python实现一个层次聚类方法
层次聚类(Hierarchical Clustering)
一.概念
层次聚类不需要指定聚类的数目,首先它是将数据中的每个实例看作一个类,然后将最相似的两个类合并,该过程迭代计算只到剩下一个类为止,类由两个子类构成,每个子类又由更小的两个子类构成。如下图所示:
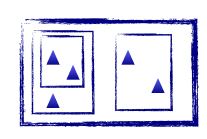
二.合并方法
在聚类中每次迭代都将两个最近的类进行合并,这个类间的距离计算方法常用的有三种:
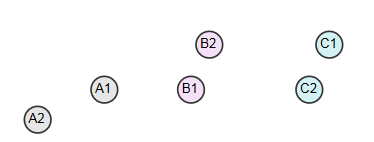
1.单连接聚类(Single-linkage clustering)
在单连接聚类中,两个类间的距离定义为一个类的所有实例到另一个类的所有实例之间最短的那个距离。如上图中类A(A1,A2),B(B1,B2),C(C1,C2),A类和B类间的最短距离是A1到B1,所以A类与B类更近,所有A和B合并。
2.全连接聚类(Complete-linkage clustering)
在全连接聚类中,两个类间的距离定义为一个类的所有实例到另一个类的所有实例之间最长的那个距离。图中A类和B类间最长距离是A2到B2,B类和C类最长距离是B1到C1,distance(B1-C1)<distance(A2-B2),所以B类和C类合并在一起。
3.平均连接聚类(Average-linkage clustering)
在平均连接聚类中,类间的距离为一个类的所有实例到另一个类的所有实例的平均距离。
三.python实现(单连接)
#!/usr/bin/python
# -*- coding: utf-8 -*- from queue import PriorityQueue
import math
import codecs """
层次聚类
"""
class HCluster: #一列的中位数
def getMedian(self,alist):
tmp = list(alist)
tmp.sort()
alen = len(tmp)
if alen % 2 == 1:
return tmp[alen // 2]
else:
return (tmp[alen // 2] + tmp[(alen // 2) - 1]) / 2 #对数值型数据进行归一化,使用绝对标准分[绝对标准差->asd=sum(x-u)/len(x),x的标准分->(x-u)/绝对标准差,u是中位数]
def normalize(self,column):
median = self.getMedian(column)
asd = sum([abs(x - median) for x in column]) / len(column)
result = [(x - median) / asd for x in column]
return result def __init__(self,filepath):
self.data={}
self.counter=0
self.queue=PriorityQueue()
line_1=True#开头第一行
with codecs.open(filepath,'r','utf-8') as f:
for line in f:
#第一行为描述信息
if line_1:
line_1=False
header=line.split(',')
self.cols=len(header)
self.data=[[] for i in range(self.cols)]
else:
instances=line.split(',')
toggle=0
for instance in range(self.cols):
if toggle==0:
self.data[instance].append(instances[instance])
toggle=1
else:
self.data[instance].append(float(instances[instance]))
#归一化数值列
for i in range(1,self.cols):
self.data[i]=self.normalize(self.data[i]) #欧氏距离计算元素i到所有其它元素的距离,放到邻居字典中,比如i=1,j=2...,结构如i=1的邻居-》{2: ((1,2), 1.23), 3: ((1, 3), 2.3)... }
#找到最近邻
#基于最近邻将元素放到优先队列中
#data[0]放的是label标签,data[1]和data[2]是数值型属性
rows=len(self.data[0])
for i in range(rows):
minDistance=10000
nearestNeighbor=0
neighbors={}
for j in range(rows):
if i!=j:
dist=self.distance(i,j)
if i<j:
pair=(i,j)
else:
pair=(j,i)
neighbors[j]=(pair,dist)
if dist<minDistance:
minDistance=dist
nearestNeighbor=j
#创建最近邻对
if i<nearestNeighbor:
nearestPair=(i,nearestNeighbor)
else:
nearestPair=(nearestNeighbor,i)
#放入优先对列中,(最近邻距离,counter,[label标签名,最近邻元组,所有邻居])
self.queue.put((minDistance,self.counter,[[self.data[0][i]],nearestPair,neighbors]))
self.counter+=1 #欧氏距离,d(x,y)=math.sqrt(sum((x-y)*(x-y)))
def distance(self,i,j):
sumSquares=0
for k in range(1,self.cols):
sumSquares+=(self.data[k][i]-self.data[k][j])**2
return math.sqrt(sumSquares) #聚类
def cluster(self):
done=False
while not done:
topOne=self.queue.get()
nearestPair=topOne[2][1]
if not self.queue.empty():
nextOne=self.queue.get()
nearPair=nextOne[2][1]
tmp=[]
#nextOne是否是topOne的最近邻,如不是继续找
while nearPair!=nearestPair:
tmp.append((nextOne[0],self.counter,nextOne[2]))
self.counter+=1
nextOne=self.queue.get()
nearPair=nextOne[2][1]
#重新加回Pop出的不相等最近邻的元素
for item in tmp:
self.queue.put(item) if len(topOne[2][0])==1:
item1=topOne[2][0][0]
else:
item1=topOne[2][0]
if len(nextOne[2][0])==1:
item2=nextOne[2][0][0]
else:
item2=nextOne[2][0]
#联合两个最近邻族成一个新族
curCluster=(item1,item2)
#下面使用单连接方法建立新族中的邻居距离元素,一:计算上面新族的最近邻。二:建立新的邻居。如果 item1和item3距离是2,item2和item3距离是4,则在新族中的距离是2
minDistance=10000
nearestPair=()
nearestNeighbor=''
merged={}
nNeighbors=nextOne[2][2]
for key,value in topOne[2][2].items():
if key in nNeighbors:
if nNeighbors[key][1]<value[1]:
dist=nNeighbors[key]
else:
dist=value
if dist[1]<minDistance:
minDistance=dist[1]
nearestPair=dist[0]
nearestNeighbor=key
merged[key]=dist
if merged=={}:
return curCluster
else:
self.queue.put((minDistance,self.counter,[curCluster,nearestPair,merged]))
self.counter+=1 if __name__=='__main__':
hcluser=HCluster('filePath')
cluser=hcluser.cluster()
print(cluser)
参考:1.machine.learning.an.algorithmic.perspective.2nd.edition.
