夹下(manifest文件主要是说明哪一个class是主类,class在哪些第三方依赖包内)
5) 根据需要,将必要的第三方依赖包加入(由于是要上传到集群,而storm相关的class文件,集群中已经具备,因此并不不要额外添加依赖包),下图演示的是需要将第三方依赖包加入的配置结果
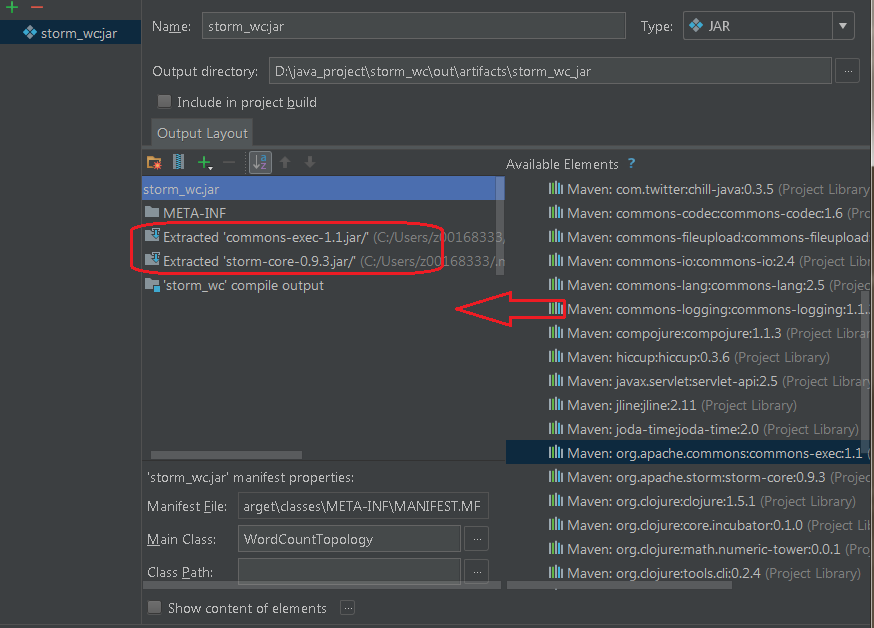
6) 选择Build->Build Artifacts
在弹出的小窗口中,确认选择Build

7)Build完成后,IDEA下方的Event log会给出完成提示
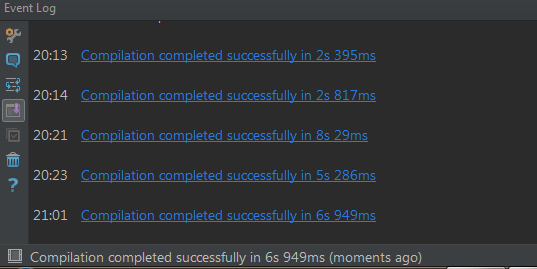
8)项目所在目录,此时会出现1个out目录

进入该目录,并一路向下,就会看到最终打包完成的JAR包

2. 打包代码上传集群
1)在主节点上创建1个目录,放置打包后的JAR文件
以我的为例,JAR文件将放置在/usr/local/src/package目录下,通过winscp或者其他FTP工具将打包好的JAR文件放入即可
2)在主节点通过storm jar命令提交拓扑任务
WordCountTopology是代码主类,其中含有main函数并在函数中定义了Topology, WordCount是输入参数,用于给Topology任务取名

3)等待终端提交任务,通过如下的信息提示可以确认Topology任务已经成功提交

4)通过storm UI查看Topology任务运行情况(http://master:8080)
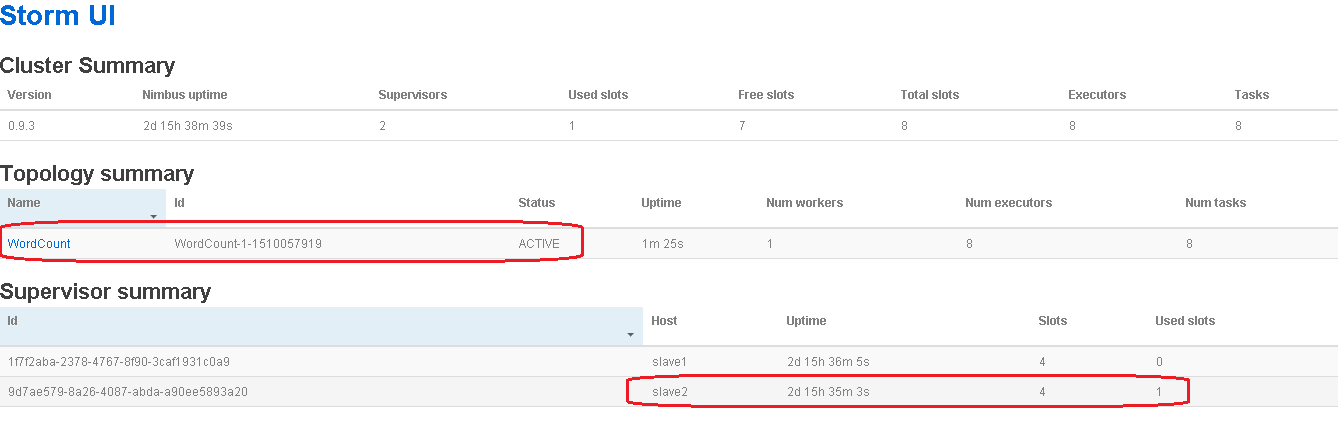
Topology可视化查看各个组件

