memcached整理の分布式集群算法
memcached如何实现分布式?
memcached是一个“分布式内存对象缓存系统”,然而memcached并不像mongodb那样,允许配置多个节点,且节点之间“自动分配数据”,就是说memcached节点之间是不能互相通信的,因此,memcached的分布式,要靠用户去设计算法,把数据分布在多个memcached节点中。
分布式之取模算法
N个节点,从节点0到节点N-1。key对N取模,余i,则key落在第i台服务器上。
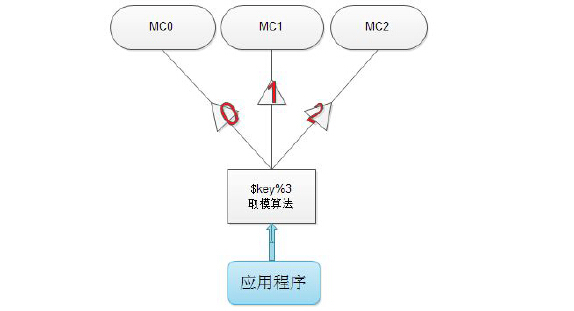
取模算法对缓存命中率的影响
假设有N台服务器,运行中突然down掉一台,那么取模的底数就变为了N-1
后果是什么呢?
后果是命中率在服务器down期间内,急剧下降至1/N-1;服务器越多,则down机后果越严重。
一致性哈希算法原理
把各服务器节点映射放在钟表的各个时刻上, 把key 也映射到钟表的某个时刻上。该key 沿钟表顺时针走,碰到的第1 个节点即为该key 的存储节点。
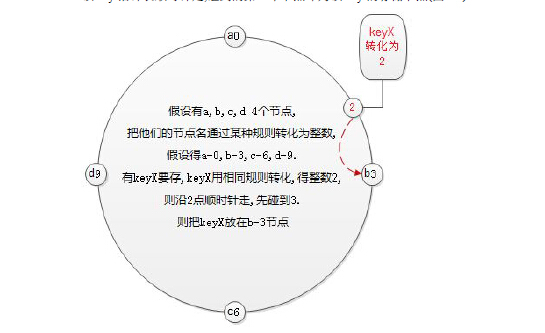
一致性哈希对其他节点的影响
当某个节点down 后,只影响该节点顺时针之后的1 个节点,而其他节点不受影响.因此,Consistent Hashing 最大限度地抑制了键的重新分布。
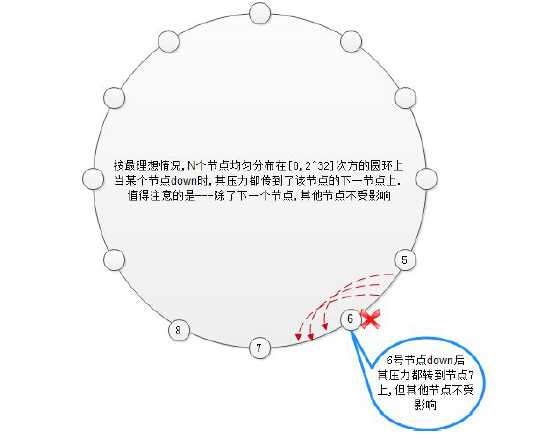
一致性哈希+虚拟节点对缓存命中率的影响
节点在圆环上分配分配均匀,因此承担的任务也平均,但事实上, 一般的Hash 函数对于节点在圆环上的映射,并不均匀。当某个节点down 后,直接冲击下1 个节点,对下1 个节点冲击过大,能否把down 节点上的压力平均的分担到所有节点上?答案是可以的。
引入虚拟节点
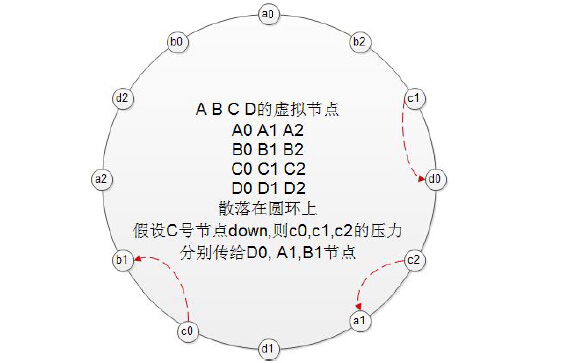
虚拟节点即----N 个真实节点,把每个真实节点映射成M 个虚拟节点, 再把M*N 个虚拟节点,散列在圆环上. 各真实节点对应的虚拟节点相互交错分布这样,某真实节点down 后,则把其影响平均分担到其他所有节点上。
memcached整理の分布式集群算法的更多相关文章
- 分布式集群算法 memcached 如何实现分布式?
memcached 是一个”分布式缓存”,然后 memcached 并不像 mongoDB 那 样,允许配置多个节点,且节点之间”自动分配数据”. 就是说--memcached 节点之间,是不互相通信 ...
