Python全栈开发之7、模块和几种常见模块以及format知识补充
一、模块的分类
Python流行的一个原因就是因为它的第三方模块数量巨大,我们编写代码不必从零开始重新造轮子,许多要用的功能都已经写好封装成库了,我们只要直接调用即可,模块分为内建模块、自定义的模块、安装的第三方的模块,一般都放在不同的地方,下面来看一下内建模块怎么导入,以及他们存放的位置。
import sys # 可以用import 直接导入内建模块
for i in sys.path: # sys.path存放有每次导入模块都会去搜寻的路径
print(i)
'''
C:\Users\Tab\AppData\Local\Programs\Python\Python35\python.exe C:/Users/Tab/PycharmProjects/modules/1.py
C:\Users\Tab\PycharmProjects\modules
C:\Users\Tab\PycharmProjects\modules #自定义模块放在当前工作空间
C:\Users\Tab\AppData\Local\Programs\Python\Python35\python35.zip
C:\Users\Tab\AppData\Local\Programs\Python\Python35\DLLs
C:\Users\Tab\AppData\Local\Programs\Python\Python35\lib #内建模块存放位置
C:\Users\Tab\AppData\Local\Programs\Python\Python35
C:\Users\Tab\AppData\Local\Programs\Python\Python35\lib\site-packages #第三方库的安装位置
'''
#可以向sys.path中用append()的方法导入,例如 sys.path.append('D:')后,在D:目录下的py文件可以用import直接导入
print(sys.platform) # win32 sys.platform可以获取当前工作平台(win32)or linux
#此外 sys.argv可以获取脚本的参数,argv[0] 是脚本名,argv[1]是第一个参数...
二、模块的导入
首先要说明下,自己定义的模块的名字和内建模块的名字不要相同,否则的话,导入的时候会出现问题,内建的模块,和第三方模块已经存在sys.path的路径中,所以直接导入即可,下面来说明下自己写了一个项目,项目中的各个库是如何导入的,假设我定义了一个modules的项目,下面是其目录结构看如何在1.py文件导入
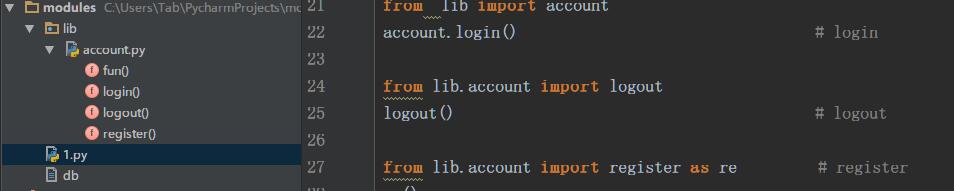
上图左边是目录树,右边是在1.py文件中如何导入在lib/account.py下定义的函数,列举了三种常用导入方式。
三、os模块
os模块是与操作系统相关的模块,比如说对文件和目录的操作,获取路径等,都可以用os模块来实现 ,os模块提供的功能太多,下面来简单的看一下常用用法
import os
print(os.getcwd()) # C:\Users\Tab\PycharmProjects\modules 获取当前工作路径
print(os.environ) # 获取系统环境变量
print(os.getenv('PATH')) # 获取PATH环境变量的值
os.mkdir('test') # 在当前工作空间创建一个test目录
os.remove('path/to/file') # 删除文件
os.rmdir('test') #删除'test'目录
print(os.stat('1.py')) # 返回文件的详细信息 os.stat_result(st_mode=33206 ... st_nlink=1, st_uid=0, st_gid=0, st_size=3152...)
