【python】-- RabbitMQ 队列消息持久化、消息公平分发
RabbitMQ 队列消息持久化
假如消息队列test里面还有消息等待消费者(consumers)去接收,但是这个时候服务器端宕机了,这个时候消息是否还在?
1、队列消息非持久化
服务端(producer):
import pika # 声明一个socket 实例
connect = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
# 声明一个管道
channel = connect.channel()
# 声明queue名称为test
channel.queue_declare(queue="test") #RabbitMQ的消息永远不会被直接发送到队列中,它总是需要经过一次交换
channel.basic_publish(exchange='',
routing_key="test",
body="hello word") print("Sent 'hello world'") connect.close()
客户端(consumers):
import pika
import time
# 声明socket实例
connect = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
# 声明一个管道 虽然在之前的produce代码中声明过一次管道,
# 但是在不知道produce中的管道是否运行之前(如果未运行,consumers中也不声明的话就会报错),
# 在consumers中也声明一次是一种正确的做法
channel = connect.channel() #声明queue
channel.queue_declare(queue="test") #回调函数
def callback(ch, method, properites, body):
time.sleep(30)
print("-----", ch, method, properites, body)
print("Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag) # 手动确认收到消息,添加手动确认时,no_ack必须为False,不然就会报错 channel.basic_consume(callback,
queue="test",
no_ack=False) print("Waiting for messages")
#这个start只要一启动,就一直运行,它不止收一条,而是永远收下去,没有消息就在这边卡住
channel.start_consuming()
上面的服务端和客户端声明queue的方式都是非持久的
channel.queue_declare(queue="test")
①服务端先发送往test队列里发送两条消息

②通过运行--services.msc进入服务重新启动RabbitMQ
③再次查看消息队列queue中的消息数量

通过小实验可以看出,非持久声明的queue,在服务端宕机后,消息队列queue和消息都不复存在了
2、队列消息持久化:
①队列持久化很简单,只需要在服务端(produce)声明queue的时候添加一个参数:
channel.queue_declare(queue='shuaigaogao', durable=True) # durable=True 持久化
②仅仅持久化队列是没有意义的,还需要多消息进行持久化
channel.basic_publish(exchange="",
routing_key="shuaigaogao", #queue的名字
body="hello world", #body是要发送的内容
properties=pika.BasicProperties(delivery_mode=2,) # make message persistent=>使消息持久化的特性
)
③最后一步,在服务端队列消息都持久化了之后需要在客户端声明queue的时候也持久化
channel.queue_declare(queue='shuaigaogao', durable=True)
这样就算再传递消息过程中,服务端的发生宕机,消息和队列也不会丢失
小结:
- RabbitMQ在服务端没有声明队列和消息持久化时,队列和消息是存在内存中的,服务端宕机了,队列和消息也不会保留。
- 服务端声明持久化,客户端想接受消息的话,必须也要声明queue时,也要声明持久化,不然的话,客户端执行会报错。
RabbitMQ 消息公平分发
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
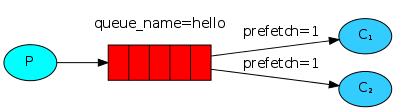
channel.basic_qos(prefetch_count=1)
通俗的讲就是消费者有多大本事,就干多少活,消费者处理的越慢,其消息分配分发的就少,反之消费者消息处理的多,处理的快,就可以多向这个消费者分配一些消息。服务端给客户端发消息的时候,先检查一下,这个消费者现在还有多少消息,如果处理的消息超过1条,就不给这个消费者发送消息了
队列消息持久化+公平分发示列:
服务端:
import pika # 声明一个socket 实例
connect = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
# 声明一个管道
channel = connect.channel()
# 声明queue名称为test
channel.queue_declare(queue="test", durable=True) # 队列持久化 #RabbitMQ的消息永远不会被直接发送到队列中,它总是需要经过一次交换
channel.basic_publish(exchange='',
routing_key="test",
body="hello word",
properties=pika.BasicProperties(delivery_mode=2,)) # 消息持久化 print("Sent 'hello world'") connect.close()
客户端:
import pika
import time
# 声明socket实例
connect = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
# 声明一个管道 虽然在之前的produce代码中声明过一次管道,
# 但是在不知道produce中的管道是否运行之前(如果未运行,consumers中也不声明的话就会报错),
# 在consumers中也声明一次是一种正确的做法
channel = connect.channel() #声明queue
channel.queue_declare(queue="test", durable=True) #回调函数
def callback(ch, method, properites, body):
time.sleep(30)
print("-----", ch, method, properites, body)
print("Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag) # 手动确认收到消息,添加手动确认时,no_ack必须为False,不然就会报错 channel.basic_qos(prefetch_count=1) # 在消息消费之前加上消息处理配置 channel.basic_consume(callback,
queue="test",
no_ack=False) print("Waiting for messages")
#这个start只要一启动,就一直运行,它不止收一条,而是永远收下去,没有消息就在这边卡住
channel.start_consuming()
【python】-- RabbitMQ 队列消息持久化、消息公平分发的更多相关文章
- python RabbitMQ队列使用(入门篇)
---恢复内容开始--- python RabbitMQ队列使用 关于python的queue介绍 关于python的队列,内置的有两种,一种是线程queue,另一种是进程queue,但是这两种que ...