2.a programmer's guide to data mining
python实现一个层次聚类方法的更多相关文章
- Python机器学习——Agglomerative层次聚类
层次聚类(hierarchical clustering)可在不同层次上对数据集进行划分,形成树状的聚类结构.AggregativeClustering是一种常用的层次聚类算法. 其原理是:最初将 ...
- 挑子学习笔记:BIRCH层次聚类
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/6129425.html 本文是“挑子”在学习BIRCH算法过程中的笔记摘录,文中不乏一些个人理解,不当之处望 ...
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 常见聚类算法——K均值、凝聚层次聚类和DBSCAN比较
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- python类:magic魔术方法
http://blog.csdn.net/pipisorry/article/details/50708812 魔术方法是面向对象Python语言中的一切.它们是你可以自定义并添加"魔法&q ...
- (转)python类:magic魔术方法
原文:https://blog.csdn.net/pipisorry/article/details/50708812 版权声明:本文为博主皮皮http://blog.csdn.net/pipisor ...
- 【python】利用scipy进行层次聚类
参考博客: https://joernhees.de/blog/2015/08/26/scipy-hierarchical-clustering-and-dendrogram-tutorial/ 层次 ...
- 送你一个Python 数据排序的好方法
摘要:学习 Pandas排序方法是开始或练习使用 Python进行基本数据分析的好方法.最常见的数据分析是使用电子表格.SQL或pandas 完成的.使用 Pandas 的一大优点是它可以处理大量数据 ...
- 【Python机器学习实战】聚类算法(2)——层次聚类(HAC)和DBSCAN
层次聚类和DBSCAN 前面说到K-means聚类算法,K-Means聚类是一种分散性聚类算法,本节主要是基于数据结构的聚类算法--层次聚类和基于密度的聚类算法--DBSCAN两种算法. 1.层次聚类 ...
随机推荐
- Oracle临时表的功能与应用
什么是临时表,用户做一个操作查询出几百几千条数据,我们可以把数据放在内存中.当有很多用户都这样做,内存空间不足,这个时候就需要把数据保存在磁盘上.对于 oracle 就提供了一种临时表用于存放这些数据 ...
- 【模板】SPFA(不完全详解)
一种最短路求法(个人觉得比DIJKSTRA好用) 用于有向图. 大概思路:从根节点开始,枚举每一个点,同时更新他们所联通的点的最短路径,如果路径被更新,则把这个点入队,一直重复这个操作直到队伍为空为止 ...
- 第k小团(Bitset+bfs)牛客第二场 -- Kth Minimum Clique
题意: 给你n个点的权值和连边的信息,问你第k小团的值是多少. 思路: 用bitset存信息,暴力跑一下就行了,因为满足树形结构,所以bfs+优先队列就ok了,其中记录下最后进入的点(以免重复跑). ...
- MateBook 换内存条
欢迎关注微信公众号:猫的尾巴有墨水 为啥要拆MateBook D笔记本? 最近这个Windows 10更新后,内存暴增,每次禁用windows update和同步服务模块后,依然不能彻底解决内存爆炸的 ...
- 如何用纯 CSS 创作一个晃动的公告板
效果预览 在线演示 按下右侧的"点击预览"按钮可以在当前页面预览,点击链接可以全屏预览. https://codepen.io/comehope/pen/wjZoGV 可交互视频教 ...
- 记Tomcat进程stop卡住问题定位处理
部分内容参考自CSDN 测试环境通过agent注入了部分代码,其中包括几个Timer. 在通过启动脚本重启tomcat时,会一直有一个stop进程卡住,导致tomcat无法正常重启,进程卡住不动. 通 ...
- 关于tomcat部署项目的问题
问题是这样的 之前用tomcat8.5部署的项目,结果启动项目一直三个端口被占用,浏览器也打不开目标网页 卸了8,装了9.先配置的一大堆,结果可以打开Tomcat的主页locahost:8080,到此 ...
- 第七篇 CSS盒子
CSS盒子模型 在页面上,我们要控制元素的位置,比如:写作文一样,开头的两个字会空两个格子(这是在学校语文作文一样),其后就不会空出来,还有,一段文字后面跟着一张图,它们距离太近,不好看,我们要移 ...
- Centos7下安装ZooKeeper
1.下载源码 zookeeper 需要jdk的支持,需要先安装jdk 官网下载地址: http://mirrors.hust.edu.cn/apache/zookeeper/ 选择最新的版本进行下载 ...
- Cypress自动化测试系列之二
本文技术难度★★★,如果前编内容顺利执行,请继续. 如果Selenium尚无法灵活运用的读者,本文可能难度较大. “理论联系实惠,密切联系领导,表扬和自我表扬”——我就是老司机,曾经写文章教各位怎么打 ...