print(os.path.basename(r'C:\Users\Tab\PycharmProjects\modules\1.py')) #获取路径下的文件名 1.py
print(os.path.abspath('1.py')) #获取文件的绝对路径 C:\Users\Tab\PycharmProjects\modules\1.py
print(os.path.dirname(r'C:\Users\Tab\PycharmProjects\modules\1.py')) #获取路径下的路径名
print(os.path.split(r'C:\Users\Tab\PycharmProjects\modules\1.py')) #分割文件和路径
print(os.path.join(r'C:\Users\Tab\PycharmProjects\modules','1.py')) #合并路径
四、hashlib模块
hashlib是一个加密模块,提供了常见的加密算法,比如MD5,SHA1,SHA256等,它通过一个函数,把任意长度的数据转换为一个长度固定的数据串,常用来保存密码等,比如将用户的密码用MD5加密后,保存到数据库,用户登录时先计算用户输入的明文口令的MD5,然后和数据库存储的MD5对比,如果一致,说明密码输入正确,如果不一致,密码肯定错误。下面来看一下用法
import hashlib passwd=hashlib.sha256()
passwd.update(bytes('123456',encoding='utf-8')) # 假设密码是123456 将其转换为字节,传入函数
print(passwd.hexdigest()) # 8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92 passwd=hashlib.sha256(bytes('wxtrkbc',encoding='utf-8')) #对原始密码加一个复杂字符串来提高安全性,俗称“加盐”:
passwd.update(bytes('123456',encoding='utf-8'))
print(passwd.hexdigest()) # d2641b3d7243c87fe3f1312a30fe9909ae80d034f0a799da0897934311ee351b
五、datetime模块
datetime是一个与时间相关的模块,可以处理日期和时间的互换,下面来看一下用法
import datetime print(datetime.datetime.now()) # 2016-05-17 15:46:40.784376 获取当前的日期和时间
print(datetime.datetime.now()+datetime.timedelta(days=10)) # 2016-05-27 15:47:45.702528 将当前的时间向后推迟10天
print(datetime.date.today()) # 2016-05-17 获取当前的日期
print(datetime.datetime.utcnow()) # 2016-05-17 08:23:41.150628 获取格林威治时间 print(datetime.datetime.now().timetuple()) # time.struct_time(tm_year=2016 ... tm_hour=16,...)获取当前一个包含当前时间的结构体
print(datetime.datetime.now().timestamp()) # 1463473711.057878 获取当前的时间戳
print((datetime.datetime.fromtimestamp(1463473711.057878))) # 2016-05-17 16:28:31.057878 将时间戳转换成日期和时间
print(datetime.datetime.strptime('2016-05-17 16:28:31','%Y-%m-%d %H:%M:%S')) #2016-05-17 16:28:31 str转换为datetime
print(datetime.datetime.now().strftime('%D, %m %d %H:%M')) #05/23/16, 05 23 10:10 datetime转换为str
六、Json
如果要在不同的平台间传递信息的话,就可以用到Json模块,比如说,我们要和前端交互的话,数据之间的传递就可以用Json,Json是一种标准格式,能被所有的语言处理。下面来简单的看一下常用的用法,主要是Python常用数据结构比如dict和list与字符串之间的转换,但是tuple不能,tuple是Python里面特有的,而其他语言没有,再者,Json的loads和dumps方法不太常用。
import json
s='{"name":"jason","age":18}' # 外面不能为双引号
l='[1,2,3,4]'
print(json.loads(s)) # 字符串转字典的时候,字符串里面不能为单引号,否则报错 {'name': 'jason', 'age': 18}
print(json.loads(l),type(json.loads(l))) # 字符串转列表 [1, 2, 3, 4] <class 'list'>
user_list=['alex','jason']
print(type(json.dumps(user_list)),json.dumps(user_list)) #列表转字符串 <class 'str'> ["alex", "jason"]
dic = {'k1':1,'k2':2}
json.dump(dic,open('db','w')) # 将字典序列化导入文件
r=json.load(open('db','r')) # 反序列化从文件中导处
print(r,type(r)) # {'k1': 1, 'k2': 2} <class 'dict'>
