sklearn学习一
转发说明:by majunman from HIT email:2192483210@qq.com
简介:scikit-learn是数据挖掘和数据分析的有效工具,它建立在 NumPy, SciPy, and matplotlib基础上。开源的但商业不允许
1. Supervised learning
1.1. Generalized Linear Models
1.1.1. Ordinary Least Squares最小二乘法
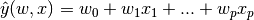
>>> from sklearn import linear_model
>>> reg = linear_model.LinearRegression()
>>> reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
>>> reg.coef_
array([ 0.5, 0.5])
reg-http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html#sklearn.linear_model.LinearRegression
reg.coef_ 是回归函数的结果,即相关系数
具体实验:
print(__doc__) # Code source: Jaques Grobler
# License: BSD 3 clause import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score # Load the diabetes dataset
diabetes = datasets.load_diabetes() #加载diabetes数据集(sklearn提供的几种数据集之一,该数据是糖尿病数据集) # Use only one feature
diabetes_X = diabetes.data[:, np.newaxis, 2] #只加载一个特征值 # Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:] # Split the targets into training/testing sets
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:] # Create linear regression object
regr = linear_model.LinearRegression() # Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train) # Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test) # The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(diabetes_y_test, diabetes_y_pred))
# Explained variance score: 1 is perfect prediction
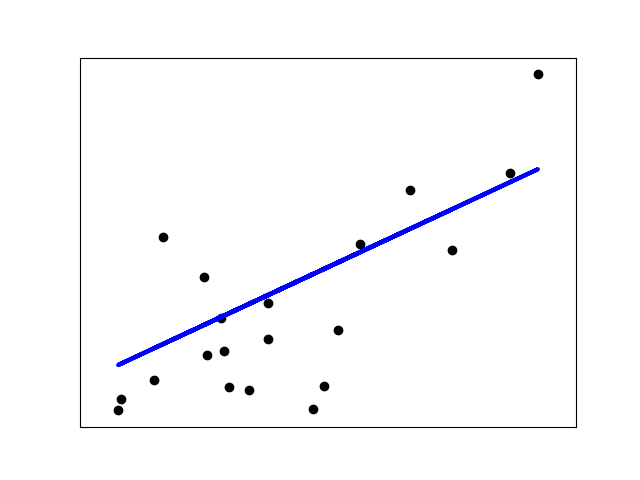
print('Variance score: %.2f' % r2_score(diabetes_y_test, diabetes_y_pred)) # Plot outputs
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3) plt.xticks(())
plt.yticks(()) plt.show()
sklearn学习一的更多相关文章
- sklearn学习笔记之简单线性回归
简单线性回归 线性回归是数据挖掘中的基础算法之一,从某种意义上来说,在学习函数的时候已经开始接触线性回归了,只不过那时候并没有涉及到误差项.线性回归的思想其实就是解一组方程,得到回归函数,不过在出现误 ...
- sklearn学习总结(超全面)
https://blog.csdn.net/fuqiuai/article/details/79495865 前言sklearn想必不用我多介绍了,一句话,她是机器学习领域中最知名的python模块之 ...
- sklearn学习 第一篇:knn分类
K临近分类是一种监督式的分类方法,首先根据已标记的数据对模型进行训练,然后根据模型对新的数据点进行预测,预测新数据点的标签(label),也就是该数据所属的分类. 一,kNN算法的逻辑 kNN算法的核 ...
- sklearn 学习 第一篇:分类
分类属于监督学习算法,是指根据已有的数据和标签(分类)进行学习,预测未知数据的标签.分类问题的目标是预测数据的类别标签(class label),可以把分类问题划分为二分类和多分类问题.二分类是指在两 ...
- SKlearn | 学习总结
1 简介 scikit-learn,又写作sklearn,是一个开源的基于python语言的机器学习工具包.它通过NumPy, SciPy和Matplotlib等python数值计算的库实现高效的算法 ...
- sklearn学习笔记3
Explaining Titanic hypothesis with decision trees decision trees are very simple yet powerful superv ...
- sklearn学习笔记2
Text classifcation with Naïve Bayes In this section we will try to classify newsgroup messages using ...
- sklearn学习笔记1
Image recognition with Support Vector Machines #our dataset is provided within scikit-learn #let's s ...
- 莫烦sklearn学习自修第九天【过拟合问题处理】
1. 过拟合问题可以通过调整机器学习的参数来完成,比如sklearn中通过调节gamma参数,将训练损失和测试损失降到最低 2. 代码实现(显示gamma参数对训练损失和测试损失的影响) from _ ...
- 莫烦sklearn学习自修第八天【过拟合问题】
1. 什么是过拟合问题 所谓过拟合问题指的是使用训练样本进行训练时100%正确分类或规划,当使用测试样本时则不能正确分类和规划 2. 代码实战(模拟过拟合问题) from __future__ imp ...
随机推荐
- java文件操作解析
转载:http://blog.csdn.net/cynhafa/article/details/6882061 字节流与和字符流的使用非常相似,两者除了操作代码上的不同之外,是否还有其他的不同呢? 实 ...
- 【转贴】GS464/GS464E
GS464/GS464E GS464为四发射64位结构,采用动态流水线.其1.0版本(简称GS464)为9级流水线结构,在龙芯3A.3B.2H中使用.其2.0版本(简称GS464E)为12级动态流水线 ...
- 【Python】【基础知识】【内置函数】【input的使用方法】
原英文帮助文档: input([prompt]) If the prompt argument is present, it is written to standard output without ...
- (5.8)mysql高可用系列——MySQL中的GTID复制(实践篇)
一.基于GTID的异步复制(一主一从)无数据/少数据搭建 二.基于GTID的无损半同步复制(一主一从)(mysql5.7)基于大数据量的初始化 正文: [0]概念 [0.5]GTID 复制(mysql ...
- 【计算机网络】-介质访问控制子层-无线LAN
[计算机网络]-介质访问控制子层-无线LAN 802.11体系结构和协议栈 802.11网络使用模式: 有架构模式(Infrastructure mode) 无线客户端连接接入点AP,叫做有架构模式 ...
- CodeFoeces GYM 101466A Gaby And Addition (字典树)
gym 101466A Gaby And Addition 题目分析 题意: 给出n个数,找任意两个数 “相加”,求这个结果的最大值和最小值,注意此处的加法为不进位加法. 思路: 由于给出的数最多有 ...
- 剑指offer-数组中重复的数字-数组-python
题目描述 在一个长度为n的数组里的所有数字都在0到n-1的范围内. 数组中某些数字是重复的,但不知道有几个数字是重复的.也不知道每个数字重复几次.请找出数组中任意一个重复的数字. 例如,如果输入长度为 ...
- Intel Coleto Creek SSL chipset
Intel Coleto Creek SSL chipset name type interface speed model SR-IOV driver Intel SSL chipset Colet ...
- CentOS下安装DockerCE
title: CentOS下安装DockerCE comments: false date: 2019-09-04 09:47:58 description: 在CentOS下安装社区版Docker ...
- java中怎么跳出两层for循环
使用标号(使用标号跳出两层或者多层for循环): outterLoop: for (int i = 0; i < 9; i++){ for (int j = 0; j & ...