- python RabbitMQ队列使用
python RabbitMQ队列使用 关于python的queue介绍 关于python的队列,内置的有两种,一种是线程queue,另一种是进程queue,但是这两种queue都是只能在同一个进程下 ...
- python RabbitMQ队列/redis
RabbitMQ队列 rabbitMQ是消息队列:想想之前的我们学过队列queue:threading queue(线程queue,多个线程之间进行数据交互).进程queue(父进程与子进程进行交互或 ...
- 持久化和公平分发.py
1.消息持久化在实际应用中,可能会发生消费者收到Queue中的消息,但没有处理完成就宕机(或出现其他意外)的情况,这种情况下就可能会导致消息丢失.为了避免这种情况发生,我们可以要求消费者在消费完消息后 ...
- RabbitMQ队列,Redis\Memcached缓存
RabbitMQ RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统. MQ全称Message Queue,消息队列(MQ)是一种应用程序对应用程序的通信方式.应用程序通过读写出入队列 ...
- RabbitMQ基本用法、消息分发模式、消息持久化、广播模式
RabbitMQ基本用法 进程queue用于同一父进程创建的子进程间的通信 而RabbitMQ可以在不同父进程间通信(例如在word和QQ间通信) 示例代码 生产端(发送) import pika c ...
- 【RabbitMQ学习记录】- 消息队列存储机制源码分析
本文来自 网易云社区 . RabbitMQ在金融系统,OpenStack内部组件通信和通信领域应用广泛,它部署简单,管理界面内容丰富使用十分方便.笔者最近在研究RabbitMQ部署运维和代码架构,本篇 ...
- Day10-Python3基础-协程、异步IO、redis缓存、rabbitMQ队列
内容目录: Gevent协程 Select\Poll\Epoll异步IO与事件驱动 Python连接Mysql数据库操作 RabbitMQ队列 Redis\Memcached缓存 Paramiko S ...
- python---RabbitMQ(1)简单队列使用,消息依次分发(一对一),消息持久化处理
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们.消息传递指的是程序之间 ...
随机推荐
- nyoj 15 括号匹配(2)
括号匹配(二) 时间限制:1000 ms | 内存限制:65535 KB 难度:6 描述 给你一个字符串,里面只包含"(",")","[" ...
- prompt() 方法
定义和用法 prompt() 方法用于显示可提示用户进行输入的对话框. 语法 prompt(text,defaultText) 参数 描述 text 可选.要在对话框中显示的纯文本(而不是 HTML ...
- [转] James A. whittaker:经营成功的测试生涯
James A. whittaker:经营成功的测试生涯 2015-05-13 James Whittaker James Whittaker is an energetic and passiona ...
- Debian8.0 搭建leanote
参考了官方wiki以及中文博客 https://github.com/leanote/leanote/wiki http://leanote.leanote.com/post/Leanote-manu ...
- GPIO 输入—按键检测
这里要用到一定的模电知识.电容两端电压不能突变,电感两端电流不能突变.这里利用了电容的放电延时实现硬件消抖.按键按下会有抖动,波形有毛刺,使得高低电平显现不明显,而按键按下时,电容放电一下,马上又被充 ...
- mysql学习笔记1---mysql ERROR 1045 (28000): 错误解决办法
mysql ERROR 1045 (28000): 错误解决办法 在启动mysql服务后,登陆mysql的窗口的时候,执行mysql命令,结果报错,没法登陆. (在安装mysql和配置的时候,我是 ...
- 解决select菜单边框无法设置的问题
<span style="border:1px solid green; position:absolute; overflow:hidden"><select ...
- 示例 - 如何在ASP.NET中应用Spider Studio生成的DLL?
>> 接前文 "示例 - 如何在Console应用程序中应用SpiderStudio生成的DLL?", 将其运用到ASP.NET中: 1. 创建WebApplicati ...
- Java运行结果测试
- 关于Aspose强大的应用--EXECL
protected void btnConfirg_Click(object sender, EventArgs e) { genExcel(); } //设置内容文字色 表中有一个蓝色文字列和绿色文 ...