- Memcached 服务分布式集群如何实现?
特殊说明:Memcached 集群和 web 服务集群是不一样的,所有 Memcached 的数据总和才是数据库的数据.每台 Memcached 都是部分数据.(一台 memcached 的数据,就是 ...
- Redis面试题及分布式集群
Reference: http://blog.csdn.net/yajlv/article/details/73467865 1. 使用Redis有哪些好处? (1) 速度快,因为数据存在内存中,类似 ...
- Redis分布式集群几点说道
原文地址:http://www.cnblogs.com/verrion/p/redis_structure_type_selection.html Redis分布式集群几点说道 Redis数据量日益 ...
- redis高可用分布式集群
一,高可用 高可用(High Availability),是当一台服务器停止服务后,对于业务及用户毫无影响. 停止服务的原因可能由于网卡.路由器.机房.CPU负载过高.内存溢出.自然灾害等不可预期的原 ...
- elasticsearch 口水篇(5)es分布式集群初探
es有很多特性,分布式.副本集.负载均衡.容灾等. 我们先搭建一个很简单的分布式集群(伪),在同一机器上配置三个es,配置分别如下: cluster.name: foxCluster node.nam ...
- 在Hadoop1.2.1分布式集群环境下安装hive0.12
在Hadoop1.2.1分布式集群环境下安装hive0.12 ● 前言: 1. 大家最好通读一遍过后,在理解的基础上再按照步骤搭建. 2. 之前写过两篇<<在VMware下安装Ubuntu ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- Twemproxy 分布式集群缓存代理服务器
Twemproxy 分布式集群缓存代理服务器 是一个使用C语言编写.以代理的方式实现的.轻量级的Redis代理服务器, 它通过引入一个代理层,将应用程序后端的多台Redis实例进行统一管理, 使 应用 ...
随机推荐
- python开发_function annotations
在看python的API的时候,发现了一个有趣的东东,即:python的方法(函数)注解(Function Annotation) 原文: 4.7.7. Function Annotations Fu ...
- **解释器全局锁(Global Interpreter Lock)
解释器全局锁(Global Interpreter Lock),即Python为了保证线程安全而采取的独立线程运行的限制,说白了就是一个核只能在同一时间运行一个线程. [解决办法就是多进程和协程(协程 ...
- 【299】◀▶ IDL - LIST 函数
list 函数用来创建一个新的 list.list 可以包含不同的数据类型,包括数据.数组.结构体.指针.对象以及其他的 list 或者 哈希表. 序号 类名称 功能说明 语法 & 举 ...
- Elasticsearch-PHP 搜索操作
搜索操作 好吧,这不叫elasticsearch的不劳而获!让我们来谈谈PHP客户端中的搜索操作. 客户端允许你通过REST API访问所有的查询和公开的参数,尽可能的遵循命名规则.让我们来看一些例子 ...
- java 整数存储为2进制补码形式
今天早上看java的源代码,发现: 用计算器转成十进制后是下面这个值: 然后我就纳闷了,Integer的最小值,不可能怎么大吧? 于是果断写代码验证: 谜底揭开: 0x80000000 是Intege ...
- 网络编程基础之Socket套接字
一.Socket介绍 1.什么是socket? Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口.在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族 ...
- Linux实战教学笔记48:openvpn架构实施方案(一)跨机房异地灾备
第一章VPN介绍 1.1 VPN概述 VPN(全称Virtual Private Network)虚拟专用网络,是依靠ISP和其他的NSP,在公共网络中建立专用的数据通信网络的技术,可以为企业之间或者 ...
- etherboot无盘启动
2001.10.30 吴峰光 本站提供对无盘启动的支持.本文就此作一简单介绍. 一.概述 无盘启动,更确切的说是网络启动,可算是最为轻松和简便的启动方式了. 目前还很少有人了解它,因为目前的软硬件条件 ...
- [模板]KMP字符串匹配
洛谷P3375 注意:两次过程大致相同,故要熟读熟记,切勿搞混 可以看看其他的教程:http://www.cnblogs.com/c-cloud/p/3224788.html 本来就不太熟,若是在记不 ...
- SliceBox
SliceBox相当于一个轮播图插件,只不过是3D的. 先来查看它能实现的效果: 官网:http://tympanus.net/codrops/2011/09/05/slicebox-3d-image ...