七、XMl模块
XML也是一种可以实现不同语言之间交换的可扩展标记语言,XMl比Json复杂,虽然没有Json流行,但是在许多场合下也经常用到,所以有必要了解一下,假设我有一个下面这样的XML文件,文件名为1.xml,然后以这个文件我们来对其进行操作
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2026</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
下面我们来用Python来解析一下这个文件,具体的代码看下面
from xml.etree import ElementTree as ET #利用ElementTree.XML将字符串解析成xml对象
node=ET.XML(open('1.xml','r',encoding='utf-8').read()) # 从1.XMl文件中读取内容为字符串,然后用XML解析为一个XML结构体
print(node) # node为根节点 <Element 'data' at 0x000001EFD15C33B8>
for node1 in node: # 获取下一节点 country
print(node1.attrib) # 打印country节点的属性 name
for node2 in node1: # 获取 country下面的所有节点,以及节点的内容
print(node2.tag,node2.text) # 利用ElementTree.parse将文件直接解析成xml对象
tree=ET.parse('1.xml') # 解析成xml对象
root=tree.getroot() # 获取根节点 <Element 'data' at 0x00000202AA8F33B8> for node in root.iter('year'): # 跳过country节点直接获取所有的year节点
print(node.tag,node.text) # 打印year标签和内容 year 2023
node.set('name', 'jason') # 修改year的属性,增加一个name=jsaon的属性
node.set('age', '18')
del node.attrib['age'] # 删除节点属性
node.text='1984' # 修改year的内容为1984 k=root.find('country') # 找到country
k1=root.find('country').find('rank') # find要一级级的找,找到第一个country下的rank
k.remove(k1) # 删除第一个country下的rank节点
tree.write('1.xml') # 修改完成后只有写入文件中才算有效
八、logging
logging,是用来纪录日志的模块,可以自动帮我们纪录程序运行中出现的错误,出了问题可以方便我们后来去日志中查找原因,在实际开发中非常好用,下面来简单的看一下用法。
import logging logging.basicConfig(filename='log.log', # 事件记录的文件名
format='%(asctime)s-%(name)s-%(levelname)s-%(module)s: %(message)s', #事件纪录格式
datefmt='%Y-%m-%d %H:%M:%S %p', # 时间格式
level=10,)
logging.error('error') # 2016-05-25 19:46:39 PM-root-ERROR-url: error # 同时写到多个文件的方式
file_1=logging.FileHandler('1.log','a')
fmt=logging.Formatter(fmt='%(asctime)s-%(name)s-%(levelname)s-%(module)s: %(message)s',datefmt='%Y-%m-%d %H:%M:%S %p')
file_1.setFormatter(fmt) file_2=logging.FileHandler('2.log','a')
fmt=logging.Formatter()
file_2.setFormatter(fmt) log=logging.Logger('1',level=logging.ERROR)
log.addHandler(file_1)
log.addHandler(file_2) # 2016-05-28 22:16:40 PM-1-CRITICAL-url: 33333 (1.log)
# 33333 (2.log)
log.critical('33333')
九、 format
以前我们都是用百分号格式化字符串,现在我们用一种更牛逼的方式来格式化字符串format,下面来看一下format的常规用法。
print("1 am {},age {}".format('jason',18)) # 用{}当作占位符
print("1 am {},age {}".format(*['jason',18])) # 用*传递一个列表进去
print("1 am {0},age {1},score{1}".format('jason',18)) # 1 am jason,age 18,score18 用 0,1等数字来应用
print("1 am {name},age {age}".format(name='jason',age=18)) # 用key引用,传递键值对
print("1 am {name},age {age}".format(**{'name':'jason','age':18})) # 用**传递一个字典
print("1 am {0[0]},age {1[1]}".format([1,2,3],[4,5,6])) # 1 am 1,age 5