5)从Topology任务的概况可以看到只有1个worker进程,位于slave2,通过slave2机器上storm安装目录下logs目录中的worker进程日志,可以看到实时输出
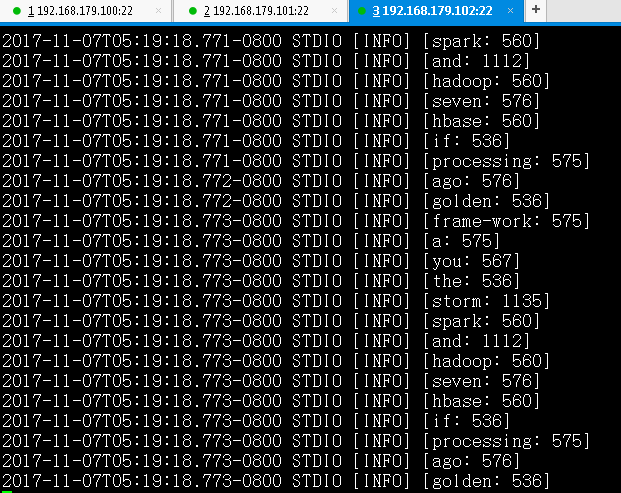
注意:putBolt类中最终输出结果,是通过System.out.println()打印结果到终端,在集群行运行时该输出会重定向到worker进程日志

通过 tail -f worker-6703.log 来实时观察Topology任务的实时输出
04_Storm编程上手_WordCount集群模式运行的更多相关文章
- 【原】简述使用spark集群模式运行程序
本文前提是已经正确安装好scala,sbt以及spark了 简述将程序挂载到集群上运行的步骤: 1.构建sbt标准的项目工程结构: 其中: ~/build.sbt文件用来配置项目的基本信息(项目名 ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- Centos7安装Nacos单机模式以及集群模式(包含nignx安装以及实现集群)的相关配置
Nacos 致力于帮助您发现.配置和管理微服务.Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现.服务配置.服务元数据及流量管理. Nacos支持三种部署模式 单机模式 - 用于测试 ...
- 012 Spark在IDEA中打jar包,并在集群上运行(包括local模式,standalone模式,yarn模式的集群运行)
一:打包成jar 1.修改代码 2.使用maven打包 但是目录中有中文,会出现打包错误 3.第二种方式 4.下一步 5.下一步 6.下一步 7.下一步 8.下一步 9.完成 二:在集群上运行(loc ...
- MapReduce编程入门实例之WordCount:分别在Eclipse和Hadoop集群上运行
上一篇博文如何在Eclipse下搭建Hadoop开发环境,今天给大家介绍一下如何分别分别在Eclipse和Hadoop集群上运行我们的MapReduce程序! 1. 在Eclipse环境下运行MapR ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: Eclipse的下载 Eclipse的安装 Eclipse的使用 本地模式或集群模式 Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群 ...
- IntelliJ IDEA的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: IntelliJ IDEA的下载 IntelliJ IDEA的安装 IntelliJ IDEA中的scala插件安装 用SBT方式来创建工程 或 选择Scala方式来创建工程 本地模式或集群 ...
随机推荐
- react 组件积累
material-ui material-table ant-design https://ant.design/docs/react/getting-started-cn 定义组件(注意,组件的名称 ...
- 基于Maven的SSM框架搭建
Maven + Spring + Spring MVC + Mybatis + MySQL整合SSM框架 1.数据库准备 本文主要想实现SSM框架的搭建,并基于该框架实现简单的登录功能,那么先新建一张 ...
- git本地与远程分支
已经有远程分支,在本地检出,并且关联到远程分支 git checkout --trach origin/远程分支名 git checkout -b 本地分支名 origin/远程分支名 $ git ...
- ui-select : There is no "X"(delete button) with selectize theme, when allow-clear="true"
but add allow-clear="true"For Bootstrap and Select2 themes, it's working perfectly. reason ...
- Spark的Driver节点和Executor节点
转载自:http://blog.sina.com.cn/s/blog_15fc03d810102wto0.html 1.驱动器节点(Driver) Spark的驱动器是执行开发程序中的 main方法的 ...
- Spring框架第三篇之基于XML的DI注入
一.注入分类 Bean实例在调用无参构造器创建空值对象后,就要对Bean对象的属性进行初始化.初始化是由容器自动完成的,称为注入.根据注入方式的不同,常用的有两类:设值注入.构造注入.实现特定接口注入 ...
- mysql lock
http://blog.chinaunix.net/uid-21505614-id-289450.html http://bbs.csdn.net/topics/340127237 http://ww ...
- 支持向量机SVM、优化问题、核函数
1.介绍 它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解. 2.求解过程 1.数据分类—SVM引入 ...
- codeforces 70 D. Professor's task 动态凸包
地址:http://codeforces.com/problemset/problem/70/D 题目: D. Professor's task time limit per test 1 secon ...
- Hibernate与autoCommit
JDBC 的autoCommit属性 对于每一个 JDBC connection,都有一个autoCommit属性,只有执行commit后,该connection中的操作(statement操作)才会 ...