Hbase的安装与测试
实验环境
虚拟机伪分布式
Ubuntu 17.10
JDK 1.8
Hadoop 2.7.6
Hbase 1.3.3
①安装和配置HBase。
首先从官网http://archive.apache.org/dist/hbase/下载HBase安装包,为了兼容性,这里选择HBase-1.3.3。然后解压到文件夹。
②配置环境变量
将hbase下的bin目录添加到path中
编辑~/.bashrc文件添加 export PATH=$PATH:bin路径
③伪分布式模式配置
配置hbase/conf/hbase-env.sh

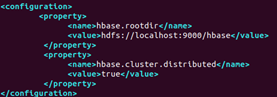
配置hbase/conf/hbase-site.xml
假设当前Hadoop集群运行在伪分布式模式下,在本机上运行,且NameNode运行在9000端口。
④启动Hadoop

启动Hbase

⑤根据表格,用Hbase Shell命令模式设计student学生表格。
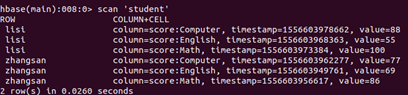
⑥查询zhangsan 的Computer成绩。

⑦修改lisi的Math成绩,改为95。

⑧根据上面的student表,用Hbase Java API编程
新建一个工程,将hbase/lib中的所有jar包添加到项目
a) 添加数据:English:45 Math:89 Computer:100
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table; public class Hbase {
public static Configuration configuration;
public static Connection connection;
public static Admin admin; public static void main(String[] args) {
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir", "hdfs://localhost:9000/hbase");
try {
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
try {
insertRow("student", "scofield", "score", "English", "45");
insertRow("student", "scofield", "score", "Math", "89");
insertRow("student", "scofield", "score", "Computer", "100");
} catch (IOException e) {
e.printStackTrace();
}
close();
} public static void insertRow(String tableName, String rowKey, String colFamily, String col, String val)
throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(rowKey.getBytes());
put.addColumn(colFamily.getBytes(), col.getBytes(), val.getBytes());
table.put(put);
table.close();
} public static void close() {
try {
if (admin != null) {
admin.close();
}
if (null != connection) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Hbase添加数据
b) 获取scofield的English成绩信息
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Table; public class GetScofieid {
public static Configuration configuration;
public static Connection connection;
public static Admin admin; public static void main(String[] args) {
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir", "hdfs://localhost:9000/hbase");
try {
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
getData("student", "scofield", "score", "English");
} catch (IOException e) {
e.printStackTrace();
}
close();
} public static void getData(String tableName, String rowKey, String colFamily, String col) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(rowKey.getBytes());
get.addColumn(colFamily.getBytes(), col.getBytes());
Result result = table.get(get);
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.println("RowName:" + new String(CellUtil.cloneRow(cell)));
System.out.println("timestamp:" + cell.getTimestamp());
System.out.println("column Family:" + new String(CellUtil.cloneFamily(cell)));
System.out.println("row Name:" + new String(CellUtil.cloneQualifier(cell)));