print("i am {:s}, age {:d}".format(*["jason", 18])) # 还可用指定整形
print("i am {:.2%}".format(0.2)) # i am 20.00%
十、练习
1、写一个用户的登陆注册的界面,用户的密码用hashlib加密存在文件中,登陆时候,用户的密码要和文件中的密码一致才行
def sha(password): #加密函数
passwd = hashlib.sha256(bytes('wxtrkbc', encoding='utf-8'))
passwd.update(bytes(password,encoding='utf-8'))
return passwd.hexdigest() def register(user,passwd): #注册函数,并将密码加密后存在文件中
with open('db','a') as f :
f.write(user+':'+sha(passwd)) def login(user,passwd): #登陆函数 并判断登陆密码是否正确
with open('db','r',encoding='utf-8')as f :
for line in f :
info=line.strip().split(':')
if user==info[0] and sha(passwd)==info[1]: # 将密码加密后与文件中存储的进行对比,一样就是相同的用户
print('login success')
return True
else:
print('login error')
return False def main():
k=input('1注册,2登陆')
if int(k)==1:
user=input('输入用户名:')
passwd=input('输入密码:')
register(user,passwd)
elif int(k)==2:
user = input('输入用户名:')
passwd = input('输入密码:')
login(user,passwd)
else:
return
2、写一个进度条,用百分比显示进度
import os,sys,time
for i in range(101):
sys.stdout.write('\r%s %s%%' % ('#'*int(i/100*100),int(i/100*100)))
sys.stdout.flush()
# s+='#'
# print('%s %s%%' %(s,int(i/50*100)))
time.sleep(0.2)
# for i in range(101): #改进一下
# #显示进度条百分比 #号从1开始 空格从99递减
# hashes = '#' * int(i / 100.0 * 100)
# spaces = ' ' * (100 - len(hashes))
# sys.stdout.write("\r[%s] %d%%" % (hashes + spaces, i))
# sys.stdout.flush()
# time.sleep(0.05)
3、利用微信接口来判断某一QQ号的状态
import requests
from xml.etree import ElementTree as ET
response = requests.get('http://www.webxml.com.cn//webservices/qqOnlineWebService.asmx/qqCheckOnline?qqCode=5768476386')
r = response.text
node = ET.XML(r)
if node.text == 'Y':
print('在线')
elif node.text == 'V':
print('隐身')
else:
print('离线')
4、利用微信接口来获取列车时刻表
import requests
from xml.etree import ElementTree as ET
response=requests.get('http://www.webxml.com.cn/WebServices/TrainTimeWebService.asmx/getDetailInfoByTrainCode?TrainCode=K234&UserID=')
r=response.text
root=ET.XML(r)
for node in root.iter('TrainDetailInfo'):
print(node.find('TrainStation').text,node.find('ArriveTime').text)
Python全栈开发之7、模块和几种常见模块以及format知识补充的更多相关文章
- Python全栈开发之18、cookies、session和ajax等相关知识
一.cookies 本质为在浏览器端保存的键值对,由服务端写在浏览器端,以后每次请求的时候,浏览器都携带着cookie来访问,cookies的使用之处非常多,比如用户验证,登陆界面,右侧菜单隐藏,控制 ...
- python全栈开发之OS模块的总结
OS模块 1. os.name() 获取当前的系统 2.os.getcwd #获取当前的工作目录 import os cwd=os.getcwd() # dir=os.listdi ...
- 战争热诚的python全栈开发之路
从学习python开始,一直是自己摸索,但是时间不等人啊,所以自己为了节省时间,决定报个班系统学习,下面整理的文章都是自己学习后,认为重要的需要弄懂的知识点,做出链接,一方面是为了自己找的话方便,一方 ...
- Python全栈开发之5、模块
一.模块 1.import导入模块 #1.定义 模块:用来从逻辑上组织python代码(变量,函数,类,逻辑),本质就是.py结尾的python文件,实现一个功能 包:python package 用 ...