System.out.println("value:" + new String(CellUtil.cloneValue(cell)));
}
table.close();
} public static void close() {
try {
if (admin != null) {
admin.close();
}
if (null != connection) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Hbase获取数据
⑨关闭所有服务
Hbase的安装与测试的更多相关文章
- Hbase的安装测试工作
Hbase的安装测试工作: 安装:http://www.cnblogs.com/neverwinter/archive/2013/03/28/2985798.html 测试:http://www.cn ...
- hadoop2-HBase的安装和测试
在安装和测试HBase之前,我们有必要先了解一下HBase是什么 我们可以通过下面的资料对其有一定的了解: HBase 官方文档中文版 HBase 深入浅出 我想把我知道的分享给大家,方便大家交流. ...
- hbase单机版安装+phoneix SQL on hbase 单节点安装
hbase 单机安装部署及phoneix 单机安装 Hbase 下载 (需先配置jdk) https://www.apache.org/dyn/closer.lua/hbase/2.0.1/hbase ...
- hbase单机版安装
hbase单机版安装 1. hbase单机版安装 HBase的安装也有三种模式:单机模式.伪分布模式和完全分布式模式. hbase依赖于Hadoop和Zookeeper. 这里安装的是单机版 ...
- my SQL下载安装,环境配置,以及密码忘记的解决,以及navicat for mysql下载,安装,测试连接
一.下载 在百度上搜索"mysql-5.6.24-winx64下载" 二.安装 选择安装路径,我的路径“C:\Soft\mysql-5.6.24-winx64” 三.环境配置 计算 ...
- OpenCV2+入门系列(一):OpenCV2.4.9的安装与测试
这里假设看到这篇文章的人都已经对OpenCV以及机器视觉等最基础的概念有了一定的认识,因此本文不会对OpenCV做任何的介绍,而是直接介绍OpenCV2.4.9的安装与测试.此外本文只是简单的介绍如何 ...
- 决战大数据之三-Apache ZooKeeper Standalone及复制模式安装及测试
决战大数据之三-Apache ZooKeeper Standalone及复制模式安装及测试 [TOC] Apache ZooKeeper 单机模式安装 创建hadoop用户&赋予sudo权限, ...
- Hadoop、Zookeeper、Hbase分布式安装教程
参考: Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0 Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS ZooKeeper-3.3 ...
- coreseek实战(一):windows下coreseek的安装与测试
coreseek实战(一):windows下coreseek的安装与测试 网上关于 coreseek 在 windows 下安装与使用的教程有很多,官方也有详细的教程,这里我也只是按着官方提供的教程详 ...
随机推荐
- 手动为 Team Foundation Server 安装 SQL Server
本主题中的步骤适用于安装 SQL Server 2012 企业版,你也可以使用安装标准版的相同步骤. 适用于 SQL 2014 的步骤与以上步骤也非常相似. 我们将在 TFS 所在的同一服务器上安装 ...
- flask 数据迁移
python flasky.py shell db.create_all() from app.models import User mhc = User("mhc") >& ...
- 如何显示当前Mipmap级别?
[如何显示当前Mipmap级别?] 乘以 mainTextureSize/mipTextureSize是为了让mipColorsTexture纹理与mainTexture级别对应.直接用uv是不行的, ...
- linux fg&bg
[linux fg&bg] Linux 提供了 fg 和 bg 命令,让我们调度正在运行的任务. 假设你发现前台运行的一个程序需要很长的时间,但是需要干其他的事情,你就可以用 Ctrl-Z , ...
- JAVA 定时器的三种方法
/** * 普通thread * 这是最常见的,创建一个thread,然后让它在while循环里一直运行着, * 通过sleep方法来达到定时任务的效果.这样可以快速简单的实现,代码如下: * @au ...
- http协议简析(一)
HTTP:hype-text transfer protocol,超文本传输协议,超文本(html)在网络间(电脑与电脑之间)传输过程中所遵循的一些规则. 两台电脑之间要实现数据传输的条件 1.两台电 ...
- 相机IMU融合四部曲(一):D-LG-EKF详细解读
相机IMU融合四部曲(一):D-LG-EKF详细解读 极品巧克力 前言 前两篇文章<Google Cardbord的九轴融合算法>,<Madgwick算法详细解读>,讨论的都是 ...
- Boost智能指针使用总结
内存管理是一个比较繁琐的问题,C++中有两个实现方案: 垃圾回收机制和智能指针.垃圾回收机制因为性能等原因不被C++的大佬们推崇, 而智能指针被认为是解决C++内存问题的最优方案. 1. 智能指针定义 ...
- code1744 方格染色
稍微复杂一点的划分dp 设f[i][j][k]为第i行前j个k次粉刷正确的最大值 由于每行循环使用,可以去掉第一维,但每次不要忘了清零(卡了好久) f[j][k]=max{ f[u][j-1] + m ...
- [转]Python-__builtin__与__builtins__的区别与关系(超详细,经典)
在学习Python时,很多人会问到__builtin__.__builtins__和builtins之间有什么关系.百度或Google一下,有很 多答案,但是这些答案要么不准确,要么只说了一点点,并不 ...