- Python全栈开发之MySQL(二)------navicate和python操作MySQL
一:Navicate的安装 1.什么是navicate? Navicat是一套快速.可靠并价格相宜的数据库管理工具,专为简化数据库的管理及降低系统管理成本而设.它的设计符合数据库管理员.开发人员及中小 ...
- Python全栈开发之14、Javascript
一.简介 前面我们学习了html和css,但是我们写的网页不能动起来,如果我们需要网页出现各种效果,那么我们就要学习一门新的语言了,那就是JavaScript,JavaScript是世界上最流行的脚本 ...
- Python全栈开发之1、输入输出与流程控制
Python简介 python是吉多·范罗苏姆发明的一种面向对象的脚本语言,可能有些人不知道面向对象和脚本具体是什么意思,但是对于一个初学者来说,现在并不需要明白.大家都知道,当下全栈工程师的概念很火 ...
- python全栈开发之路
一.Python基础 python简介 python数据类型(数字\字符串\列表) python数据类型(元组\字典) python数据类型(集合) python占位符%s,%d,%r,%f prin ...
- Python全栈开发之7、面向对象编程进阶-类属性和方法、异常处理和反射
一.类的属性 1.@property属性 作用就是通过@property把一个方法变成一个静态属性 class Room: def __init__(self,name,length,width,he ...
- Python全栈开发之2、运算符与基本数据结构
运算符 一.算数元算: 读者可以跟着我按照下面的代码重新写一遍,其中需要注意的是,使用除的话,在python3中可以直接使用,结果是4没有任何问题,但是在python2中使用的话,则不行,比如 9/2 ...
随机推荐
- HDU 6199 DP
gems gems gems Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
- Linux常用网络工具:hping高级主机扫描
之前介绍了主机扫描工具fping,可以参考我写的<Linux常用网络工具:fping主机扫描>. hping是一款更高级的主机扫描工具,它支持TCP/IP数据包构造.分析,在某些防火墙配置 ...
- 数学:A^B的约数(因子)之和对MOD取模
POJ1845 首先把A写成唯一分解定理的形式 分解时让A对所有质数从小到大取模就好了 然后就有:A = p1^k1 * p2^k2 * p3^k3 *...* pn^kn 然后有: A^B = p1 ...
- HDU 3926 并查集 图同构简单判断 STL
给出两个图,问你是不是同构的... 直接通过并查集建图,暴力用SET判断下子节点个数就行了. /** @Date : 2017-09-22 16:13:42 * @FileName: HDU 3926 ...
- web开发之Servlet 三
昨天我们学习了Servlet的运行过程和生命周期,那么今天我们学习下Servlet中非常重要的两个类:ServletConfig ServletContext 我们可以看到,与顶层Servlet主动 ...
- python 天气爬虫
python3 爬取全国天气信息 制作一个天气查询软件,能够查询全国范围内的天气数据. github:https://github.com/1052687889/weatherApp 基于PyQt5编 ...
- React Native DEMO for Android
Demo1: 主要知识:navigator,fecth 地址:https://github.com/hongguangKim/ReactNativeDEMO1 Demo2: 主要知识:navigato ...
- javascript中的数组去重
1.方法一:双层循环,外层循环元素,内层循环做比较,若相同则跳过,不同则加入结果集中,获取没重复的最右侧的值放入数组中 Array.prototype.distinct = function(){ v ...
- 33、求按从小到大的顺序的第N个丑数
一.题目 把只包含因子2.3和5的数称作丑数(Ugly Number).例如6.8都是丑数,但14不是,因为它包含因子7. 习惯上我们把1当做是第一个丑数.求按从小到大的顺序的第N个丑数. 二.解法 ...
- Python3 断言
#!/usr/bin/env python # _*_ coding:utf-8 _*_ # Author:CarsonLi ''' 断言一般用于后面有非常重要的操作,需要使用前面的数据,而且不容许出 ...